 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActWorld: From Explorable to Interactive World Model via Action-Aware Memory
Jun 16, 2026Interactive world models aim to simulate environment dynamics under real-time user actions. However, their action vocabulary is largely confined to navigation: most actions correspond to motion (e.g., walk, turn, look around), while interaction with objects in the scene (e.g., pick up plates, open doors, or trigger physical responses) is either absent, restricted to game domains, or relegated to prompt-to-full-video scenarios. The resulting worlds are visually explorable but not truly actionable. In this work, we present ActWorld, an interactive world model that extends prior navigation-centric generators to support mid-rollout object interaction within a chunk-autoregressive framework. We argue that the navigation-interaction gap stems from two bottlenecks. First, a data bottleneck: the lack of human-object interaction data with accurate, dense labels. Second, a memory bottleneck: recency-biased history compression in existing world models discards the event-transition frames that causally determine subsequent object states, leading to an action-forgetting pathology. On the data side, we construct a 100K interaction video dataset, each annotated with per-chunk captions via chain-of-thought reasoning. On the model side, we introduce a hierarchical action-aware memory design that routes history compression by interaction importance, complemented by a persistent memory bank that maintains event-update and object-identity tokens across long rollouts. Experiments show that ActWorld supports both flexible navigation and rich object interaction within a single model, substantially improving interaction fidelity over navigation-only baselines without sacrificing viewpoint control. Project page is available at https://interactwm.github.io/ActWorld.
HECTOR: Hybrid Editable Compositional Object References for Video Generation
Mar 09, 2026Real-world videos naturally portray complex interactions among distinct physical objects, effectively forming dynamic compositions of visual elements. However, most current video generation models synthesize scenes holistically and therefore lack mechanisms for explicit compositional manipulation. To address this limitation, we propose HECTOR, a generative pipeline that enables fine-grained compositional control. In contrast to prior methods,HECTOR supports hybrid reference conditioning, allowing generation to be simultaneously guided by static images and/or dynamic videos. Moreover, users can explicitly specify the trajectory of each referenced element, precisely controlling its location, scale, and speed (see Figure1). This design allows the model to synthesize coherent videos that satisfy complex spatiotemporal constraints while preserving high-fidelity adherence to references. Extensive experiments demonstrate that HECTOR achieves superior visual quality, stronger reference preservation, and improved motion controllability compared with existing approaches.
FSVideo: Fast Speed Video Diffusion Model in a Highly-Compressed Latent Space
Feb 02, 2026We introduce FSVideo, a fast speed transformer-based image-to-video (I2V) diffusion framework. We build our framework on the following key components: 1.) a new video autoencoder with highly-compressed latent space ($64\times64\times4$ spatial-temporal downsampling ratio), achieving competitive reconstruction quality; 2.) a diffusion transformer (DIT) architecture with a new layer memory design to enhance inter-layer information flow and context reuse within DIT, and 3.) a multi-resolution generation strategy via a few-step DIT upsampler to increase video fidelity. Our final model, which contains a 14B DIT base model and a 14B DIT upsampler, achieves competitive performance against other popular open-source models, while being an order of magnitude faster. We discuss our model design as well as training strategies in this report.
Envision: Embodied Visual Planning via Goal-Imagery Video Diffusion
Dec 27, 2025Embodied visual planning aims to enable manipulation tasks by imagining how a scene evolves toward a desired goal and using the imagined trajectories to guide actions. Video diffusion models, through their image-to-video generation capability, provide a promising foundation for such visual imagination. However, existing approaches are largely forward predictive, generating trajectories conditioned on the initial observation without explicit goal modeling, thus often leading to spatial drift and goal misalignment. To address these challenges, we propose Envision, a diffusion-based framework that performs visual planning for embodied agents. By explicitly constraining the generation with a goal image, our method enforces physical plausibility and goal consistency throughout the generated trajectory. Specifically, Envision operates in two stages. First, a Goal Imagery Model identifies task-relevant regions, performs region-aware cross attention between the scene and the instruction, and synthesizes a coherent goal image that captures the desired outcome. Then, an Env-Goal Video Model, built upon a first-and-last-frame-conditioned video diffusion model (FL2V), interpolates between the initial observation and the goal image, producing smooth and physically plausible video trajectories that connect the start and goal states. Experiments on object manipulation and image editing benchmarks demonstrate that Envision achieves superior goal alignment, spatial consistency, and object preservation compared to baselines. The resulting visual plans can directly support downstream robotic planning and control, providing reliable guidance for embodied agents.
StoryMem: Multi-shot Long Video Storytelling with Memory
Dec 22, 2025
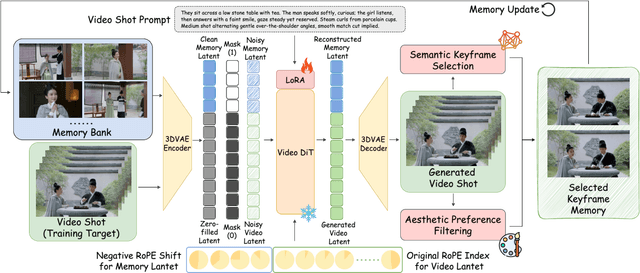

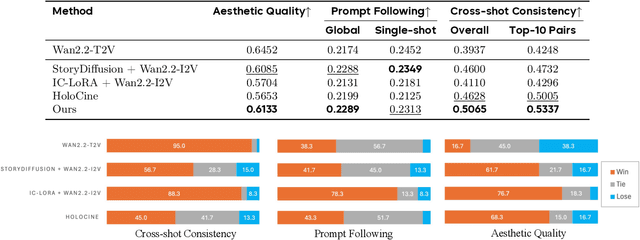
Visual storytelling requires generating multi-shot videos with cinematic quality and long-range consistency. Inspired by human memory, we propose StoryMem, a paradigm that reformulates long-form video storytelling as iterative shot synthesis conditioned on explicit visual memory, transforming pre-trained single-shot video diffusion models into multi-shot storytellers. This is achieved by a novel Memory-to-Video (M2V) design, which maintains a compact and dynamically updated memory bank of keyframes from historical generated shots. The stored memory is then injected into single-shot video diffusion models via latent concatenation and negative RoPE shifts with only LoRA fine-tuning. A semantic keyframe selection strategy, together with aesthetic preference filtering, further ensures informative and stable memory throughout generation. Moreover, the proposed framework naturally accommodates smooth shot transitions and customized story generation applications. To facilitate evaluation, we introduce ST-Bench, a diverse benchmark for multi-shot video storytelling. Extensive experiments demonstrate that StoryMem achieves superior cross-shot consistency over previous methods while preserving high aesthetic quality and prompt adherence, marking a significant step toward coherent minute-long video storytelling.
VIVA: VLM-Guided Instruction-Based Video Editing with Reward Optimization
Dec 18, 2025



Instruction-based video editing aims to modify an input video according to a natural-language instruction while preserving content fidelity and temporal coherence. However, existing diffusion-based approaches are often trained on paired data of simple editing operations, which fundamentally limits their ability to generalize to diverse and complex, real-world instructions. To address this generalization gap, we propose VIVA, a scalable framework for instruction-based video editing that leverages VLM-guided encoding and reward optimization. First, we introduce a VLM-based instructor that encodes the textual instruction, the first frame of the source video, and an optional reference image into visually-grounded instruction representations, providing fine-grained spatial and semantic context for the diffusion transformer backbone. Second, we propose a post-training stage, Edit-GRPO, which adapts Group Relative Policy Optimization to the domain of video editing, directly optimizing the model for instruction-faithful, content-preserving, and aesthetically pleasing edits using relative rewards. Furthermore, we propose a data construction pipeline designed to synthetically generate diverse, high-fidelity paired video-instruction data of basic editing operations. Extensive experiments show that VIVA achieves superior instruction following, generalization, and editing quality over state-of-the-art methods. Website: https://viva-paper.github.io
MAGREF: Masked Guidance for Any-Reference Video Generation
May 29, 2025Video generation has made substantial strides with the emergence of deep generative models, especially diffusion-based approaches. However, video generation based on multiple reference subjects still faces significant challenges in maintaining multi-subject consistency and ensuring high generation quality. In this paper, we propose MAGREF, a unified framework for any-reference video generation that introduces masked guidance to enable coherent multi-subject video synthesis conditioned on diverse reference images and a textual prompt. Specifically, we propose (1) a region-aware dynamic masking mechanism that enables a single model to flexibly handle various subject inference, including humans, objects, and backgrounds, without architectural changes, and (2) a pixel-wise channel concatenation mechanism that operates on the channel dimension to better preserve appearance features. Our model delivers state-of-the-art video generation quality, generalizing from single-subject training to complex multi-subject scenarios with coherent synthesis and precise control over individual subjects, outperforming existing open-source and commercial baselines. To facilitate evaluation, we also introduce a comprehensive multi-subject video benchmark. Extensive experiments demonstrate the effectiveness of our approach, paving the way for scalable, controllable, and high-fidelity multi-subject video synthesis. Code and model can be found at: https://github.com/MAGREF-Video/MAGREF
ATI: Any Trajectory Instruction for Controllable Video Generation
May 28, 2025We propose a unified framework for motion control in video generation that seamlessly integrates camera movement, object-level translation, and fine-grained local motion using trajectory-based inputs. In contrast to prior methods that address these motion types through separate modules or task-specific designs, our approach offers a cohesive solution by projecting user-defined trajectories into the latent space of pre-trained image-to-video generation models via a lightweight motion injector. Users can specify keypoints and their motion paths to control localized deformations, entire object motion, virtual camera dynamics, or combinations of these. The injected trajectory signals guide the generative process to produce temporally consistent and semantically aligned motion sequences. Our framework demonstrates superior performance across multiple video motion control tasks, including stylized motion effects (e.g., motion brushes), dynamic viewpoint changes, and precise local motion manipulation. Experiments show that our method provides significantly better controllability and visual quality compared to prior approaches and commercial solutions, while remaining broadly compatible with various state-of-the-art video generation backbones. Project page: https://anytraj.github.io/.
PartInstruct: Part-level Instruction Following for Fine-grained Robot Manipulation
May 27, 2025Fine-grained robot manipulation, such as lifting and rotating a bottle to display the label on the cap, requires robust reasoning about object parts and their relationships with intended tasks. Despite recent advances in training general-purpose robot manipulation policies guided by language instructions, there is a notable lack of large-scale datasets for fine-grained manipulation tasks with part-level instructions and diverse 3D object instances annotated with part-level labels. In this work, we introduce PartInstruct, the first large-scale benchmark for training and evaluating fine-grained robot manipulation models using part-level instructions. PartInstruct comprises 513 object instances across 14 categories, each annotated with part-level information, and 1302 fine-grained manipulation tasks organized into 16 task classes. Our training set consists of over 10,000 expert demonstrations synthesized in a 3D simulator, where each demonstration is paired with a high-level task instruction, a chain of base part-based skill instructions, and ground-truth 3D information about the object and its parts. Additionally, we designed a comprehensive test suite to evaluate the generalizability of learned policies across new states, objects, and tasks. We evaluated several state-of-the-art robot manipulation approaches, including end-to-end vision-language policy learning and bi-level planning models for robot manipulation on our benchmark. The experimental results reveal that current models struggle to robustly ground part concepts and predict actions in 3D space, and face challenges when manipulating object parts in long-horizon tasks.
CINEMA: Coherent Multi-Subject Video Generation via MLLM-Based Guidance
Mar 13, 2025Video generation has witnessed remarkable progress with the advent of deep generative models, particularly diffusion models. While existing methods excel in generating high-quality videos from text prompts or single images, personalized multi-subject video generation remains a largely unexplored challenge. This task involves synthesizing videos that incorporate multiple distinct subjects, each defined by separate reference images, while ensuring temporal and spatial consistency. Current approaches primarily rely on mapping subject images to keywords in text prompts, which introduces ambiguity and limits their ability to model subject relationships effectively. In this paper, we propose CINEMA, a novel framework for coherent multi-subject video generation by leveraging Multimodal Large Language Model (MLLM). Our approach eliminates the need for explicit correspondences between subject images and text entities, mitigating ambiguity and reducing annotation effort. By leveraging MLLM to interpret subject relationships, our method facilitates scalability, enabling the use of large and diverse datasets for training. Furthermore, our framework can be conditioned on varying numbers of subjects, offering greater flexibility in personalized content creation. Through extensive evaluations, we demonstrate that our approach significantly improves subject consistency, and overall video coherence, paving the way for advanced applications in storytelling, interactive media, and personalized video generation.