 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-Edit: Intelligent Editing Is A General Task For Unified Model Tuning
May 20, 2026Currently, enhancing Unified Multimodal Models (UMMs) with image understanding, generation, and editing capabilities mainly relies on mixed multi-task training. Due to inherent task conflicts, such strategy requires complex multi-stage pipelines, massive data mixing, and balancing tricks, merely resulting in a performance trade-off rather than true mutual reinforcement. To break this paradigm, we propose Uni-Edit, an intelligent image editing task that serves as the first general task for UMM tuning. Unlike complex mixed pipelines, Uni-Edit improves performance across all three abilities at once using only one task, one training stage, and one dataset. Specifically, we first identify image editing as an inherently ideal general task, as it naturally demands both visual understanding and generation. However, existing editing data relies on simplistic instructions that severely underutilize a model's understanding capacity. To address this, we introduce the first automated and scalable data synthesis pipeline for intelligent editing, transforming diverse VQA data into complex and effective editing instructions with embedded questions and nested logic. This yields Uni-Edit-148k, pairing diverse reasoning-intensive instructions with high-quality edited images. Extensive experiments on BAGEL and Janus-Pro demonstrate that tuning solely on Uni-Edit achieves comprehensive enhancements across all three capabilities without any auxiliary operations.
From Web to Pixels: Bringing Agentic Search into Visual Perception
May 12, 2026Visual perception connects high-level semantic understanding to pixel-level perception, but most existing settings assume that the decisive evidence for identifying a target is already in the image or frozen model knowledge. We study a more practical yet harder open-world case where a visible object must first be resolved from external facts, recent events, long-tail entities, or multi-hop relations before it can be localized. We formalize this challenge as Perception Deep Research and introduce WebEye, an object-anchored benchmark with verifiable evidence, knowledge-intensive queries, precise box/mask annotations, and three task views: Search-based Grounding, Search-based Segmentation, and Search-based VQA. WebEyes contains 120 images, 473 annotated object instances, 645 unique QA pairs, and 1,927 task samples. We further propose Pixel-Searcher, an agentic search-to-pixel workflow that resolves hidden target identities and binds them to boxes, masks, or grounded answers. Experiments show that Pixel-Searcher achieves the strongest open-source performance across all three task views, while failures mainly arise from evidence acquisition, identity resolution, and visual instance binding.
OpenSearch-VL: An Open Recipe for Frontier Multimodal Search Agents
May 06, 2026Deep search has become a crucial capability for frontier multimodal agents, enabling models to solve complex questions through active search, evidence verification, and multi-step reasoning. Despite rapid progress, top-tier multimodal search agents remain difficult to reproduce, largely due to the absence of open high-quality training data, transparent trajectory synthesis pipelines, or detailed training recipes. To this end, we introduce OpenSearch-VL, a fully open-source recipe for training frontier multimodal deep search agents with agentic reinforcement learning. First, we curated a dedicated pipeline to construct high-quality training data through Wikipedia path sampling, fuzzy entity rewriting, and source-anchor visual grounding, which jointly reduce shortcuts and one-step retrieval collapse. Based on this pipeline, we curate two training datasets, SearchVL-SFT-36k for SFT and SearchVL-RL-8k for RL. Besides, we design a diverse tool environment that unifies text search, image search, OCR, cropping, sharpening, super-resolution, and perspective correction, enabling agents to combine active perception with external knowledge acquisition. Finally, we propose a multi-turn fatal-aware GRPO training algorithm that handles cascading tool failures by masking post-failure tokens while preserving useful pre-failure reasoning through one-sided advantage clamping. Built on this recipe, OpenSearch-VL delivers substantial performance gains, with over 10-point average improvements across seven benchmarks, and achieves results comparable to proprietary commercial models on several tasks. We will release all data, code, and models to support open research on multimodal deep search agents.
The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook
Apr 02, 2026Latent space is rapidly emerging as a native substrate for language-based models. While modern systems are still commonly understood through explicit token-level generation, an increasing body of work shows that many critical internal processes are more naturally carried out in continuous latent space than in human-readable verbal traces. This shift is driven by the structural limitations of explicit-space computation, including linguistic redundancy, discretization bottlenecks, sequential inefficiency, and semantic loss. This survey aims to provide a unified and up-to-date landscape of latent space in language-based models. We organize the survey into five sequential perspectives: Foundation, Evolution, Mechanism, Ability, and Outlook. We begin by delineating the scope of latent space, distinguishing it from explicit or verbal space and from the latent spaces commonly studied in generative visual models. We then trace the field's evolution from early exploratory efforts to the current large-scale expansion. To organize the technical landscape, we examine existing work through the complementary lenses of mechanism and ability. From the perspective of Mechanism, we identify four major lines of development: Architecture, Representation, Computation, and Optimization. From the perspective of Ability, we show how latent space supports a broad capability spectrum spanning Reasoning, Planning, Modeling, Perception, Memory, Collaboration, and Embodiment. Beyond consolidation, we discuss the key open challenges, and outline promising directions for future research. We hope this survey serves not only as a reference for existing work, but also as a foundation for understanding latent space as a general computational and systems paradigm for next-generation intelligence.
Unify-Agent: A Unified Multimodal Agent for World-Grounded Image Synthesis
Apr 01, 2026Unified multimodal models provide a natural and promising architecture for understanding diverse and complex real-world knowledge while generating high-quality images. However, they still rely primarily on frozen parametric knowledge, which makes them struggle with real-world image generation involving long-tail and knowledge-intensive concepts. Inspired by the broad success of agents on real-world tasks, we explore agentic modeling to address this limitation. Specifically, we present Unify-Agent, a unified multimodal agent for world-grounded image synthesis, which reframes image generation as an agentic pipeline consisting of prompt understanding, multimodal evidence searching, grounded recaptioning, and final synthesis. To train our model, we construct a tailored multimodal data pipeline and curate 143K high-quality agent trajectories for world-grounded image synthesis, enabling effective supervision over the full agentic generation process. We further introduce FactIP, a benchmark covering 12 categories of culturally significant and long-tail factual concepts that explicitly requires external knowledge grounding. Extensive experiments show that our proposed Unify-Agent substantially improves over its base unified model across diverse benchmarks and real world generation tasks, while approaching the world knowledge capabilities of the strongest closed-source models. As an early exploration of agent-based modeling for world-grounded image synthesis, our work highlights the value of tightly coupling reasoning, searching, and generation for reliable open-world agentic image synthesis.
Gen-Searcher: Reinforcing Agentic Search for Image Generation
Mar 30, 2026Recent image generation models have shown strong capabilities in generating high-fidelity and photorealistic images. However, they are fundamentally constrained by frozen internal knowledge, thus often failing on real-world scenarios that are knowledge-intensive or require up-to-date information. In this paper, we present Gen-Searcher, as the first attempt to train a search-augmented image generation agent, which performs multi-hop reasoning and search to collect the textual knowledge and reference images needed for grounded generation. To achieve this, we construct a tailored data pipeline and curate two high-quality datasets, Gen-Searcher-SFT-10k and Gen-Searcher-RL-6k, containing diverse search-intensive prompts and corresponding ground-truth synthesis images. We further introduce KnowGen, a comprehensive benchmark that explicitly requires search-grounded external knowledge for image generation and evaluates models from multiple dimensions. Based on these resources, we train Gen-Searcher with SFT followed by agentic reinforcement learning with dual reward feedback, which combines text-based and image-based rewards to provide more stable and informative learning signals for GRPO training. Experiments show that Gen-Searcher brings substantial gains, improving Qwen-Image by around 16 points on KnowGen and 15 points on WISE. We hope this work can serve as an open foundation for search agents in image generation, and we fully open-source our data, models, and code.
Exploring Reasoning Reward Model for Agents
Jan 29, 2026Agentic Reinforcement Learning (Agentic RL) has achieved notable success in enabling agents to perform complex reasoning and tool use. However, most methods still relies on sparse outcome-based reward for training. Such feedback fails to differentiate intermediate reasoning quality, leading to suboptimal training results. In this paper, we introduce Agent Reasoning Reward Model (Agent-RRM), a multi-faceted reward model that produces structured feedback for agentic trajectories, including (1) an explicit reasoning trace , (2) a focused critique that provides refinement guidance by highlighting reasoning flaws, and (3) an overall score that evaluates process performance. Leveraging these signals, we systematically investigate three integration strategies: Reagent-C (text-augmented refinement), Reagent-R (reward-augmented guidance), and Reagent-U (unified feedback integration). Extensive evaluations across 12 diverse benchmarks demonstrate that Reagent-U yields substantial performance leaps, achieving 43.7% on GAIA and 46.2% on WebWalkerQA, validating the effectiveness of our reasoning reward model and training schemes. Code, models, and datasets are all released to facilitate future research.
AdaTooler-V: Adaptive Tool-Use for Images and Videos
Dec 19, 2025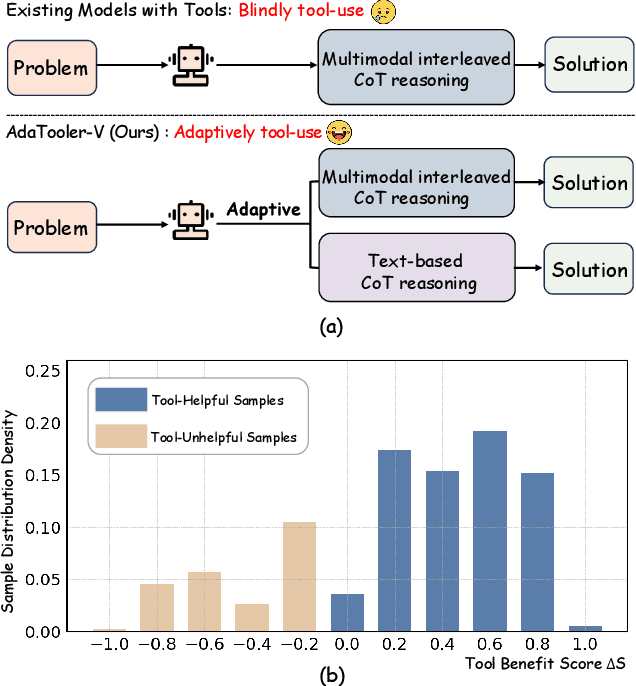
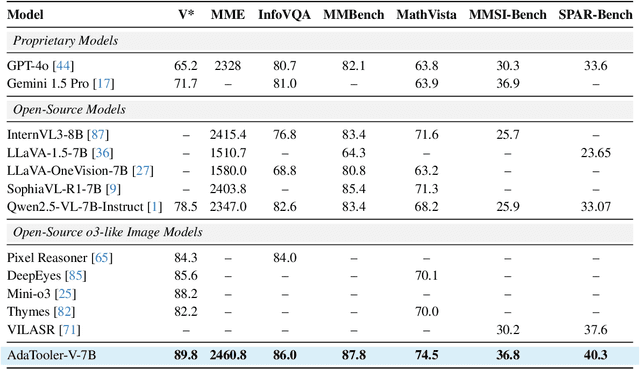
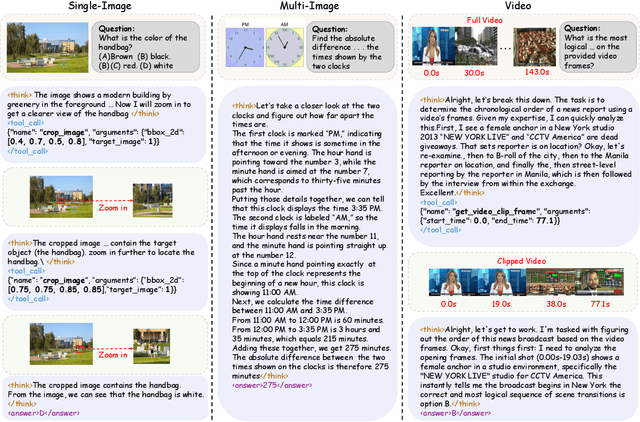
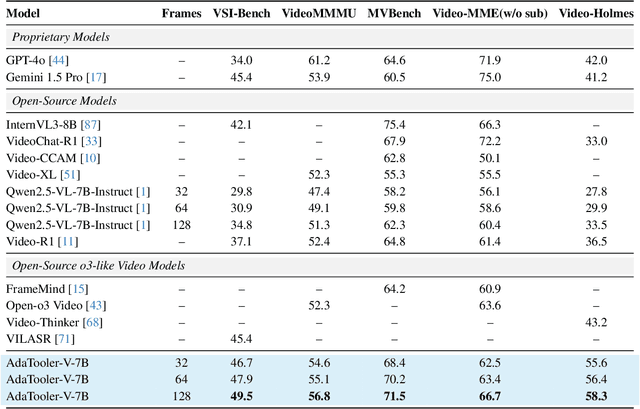
Recent advances have shown that multimodal large language models (MLLMs) benefit from multimodal interleaved chain-of-thought (CoT) with vision tool interactions. However, existing open-source models often exhibit blind tool-use reasoning patterns, invoking vision tools even when they are unnecessary, which significantly increases inference overhead and degrades model performance. To this end, we propose AdaTooler-V, an MLLM that performs adaptive tool-use by determining whether a visual problem truly requires tools. First, we introduce AT-GRPO, a reinforcement learning algorithm that adaptively adjusts reward scales based on the Tool Benefit Score of each sample, encouraging the model to invoke tools only when they provide genuine improvements. Moreover, we construct two datasets to support training: AdaTooler-V-CoT-100k for SFT cold start and AdaTooler-V-300k for RL with verifiable rewards across single-image, multi-image, and video data. Experiments across twelve benchmarks demonstrate the strong reasoning capability of AdaTooler-V, outperforming existing methods in diverse visual reasoning tasks. Notably, AdaTooler-V-7B achieves an accuracy of 89.8\% on the high-resolution benchmark V*, surpassing the commercial proprietary model GPT-4o and Gemini 1.5 Pro. All code, models, and data are released.
SpaceVista: All-Scale Visual Spatial Reasoning from mm to km
Oct 10, 2025With the current surge in spatial reasoning explorations, researchers have made significant progress in understanding indoor scenes, but still struggle with diverse applications such as robotics and autonomous driving. This paper aims to advance all-scale spatial reasoning across diverse scenarios by tackling two key challenges: 1) the heavy reliance on indoor 3D scans and labor-intensive manual annotations for dataset curation; 2) the absence of effective all-scale scene modeling, which often leads to overfitting to individual scenes. In this paper, we introduce a holistic solution that integrates a structured spatial reasoning knowledge system, scale-aware modeling, and a progressive training paradigm, as the first attempt to broaden the all-scale spatial intelligence of MLLMs to the best of our knowledge. Using a task-specific, specialist-driven automated pipeline, we curate over 38K video scenes across 5 spatial scales to create SpaceVista-1M, a dataset comprising approximately 1M spatial QA pairs spanning 19 diverse task types. While specialist models can inject useful domain knowledge, they are not reliable for evaluation. We then build an all-scale benchmark with precise annotations by manually recording, retrieving, and assembling video-based data. However, naive training with SpaceVista-1M often yields suboptimal results due to the potential knowledge conflict. Accordingly, we introduce SpaceVista-7B, a spatial reasoning model that accepts dense inputs beyond semantics and uses scale as an anchor for scale-aware experts and progressive rewards. Finally, extensive evaluations across 5 benchmarks, including our SpaceVista-Bench, demonstrate competitive performance, showcasing strong generalization across all scales and scenarios. Our dataset, model, and benchmark will be released on https://peiwensun2000.github.io/mm2km .
Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing
Jun 11, 2025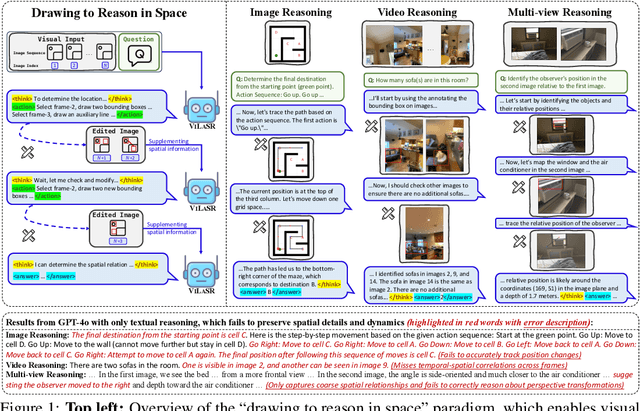
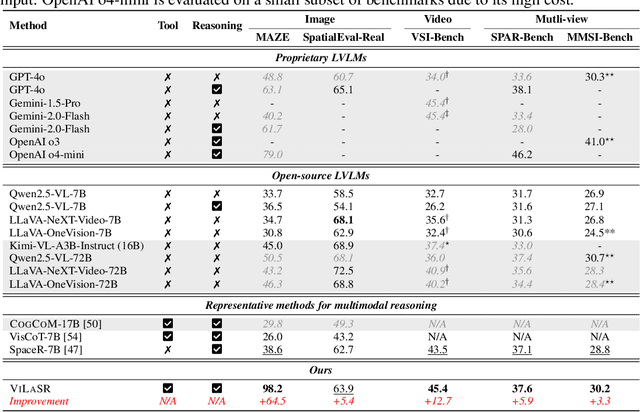
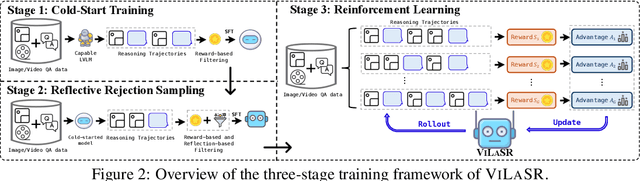

As textual reasoning with large language models (LLMs) has advanced significantly, there has been growing interest in enhancing the multimodal reasoning capabilities of large vision-language models (LVLMs). However, existing methods primarily approach multimodal reasoning in a straightforward, text-centric manner, where both reasoning and answer derivation are conducted purely through text, with the only difference being the presence of multimodal input. As a result, these methods often encounter fundamental limitations in spatial reasoning tasks that demand precise geometric understanding and continuous spatial tracking-capabilities that humans achieve through mental visualization and manipulation. To address the limitations, we propose drawing to reason in space, a novel paradigm that enables LVLMs to reason through elementary drawing operations in the visual space. By equipping models with basic drawing operations, including annotating bounding boxes and drawing auxiliary lines, we empower them to express and analyze spatial relationships through direct visual manipulation, meanwhile avoiding the performance ceiling imposed by specialized perception tools in previous tool-integrated reasoning approaches. To cultivate this capability, we develop a three-stage training framework: cold-start training with synthetic data to establish basic drawing abilities, reflective rejection sampling to enhance self-reflection behaviors, and reinforcement learning to directly optimize for target rewards. Extensive experiments demonstrate that our model, named VILASR, consistently outperforms existing methods across diverse spatial reasoning benchmarks, involving maze navigation, static spatial reasoning, video-based reasoning, and multi-view-based reasoning tasks, with an average improvement of 18.4%.