 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealChart2Code: Advancing Chart-to-Code Generation with Real Data and Multi-Task Evaluation
Mar 26, 2026Vision-Language Models (VLMs) have demonstrated impressive capabilities in code generation across various domains. However, their ability to replicate complex, multi-panel visualizations from real-world data remains largely unassessed. To address this gap, we introduce \textbf{\texttt{RealChart2Code}}, a new large-scale benchmark with over 2,800 instances grounded in authentic datasets and featuring tasks with clear analytical intent. Crucially, it is the first benchmark to systematically evaluate chart generation from large-scale raw data and assess iterative code refinement in a multi-turn conversational setting. Our comprehensive evaluation of 14 leading VLMs on \texttt{RealChart2Code} reveals significant performance degradation compared to simpler benchmarks, highlighting their struggles with complex plot structures and authentic data. Our analysis uncovers a substantial performance gap between proprietary and open-weight models and confirms that even state-of-the-art VLMs often fail to accurately replicate intricate, multi-panel charts. These findings provide valuable insights into the current limitations of VLMs and guide future research directions. We release the benchmark and code at \url{https://github.com/Speakn0w/RealChart2Code}.
Chatting with Images for Introspective Visual Thinking
Feb 12, 2026Current large vision-language models (LVLMs) typically rely on text-only reasoning based on a single-pass visual encoding, which often leads to loss of fine-grained visual information. Recently the proposal of ''thinking with images'' attempts to alleviate this limitation by manipulating images via external tools or code; however, the resulting visual states are often insufficiently grounded in linguistic semantics, impairing effective cross-modal alignment - particularly when visual semantics or geometric relationships must be reasoned over across distant regions or multiple images. To address these challenges, we propose ''chatting with images'', a new framework that reframes visual manipulation as language-guided feature modulation. Under the guidance of expressive language prompts, the model dynamically performs joint re-encoding over multiple image regions, enabling tighter coupling between linguistic reasoning and visual state updates. We instantiate this paradigm in ViLaVT, a novel LVLM equipped with a dynamic vision encoder explicitly designed for such interactive visual reasoning, and trained it with a two-stage curriculum combining supervised fine-tuning and reinforcement learning to promote effective reasoning behaviors. Extensive experiments across eight benchmarks demonstrate that ViLaVT achieves strong and consistent improvements, with particularly pronounced gains on complex multi-image and video-based spatial reasoning tasks.
OmniSIFT: Modality-Asymmetric Token Compression for Efficient Omni-modal Large Language Models
Feb 04, 2026Omni-modal Large Language Models (Omni-LLMs) have demonstrated strong capabilities in audio-video understanding tasks. However, their reliance on long multimodal token sequences leads to substantial computational overhead. Despite this challenge, token compression methods designed for Omni-LLMs remain limited. To bridge this gap, we propose OmniSIFT (Omni-modal Spatio-temporal Informed Fine-grained Token compression), a modality-asymmetric token compression framework tailored for Omni-LLMs. Specifically, OmniSIFT adopts a two-stage compression strategy: (i) a spatio-temporal video pruning module that removes video redundancy arising from both intra-frame structure and inter-frame overlap, and (ii) a vision-guided audio selection module that filters audio tokens. The entire framework is optimized end-to-end via a differentiable straight-through estimator. Extensive experiments on five representative benchmarks demonstrate the efficacy and robustness of OmniSIFT. Notably, for Qwen2.5-Omni-7B, OmniSIFT introduces only 4.85M parameters while maintaining lower latency than training-free baselines such as OmniZip. With merely 25% of the original token context, OmniSIFT consistently outperforms all compression baselines and even surpasses the performance of the full-token model on several tasks.
Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing
Jun 11, 2025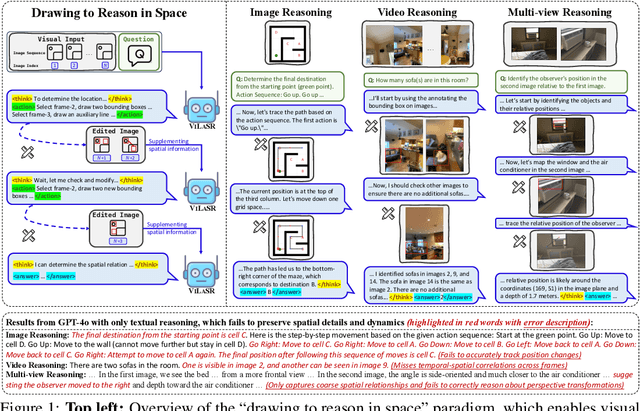
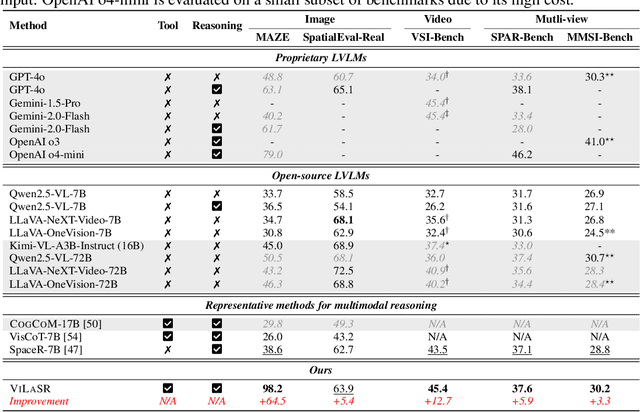
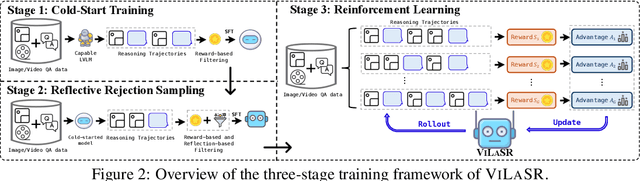

As textual reasoning with large language models (LLMs) has advanced significantly, there has been growing interest in enhancing the multimodal reasoning capabilities of large vision-language models (LVLMs). However, existing methods primarily approach multimodal reasoning in a straightforward, text-centric manner, where both reasoning and answer derivation are conducted purely through text, with the only difference being the presence of multimodal input. As a result, these methods often encounter fundamental limitations in spatial reasoning tasks that demand precise geometric understanding and continuous spatial tracking-capabilities that humans achieve through mental visualization and manipulation. To address the limitations, we propose drawing to reason in space, a novel paradigm that enables LVLMs to reason through elementary drawing operations in the visual space. By equipping models with basic drawing operations, including annotating bounding boxes and drawing auxiliary lines, we empower them to express and analyze spatial relationships through direct visual manipulation, meanwhile avoiding the performance ceiling imposed by specialized perception tools in previous tool-integrated reasoning approaches. To cultivate this capability, we develop a three-stage training framework: cold-start training with synthetic data to establish basic drawing abilities, reflective rejection sampling to enhance self-reflection behaviors, and reinforcement learning to directly optimize for target rewards. Extensive experiments demonstrate that our model, named VILASR, consistently outperforms existing methods across diverse spatial reasoning benchmarks, involving maze navigation, static spatial reasoning, video-based reasoning, and multi-view-based reasoning tasks, with an average improvement of 18.4%.
STRIVE: Structured Reasoning for Self-Improvement in Claim Verification
Feb 17, 2025Claim verification is the task of determining whether a claim is supported or refuted by evidence. Self-improvement methods, where reasoning chains are generated and those leading to correct results are selected for training, have succeeded in tasks like mathematical problem solving. However, in claim verification, this approach struggles. Low-quality reasoning chains may falsely match binary truth labels, introducing faulty reasoning into the self-improvement process and ultimately degrading performance. To address this, we propose STRIVE: Structured Reasoning for Self-Improved Verification. Our method introduces a structured reasoning design with Claim Decomposition, Entity Analysis, and Evidence Grounding Verification. These components improve reasoning quality, reduce errors, and provide additional supervision signals for self-improvement. STRIVE begins with a warm-up phase, where the base model is fine-tuned on a small number of annotated examples to learn the structured reasoning design. It is then applied to generate reasoning chains for all training examples, selecting only those that are correct and structurally sound for subsequent self-improvement training. We demonstrate that STRIVE achieves significant improvements over baseline models, with a 31.4% performance gain over the base model and 20.7% over Chain of Thought on the HOVER datasets, highlighting its effectiveness.
MME-RealWorld: Could Your Multimodal LLM Challenge High-Resolution Real-World Scenarios that are Difficult for Humans?
Aug 23, 2024



Comprehensive evaluation of Multimodal Large Language Models (MLLMs) has recently garnered widespread attention in the research community. However, we observe that existing benchmarks present several common barriers that make it difficult to measure the significant challenges that models face in the real world, including: 1) small data scale leads to a large performance variance; 2) reliance on model-based annotations results in restricted data quality; 3) insufficient task difficulty, especially caused by the limited image resolution. To tackle these issues, we introduce MME-RealWorld. Specifically, we collect more than $300$K images from public datasets and the Internet, filtering $13,366$ high-quality images for annotation. This involves the efforts of professional $25$ annotators and $7$ experts in MLLMs, contributing to $29,429$ question-answer pairs that cover $43$ subtasks across $5$ real-world scenarios, extremely challenging even for humans. As far as we know, MME-RealWorld is the largest manually annotated benchmark to date, featuring the highest resolution and a targeted focus on real-world applications. We further conduct a thorough evaluation involving $28$ prominent MLLMs, such as GPT-4o, Gemini 1.5 Pro, and Claude 3.5 Sonnet. Our results show that even the most advanced models struggle with our benchmarks, where none of them reach $60\%$ accuracy. The challenges of perceiving high-resolution images and understanding complex real-world scenarios remain urgent issues to be addressed. The data and evaluation code are released at https://mme-realworld.github.io/ .
Logical Closed Loop: Uncovering Object Hallucinations in Large Vision-Language Models
Feb 18, 2024Object hallucination has been an Achilles' heel which hinders the broader applications of large vision-language models (LVLMs). Object hallucination refers to the phenomenon that the LVLMs claim non-existent objects in the image. To mitigate the object hallucinations, instruction tuning and external model-based detection methods have been proposed, which either require large-scare computational resources or depend on the detection result of external models. However, there remains an under-explored field to utilize the LVLM itself to alleviate object hallucinations. In this work, we adopt the intuition that the LVLM tends to respond logically consistently for existent objects but inconsistently for hallucinated objects. Therefore, we propose a Logical Closed Loop-based framework for Object Hallucination Detection and Mitigation, namely LogicCheckGPT. In specific, we devise logical consistency probing to raise questions with logical correlations, inquiring about attributes from objects and vice versa. Whether their responses can form a logical closed loop serves as an indicator of object hallucination. As a plug-and-play method, it can be seamlessly applied to all existing LVLMs. Comprehensive experiments conducted on three benchmarks across four LVLMs have demonstrated significant improvements brought by our method, indicating its effectiveness and generality.
Can Large Language Models Detect Rumors on Social Media?
Feb 08, 2024



In this work, we investigate to use Large Language Models (LLMs) for rumor detection on social media. However, it is challenging for LLMs to reason over the entire propagation information on social media, which contains news contents and numerous comments, due to LLMs may not concentrate on key clues in the complex propagation information, and have trouble in reasoning when facing massive and redundant information. Accordingly, we propose an LLM-empowered Rumor Detection (LeRuD) approach, in which we design prompts to teach LLMs to reason over important clues in news and comments, and divide the entire propagation information into a Chain-of-Propagation for reducing LLMs' burden. We conduct extensive experiments on the Twitter and Weibo datasets, and LeRuD outperforms several state-of-the-art rumor detection models by 3.2% to 7.7%. Meanwhile, by applying LLMs, LeRuD requires no data for training, and thus shows more promising rumor detection ability in few-shot or zero-shot scenarios.
Out-of-distribution Evidence-aware Fake News Detection via Dual Adversarial Debiasing
Apr 25, 2023



Evidence-aware fake news detection aims to conduct reasoning between news and evidence, which is retrieved based on news content, to find uniformity or inconsistency. However, we find evidence-aware detection models suffer from biases, i.e., spurious correlations between news/evidence contents and true/fake news labels, and are hard to be generalized to Out-Of-Distribution (OOD) situations. To deal with this, we propose a novel Dual Adversarial Learning (DAL) approach. We incorporate news-aspect and evidence-aspect debiasing discriminators, whose targets are both true/fake news labels, in DAL. Then, DAL reversely optimizes news-aspect and evidence-aspect debiasing discriminators to mitigate the impact of news and evidence content biases. At the same time, DAL also optimizes the main fake news predictor, so that the news-evidence interaction module can be learned. This process allows us to teach evidence-aware fake news detection models to better conduct news-evidence reasoning, and minimize the impact of content biases. To be noted, our proposed DAL approach is a plug-and-play module that works well with existing backbones. We conduct comprehensive experiments under two OOD settings, and plug DAL in four evidence-aware fake news detection backbones. Results demonstrate that, DAL significantly and stably outperforms the original backbones and some competitive debiasing methods.
Adversarial Contrastive Learning for Evidence-aware Fake News Detection with Graph Neural Networks
Oct 11, 2022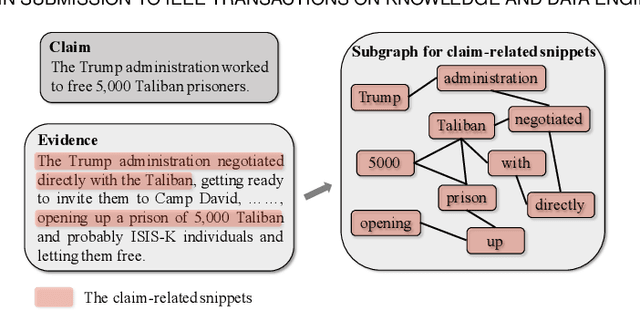

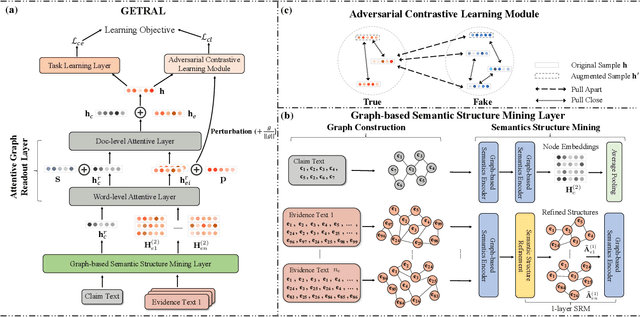

The prevalence and perniciousness of fake news have been a critical issue on the Internet, which stimulates the development of automatic fake news detection in turn. In this paper, we focus on evidence-based fake news detection, where several evidences are utilized to probe the veracity of news (i.e., a claim). Most previous methods first employ sequential models to embed the semantic information and then capture the claim-evidence interaction based on attention mechanisms. Despite their effectiveness, they still suffer from three weaknesses. Firstly, sequential models fail to integrate the relevant information that is scattered far apart in evidences. Secondly, they underestimate much redundant information in evidences may be useless or harmful. Thirdly, insufficient data utilization limits the separability and reliability of representations captured by the model. To solve these problems, we propose a unified Graph-based sEmantic structure mining framework with ConTRAstive Learning, namely GETRAL in short. Specifically, we first model claims and evidences as graph-structured data to capture the long-distance semantic dependency. Consequently, we reduce information redundancy by performing graph structure learning. Then the fine-grained semantic representations are fed into the claim-evidence interaction module for predictions. Finally, an adversarial contrastive learning module is applied to make full use of data and strengthen representation learning. Comprehensive experiments have demonstrated the superiority of GETRAL over the state-of-the-arts and validated the efficacy of semantic mining with graph structure and contrastive learning.