 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZOPP: A Framework of Zero-shot Offboard Panoptic Perception for Autonomous Driving
Paper and Code
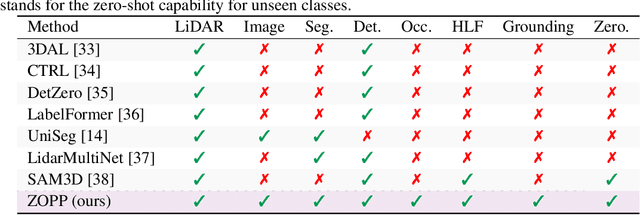


Offboard perception aims to automatically generate high-quality 3D labels for autonomous driving (AD) scenes. Existing offboard methods focus on 3D object detection with closed-set taxonomy and fail to match human-level recognition capability on the rapidly evolving perception tasks. Due to heavy reliance on human labels and the prevalence of data imbalance and sparsity, a unified framework for offboard auto-labeling various elements in AD scenes that meets the distinct needs of perception tasks is not being fully explored. In this paper, we propose a novel multi-modal Zero-shot Offboard Panoptic Perception (ZOPP) framework for autonomous driving scenes. ZOPP integrates the powerful zero-shot recognition capabilities of vision foundation models and 3D representations derived from point clouds. To the best of our knowledge, ZOPP represents a pioneering effort in the domain of multi-modal panoptic perception and auto labeling for autonomous driving scenes. We conduct comprehensive empirical studies and evaluations on Waymo open dataset to validate the proposed ZOPP on various perception tasks. To further explore the usability and extensibility of our proposed ZOPP, we also conduct experiments in downstream applications. The results further demonstrate the great potential of our ZOPP for real-world scenarios.