 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Static Context to Calibrated Interactive RL: Mitigating Distribution Shift in Multi-turn Dialogue with Aligned Simulator
May 26, 2026A long-standing goal of the research community is to develop highly interactive LLM-based dialogue agents. Recent research focuses on optimizing policies based on fixed offline logs (Static Context RL) or using a prompt-based simulator (Interactive RL). In this work, we theoretically show that both paradigms are fundamentally limited by context distribution shift--a mismatch between dialogue histories observed during training and those encountered in real conversations. This shift compounds quadratically over turns and severely degrades dialogue quality. Specifically, we attribute this shift to two distinct sources: (i) policy-induced shift, arising from training on static histories rather than self-generated trajectories; and (ii) simulator-induced shift, stemming from discrepancies between simulated and real human behaviors. To address these challenges, we propose Calibrated Interactive RL, a unified framework that couples interactive RL with simulator alignment. By aligning the simulator with human interaction patterns, our approach reduces the sim-to-real gap and mitigates compounding distribution shifts. Experiments across multiple dialogue tasks confirm our theoretical analysis: (i) Interactive RL significantly outperforms the Static Context baseline by mitigating policy distribution shift; and (ii) calibrating simulators with our alignment method further bridges the sim-to-real gap, yielding state-of-the-art downstream performance.
MLG-Stereo: ViT Based Stereo Matching with Multi-Stage Local-Global Enhancement
Apr 22, 2026With the development of deep learning, ViT-based stereo matching methods have made significant progress due to their remarkable robustness and zero-shot ability. However, due to the limitations of ViTs in handling resolution sensitivity and their relative neglect of local information, the ability of ViT-based methods to predict details and handle arbitrary-resolution images is still weaker than that of CNN-based methods. To address these shortcomings, we propose MLG-Stereo, a systematic pipeline-level design that extends global modeling beyond the encoder stage. First, we propose a Multi-Granularity Feature Network to effectively balance global context and local geometric information, enabling comprehensive feature extraction from images of arbitrary resolution and bridging the gap between training and inference scales. Then, a Local-Global Cost Volume is constructed to capture both locally-correlated and global-aware matching information. Finally, a Local-Global Guided Recurrent Unit is introduced to iteratively optimize the disparity locally under the guidance of global information. Extensive experiments are conducted on multiple benchmark datasets, demonstrating that our MLG-Stereo exhibits highly competitive performance on the Middlebury and KITTI-2015 benchmarks compared to contemporaneous leading methods, and achieves outstanding results in the KITTI-2012 dataset.
Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
Apr 15, 2026Reinforcement Learning from Human Feedback (RLHF) and related alignment paradigms have become central to steering large language models (LLMs) and multimodal large language models (MLLMs) toward human-preferred behaviors. However, these approaches introduce a systemic vulnerability: reward hacking, where models exploit imperfections in learned reward signals to maximize proxy objectives without fulfilling true task intent. As models scale and optimization intensifies, such exploitation manifests as verbosity bias, sycophancy, hallucinated justification, benchmark overfitting, and, in multimodal settings, perception--reasoning decoupling and evaluator manipulation. Recent evidence further suggests that seemingly benign shortcut behaviors can generalize into broader forms of misalignment, including deception and strategic gaming of oversight mechanisms. In this survey, we propose the Proxy Compression Hypothesis (PCH) as a unifying framework for understanding reward hacking. We formalize reward hacking as an emergent consequence of optimizing expressive policies against compressed reward representations of high-dimensional human objectives. Under this view, reward hacking arises from the interaction of objective compression, optimization amplification, and evaluator--policy co-adaptation. This perspective unifies empirical phenomena across RLHF, RLAIF, and RLVR regimes, and explains how local shortcut learning can generalize into broader forms of misalignment, including deception and strategic manipulation of oversight mechanisms. We further organize detection and mitigation strategies according to how they intervene on compression, amplification, or co-adaptation dynamics. By framing reward hacking as a structural instability of proxy-based alignment under scale, we highlight open challenges in scalable oversight, multimodal grounding, and agentic autonomy.
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
InternAgent-1.5: A Unified Agentic Framework for Long-Horizon Autonomous Scientific Discovery
Feb 09, 2026We introduce InternAgent-1.5, a unified system designed for end-to-end scientific discovery across computational and empirical domains. The system is built on a structured architecture composed of three coordinated subsystems for generation, verification, and evolution. These subsystems are supported by foundational capabilities for deep research, solution optimization, and long horizon memory. The architecture allows InternAgent-1.5 to operate continuously across extended discovery cycles while maintaining coherent and improving behavior. It also enables the system to coordinate computational modeling and laboratory experimentation within a single unified system. We evaluate InternAgent-1.5 on scientific reasoning benchmarks such as GAIA, HLE, GPQA, and FrontierScience, and the system achieves leading performance that demonstrates strong foundational capabilities. Beyond these benchmarks, we further assess two categories of discovery tasks. In algorithm discovery tasks, InternAgent-1.5 autonomously designs competitive methods for core machine learning problems. In empirical discovery tasks, it executes complete computational or wet lab experiments and produces scientific findings in earth, life, biological, and physical domains. Overall, these results show that InternAgent-1.5 provides a general and scalable framework for autonomous scientific discovery.
LSTM-MAS: A Long Short-Term Memory Inspired Multi-Agent System for Long-Context Understanding
Jan 17, 2026Effectively processing long contexts remains a fundamental yet unsolved challenge for large language models (LLMs). Existing single-LLM-based methods primarily reduce the context window or optimize the attention mechanism, but they often encounter additional computational costs or constrained expanded context length. While multi-agent-based frameworks can mitigate these limitations, they remain susceptible to the accumulation of errors and the propagation of hallucinations. In this work, we draw inspiration from the Long Short-Term Memory (LSTM) architecture to design a Multi-Agent System called LSTM-MAS, emulating LSTM's hierarchical information flow and gated memory mechanisms for long-context understanding. Specifically, LSTM-MAS organizes agents in a chained architecture, where each node comprises a worker agent for segment-level comprehension, a filter agent for redundancy reduction, a judge agent for continuous error detection, and a manager agent for globally regulates information propagation and retention, analogous to LSTM and its input gate, forget gate, constant error carousel unit, and output gate. These novel designs enable controlled information transfer and selective long-term dependency modeling across textual segments, which can effectively avoid error accumulation and hallucination propagation. We conducted an extensive evaluation of our method. Compared with the previous best multi-agent approach, CoA, our model achieves improvements of 40.93%, 43.70%,121.57% and 33.12%, on NarrativeQA, Qasper, HotpotQA, and MuSiQue, respectively.
Controllable Memory Usage: Balancing Anchoring and Innovation in Long-Term Human-Agent Interaction
Jan 08, 2026As LLM-based agents are increasingly used in long-term interactions, cumulative memory is critical for enabling personalization and maintaining stylistic consistency. However, most existing systems adopt an ``all-or-nothing'' approach to memory usage: incorporating all relevant past information can lead to \textit{Memory Anchoring}, where the agent is trapped by past interactions, while excluding memory entirely results in under-utilization and the loss of important interaction history. We show that an agent's reliance on memory can be modeled as an explicit and user-controllable dimension. We first introduce a behavioral metric of memory dependence to quantify the influence of past interactions on current outputs. We then propose \textbf{Stee}rable \textbf{M}emory Agent, \texttt{SteeM}, a framework that allows users to dynamically regulate memory reliance, ranging from a fresh-start mode that promotes innovation to a high-fidelity mode that closely follows interaction history. Experiments across different scenarios demonstrate that our approach consistently outperforms conventional prompting and rigid memory masking strategies, yielding a more nuanced and effective control for personalized human-agent collaboration.
SciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Dec 30, 2025We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
MME-Reasoning: A Comprehensive Benchmark for Logical Reasoning in MLLMs
May 27, 2025Logical reasoning is a fundamental aspect of human intelligence and an essential capability for multimodal large language models (MLLMs). Despite the significant advancement in multimodal reasoning, existing benchmarks fail to comprehensively evaluate their reasoning abilities due to the lack of explicit categorization for logical reasoning types and an unclear understanding of reasoning. To address these issues, we introduce MME-Reasoning, a comprehensive benchmark designed to evaluate the reasoning ability of MLLMs, which covers all three types of reasoning (i.e., inductive, deductive, and abductive) in its questions. We carefully curate the data to ensure that each question effectively evaluates reasoning ability rather than perceptual skills or knowledge breadth, and extend the evaluation protocols to cover the evaluation of diverse questions. Our evaluation reveals substantial limitations of state-of-the-art MLLMs when subjected to holistic assessments of logical reasoning capabilities. Even the most advanced MLLMs show limited performance in comprehensive logical reasoning, with notable performance imbalances across reasoning types. In addition, we conducted an in-depth analysis of approaches such as ``thinking mode'' and Rule-based RL, which are commonly believed to enhance reasoning abilities. These findings highlight the critical limitations and performance imbalances of current MLLMs in diverse logical reasoning scenarios, providing comprehensive and systematic insights into the understanding and evaluation of reasoning capabilities.
NovelSeek: When Agent Becomes the Scientist -- Building Closed-Loop System from Hypothesis to Verification
May 22, 2025
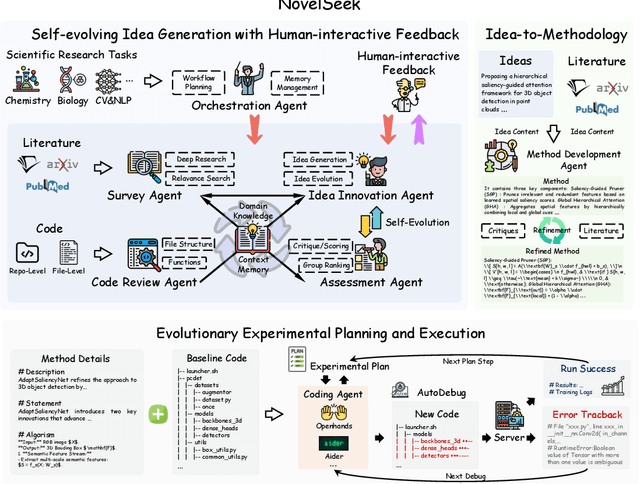

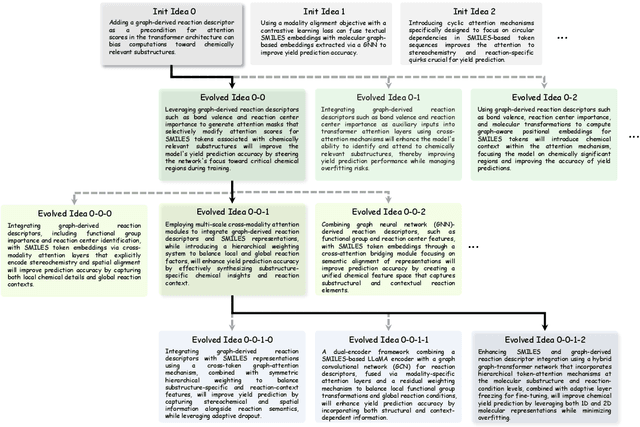
Artificial Intelligence (AI) is accelerating the transformation of scientific research paradigms, not only enhancing research efficiency but also driving innovation. We introduce NovelSeek, a unified closed-loop multi-agent framework to conduct Autonomous Scientific Research (ASR) across various scientific research fields, enabling researchers to tackle complicated problems in these fields with unprecedented speed and precision. NovelSeek highlights three key advantages: 1) Scalability: NovelSeek has demonstrated its versatility across 12 scientific research tasks, capable of generating innovative ideas to enhance the performance of baseline code. 2) Interactivity: NovelSeek provides an interface for human expert feedback and multi-agent interaction in automated end-to-end processes, allowing for the seamless integration of domain expert knowledge. 3) Efficiency: NovelSeek has achieved promising performance gains in several scientific fields with significantly less time cost compared to human efforts. For instance, in reaction yield prediction, it increased from 27.6% to 35.4% in just 12 hours; in enhancer activity prediction, accuracy rose from 0.52 to 0.79 with only 4 hours of processing; and in 2D semantic segmentation, precision advanced from 78.8% to 81.0% in a mere 30 hours.