 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNautilus: From One Prompt to Plug-and-Play Robot Learning
May 12, 2026Robot learning research is fragmented across policy families, benchmark suites, and real robots; each implementation is entangled with the others in a complex combination matrix, making it an engineering nightmare to port any single element. General-purpose coding agents may occasionally bridge specific setups, but cannot close this gap at scale because they lack the procedural priors and validation practices that characterize robotics research workflows. We propose NAUTILUS, an open-source harness that turns a single user prompt -- for example, "Evaluate policy A with benchmark B" -- into ready-to-use reproduction, evaluation, fine-tuning, and deployment workflows. NAUTILUS provides: plug-and-play agent skill sets with distilled priors from robotics research; typed contracts among policies, simulators/benchmarks, and real-world robots; unified interfaces and execution environments; and a trustworthy agentic coding workflow with explicit, automated validation, and testing at each milestone. NAUTILUS can not only automatically generate the required adapters and containers for existing implementations, but also wrap and onboard new or user-provided policies, simulators/benchmarks, and robots, all connected via a uniform interface. This expands cross-validation coverage without hand-written glue code. Like a nautilus shell that grows by adding chambers, NAUTILUS scales by extending its execution in chambered units, making it a research harness for scalability rather than a hand-curated framework, and aiming to reduce the engineering burden of cross-family reproduction and evaluation in the ever-growing robot learning ecosystem.
ZOPP: A Framework of Zero-shot Offboard Panoptic Perception for Autonomous Driving
Nov 08, 2024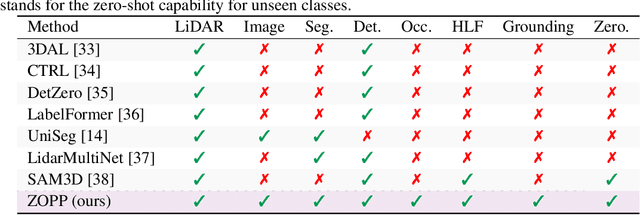
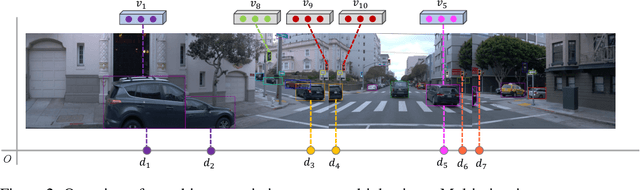


Offboard perception aims to automatically generate high-quality 3D labels for autonomous driving (AD) scenes. Existing offboard methods focus on 3D object detection with closed-set taxonomy and fail to match human-level recognition capability on the rapidly evolving perception tasks. Due to heavy reliance on human labels and the prevalence of data imbalance and sparsity, a unified framework for offboard auto-labeling various elements in AD scenes that meets the distinct needs of perception tasks is not being fully explored. In this paper, we propose a novel multi-modal Zero-shot Offboard Panoptic Perception (ZOPP) framework for autonomous driving scenes. ZOPP integrates the powerful zero-shot recognition capabilities of vision foundation models and 3D representations derived from point clouds. To the best of our knowledge, ZOPP represents a pioneering effort in the domain of multi-modal panoptic perception and auto labeling for autonomous driving scenes. We conduct comprehensive empirical studies and evaluations on Waymo open dataset to validate the proposed ZOPP on various perception tasks. To further explore the usability and extensibility of our proposed ZOPP, we also conduct experiments in downstream applications. The results further demonstrate the great potential of our ZOPP for real-world scenarios.
Dual3D: Efficient and Consistent Text-to-3D Generation with Dual-mode Multi-view Latent Diffusion
May 16, 2024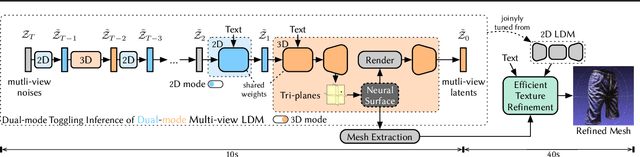



We present Dual3D, a novel text-to-3D generation framework that generates high-quality 3D assets from texts in only $1$ minute.The key component is a dual-mode multi-view latent diffusion model. Given the noisy multi-view latents, the 2D mode can efficiently denoise them with a single latent denoising network, while the 3D mode can generate a tri-plane neural surface for consistent rendering-based denoising. Most modules for both modes are tuned from a pre-trained text-to-image latent diffusion model to circumvent the expensive cost of training from scratch. To overcome the high rendering cost during inference, we propose the dual-mode toggling inference strategy to use only $1/10$ denoising steps with 3D mode, successfully generating a 3D asset in just $10$ seconds without sacrificing quality. The texture of the 3D asset can be further enhanced by our efficient texture refinement process in a short time. Extensive experiments demonstrate that our method delivers state-of-the-art performance while significantly reducing generation time. Our project page is available at https://dual3d.github.io
Semantic Flow: Learning Semantic Field of Dynamic Scenes from Monocular Videos
Apr 08, 2024In this work, we pioneer Semantic Flow, a neural semantic representation of dynamic scenes from monocular videos. In contrast to previous NeRF methods that reconstruct dynamic scenes from the colors and volume densities of individual points, Semantic Flow learns semantics from continuous flows that contain rich 3D motion information. As there is 2D-to-3D ambiguity problem in the viewing direction when extracting 3D flow features from 2D video frames, we consider the volume densities as opacity priors that describe the contributions of flow features to the semantics on the frames. More specifically, we first learn a flow network to predict flows in the dynamic scene, and propose a flow feature aggregation module to extract flow features from video frames. Then, we propose a flow attention module to extract motion information from flow features, which is followed by a semantic network to output semantic logits of flows. We integrate the logits with volume densities in the viewing direction to supervise the flow features with semantic labels on video frames. Experimental results show that our model is able to learn from multiple dynamic scenes and supports a series of new tasks such as instance-level scene editing, semantic completions, dynamic scene tracking and semantic adaption on novel scenes. Codes are available at https://github.com/tianfr/Semantic-Flow/.
OASim: an Open and Adaptive Simulator based on Neural Rendering for Autonomous Driving
Feb 06, 2024With deep learning and computer vision technology development, autonomous driving provides new solutions to improve traffic safety and efficiency. The importance of building high-quality datasets is self-evident, especially with the rise of end-to-end autonomous driving algorithms in recent years. Data plays a core role in the algorithm closed-loop system. However, collecting real-world data is expensive, time-consuming, and unsafe. With the development of implicit rendering technology and in-depth research on using generative models to produce data at scale, we propose OASim, an open and adaptive simulator and autonomous driving data generator based on implicit neural rendering. It has the following characteristics: (1) High-quality scene reconstruction through neural implicit surface reconstruction technology. (2) Trajectory editing of the ego vehicle and participating vehicles. (3) Rich vehicle model library that can be freely selected and inserted into the scene. (4) Rich sensors model library where you can select specified sensors to generate data. (5) A highly customizable data generation system can generate data according to user needs. We demonstrate the high quality and fidelity of the generated data through perception performance evaluation on the Carla simulator and real-world data acquisition. Code is available at https://github.com/PJLab-ADG/OASim.
Towards Knowledge-driven Autonomous Driving
Dec 12, 2023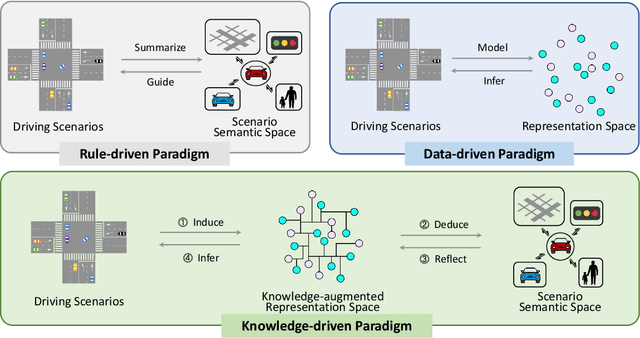
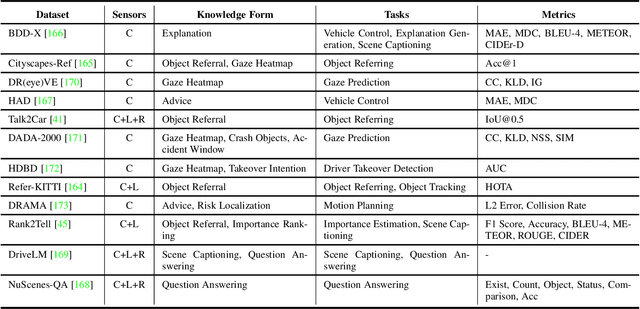
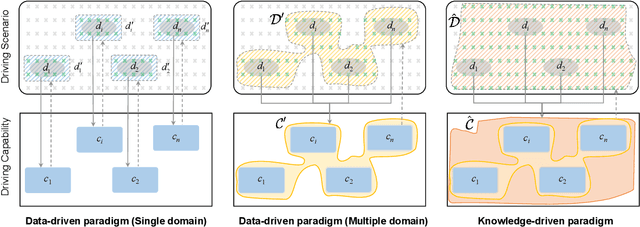
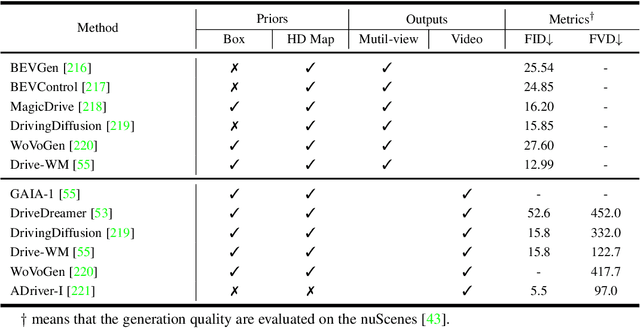
This paper explores the emerging knowledge-driven autonomous driving technologies. Our investigation highlights the limitations of current autonomous driving systems, in particular their sensitivity to data bias, difficulty in handling long-tail scenarios, and lack of interpretability. Conversely, knowledge-driven methods with the abilities of cognition, generalization and life-long learning emerge as a promising way to overcome these challenges. This paper delves into the essence of knowledge-driven autonomous driving and examines its core components: dataset \& benchmark, environment, and driver agent. By leveraging large language models, world models, neural rendering, and other advanced artificial intelligence techniques, these components collectively contribute to a more holistic, adaptive, and intelligent autonomous driving system. The paper systematically organizes and reviews previous research efforts in this area, and provides insights and guidance for future research and practical applications of autonomous driving. We will continually share the latest updates on cutting-edge developments in knowledge-driven autonomous driving along with the relevant valuable open-source resources at: \url{https://github.com/PJLab-ADG/awesome-knowledge-driven-AD}.
ReSimAD: Zero-Shot 3D Domain Transfer for Autonomous Driving with Source Reconstruction and Target Simulation
Sep 25, 2023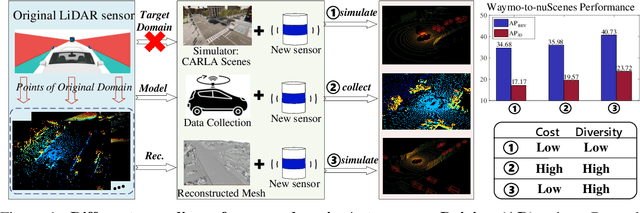
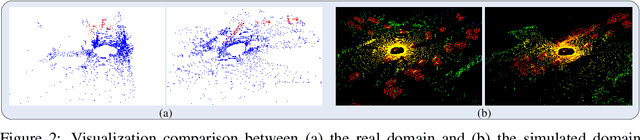

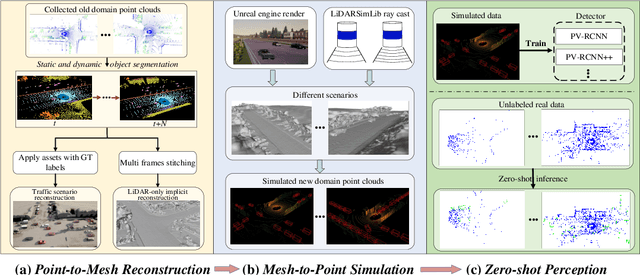
Domain shifts such as sensor type changes and geographical situation variations are prevalent in Autonomous Driving (AD), which poses a challenge since AD model relying on the previous-domain knowledge can be hardly directly deployed to a new domain without additional costs. In this paper, we provide a new perspective and approach of alleviating the domain shifts, by proposing a Reconstruction-Simulation-Perception (ReSimAD) scheme. Specifically, the implicit reconstruction process is based on the knowledge from the previous old domain, aiming to convert the domain-related knowledge into domain-invariant representations, e.g., 3D scene-level meshes. Besides, the point clouds simulation process of multiple new domains is conditioned on the above reconstructed 3D meshes, where the target-domain-like simulation samples can be obtained, thus reducing the cost of collecting and annotating new-domain data for the subsequent perception process. For experiments, we consider different cross-domain situations such as Waymo-to-KITTI, Waymo-to-nuScenes, Waymo-to-ONCE, etc, to verify the zero-shot target-domain perception using ReSimAD. Results demonstrate that our method is beneficial to boost the domain generalization ability, even promising for 3D pre-training.
Parse and Recall: Towards Accurate Lung Nodule Malignancy Prediction like Radiologists
Jul 20, 2023



Lung cancer is a leading cause of death worldwide and early screening is critical for improving survival outcomes. In clinical practice, the contextual structure of nodules and the accumulated experience of radiologists are the two core elements related to the accuracy of identification of benign and malignant nodules. Contextual information provides comprehensive information about nodules such as location, shape, and peripheral vessels, and experienced radiologists can search for clues from previous cases as a reference to enrich the basis of decision-making. In this paper, we propose a radiologist-inspired method to simulate the diagnostic process of radiologists, which is composed of context parsing and prototype recalling modules. The context parsing module first segments the context structure of nodules and then aggregates contextual information for a more comprehensive understanding of the nodule. The prototype recalling module utilizes prototype-based learning to condense previously learned cases as prototypes for comparative analysis, which is updated online in a momentum way during training. Building on the two modules, our method leverages both the intrinsic characteristics of the nodules and the external knowledge accumulated from other nodules to achieve a sound diagnosis. To meet the needs of both low-dose and noncontrast screening, we collect a large-scale dataset of 12,852 and 4,029 nodules from low-dose and noncontrast CTs respectively, each with pathology- or follow-up-confirmed labels. Experiments on several datasets demonstrate that our method achieves advanced screening performance on both low-dose and noncontrast scenarios.
StreetSurf: Extending Multi-view Implicit Surface Reconstruction to Street Views
Jun 08, 2023



We present a novel multi-view implicit surface reconstruction technique, termed StreetSurf, that is readily applicable to street view images in widely-used autonomous driving datasets, such as Waymo-perception sequences, without necessarily requiring LiDAR data. As neural rendering research expands rapidly, its integration into street views has started to draw interests. Existing approaches on street views either mainly focus on novel view synthesis with little exploration of the scene geometry, or rely heavily on dense LiDAR data when investigating reconstruction. Neither of them investigates multi-view implicit surface reconstruction, especially under settings without LiDAR data. Our method extends prior object-centric neural surface reconstruction techniques to address the unique challenges posed by the unbounded street views that are captured with non-object-centric, long and narrow camera trajectories. We delimit the unbounded space into three parts, close-range, distant-view and sky, with aligned cuboid boundaries, and adapt cuboid/hyper-cuboid hash-grids along with road-surface initialization scheme for finer and disentangled representation. To further address the geometric errors arising from textureless regions and insufficient viewing angles, we adopt geometric priors that are estimated using general purpose monocular models. Coupled with our implementation of efficient and fine-grained multi-stage ray marching strategy, we achieve state of the art reconstruction quality in both geometry and appearance within only one to two hours of training time with a single RTX3090 GPU for each street view sequence. Furthermore, we demonstrate that the reconstructed implicit surfaces have rich potential for various downstream tasks, including ray tracing and LiDAR simulation.
ReVoLT: Relational Reasoning and Voronoi Local Graph Planning for Target-driven Navigation
Jan 10, 2023Embodied AI is an inevitable trend that emphasizes the interaction between intelligent entities and the real world, with broad applications in Robotics, especially target-driven navigation. This task requires the robot to find an object of a certain category efficiently in an unknown domestic environment. Recent works focus on exploiting layout relationships by graph neural networks (GNNs). However, most of them obtain robot actions directly from observations in an end-to-end manner via an incomplete relation graph, which is not interpretable and reliable. We decouple this task and propose ReVoLT, a hierarchical framework: (a) an object detection visual front-end, (b) a high-level reasoner (infers semantic sub-goals), (c) an intermediate-level planner (computes geometrical positions), and (d) a low-level controller (executes actions). ReVoLT operates with a multi-layer semantic-spatial topological graph. The reasoner uses multiform structured relations as priors, which are obtained from combinatorial relation extraction networks composed of unsupervised GraphSAGE, GCN, and GraphRNN-based Region Rollout. The reasoner performs with Upper Confidence Bound for Tree (UCT) to infer semantic sub-goals, accounting for trade-offs between exploitation (depth-first searching) and exploration (regretting). The lightweight intermediate-level planner generates instantaneous spatial sub-goal locations via an online constructed Voronoi local graph. The simulation experiments demonstrate that our framework achieves better performance in the target-driven navigation tasks and generalizes well, which has an 80% improvement compared to the existing state-of-the-art method. The code and result video will be released at https://ventusff.github.io/ReVoLT-website/.