 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-Level Graph Structure Learning for Next POI Recommendation
Nov 02, 2024



Next point-of-interest (POI) recommendation aims to predict a user's next destination based on sequential check-in history and a set of POI candidates. Graph neural networks (GNNs) have demonstrated a remarkable capability in this endeavor by exploiting the extensive global collaborative signals present among POIs. However, most of the existing graph-based approaches construct graph structures based on pre-defined heuristics, failing to consider inherent hierarchical structures of POI features such as geographical locations and visiting peaks, or suffering from noisy and incomplete structures in graphs. To address the aforementioned issues, this paper presents a novel Bi-level Graph Structure Learning (BiGSL) for next POI recommendation. BiGSL first learns a hierarchical graph structure to capture the fine-to-coarse connectivity between POIs and prototypes, and then uses a pairwise learning module to dynamically infer relationships between POI pairs and prototype pairs. Based on the learned bi-level graphs, our model then employs a multi-relational graph network that considers both POI- and prototype-level neighbors, resulting in improved POI representations. Our bi-level structure learning scheme is more robust to data noise and incompleteness, and improves the exploration ability for recommendation by alleviating sparsity issues. Experimental results on three real-world datasets demonstrate the superiority of our model over existing state-of-the-art methods, with a significant improvement in recommendation accuracy and exploration performance.
* Accepted by IEEE Transactions on Knowledge and Data Engineering
Semantic Evolvement Enhanced Graph Autoencoder for Rumor Detection
Apr 24, 2024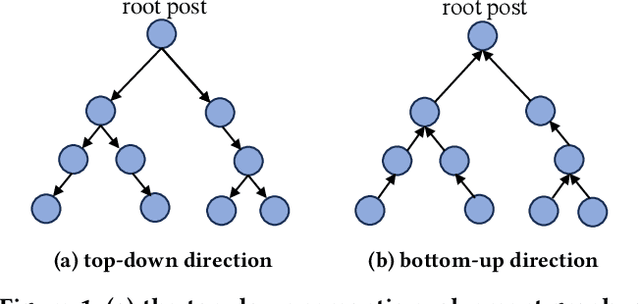
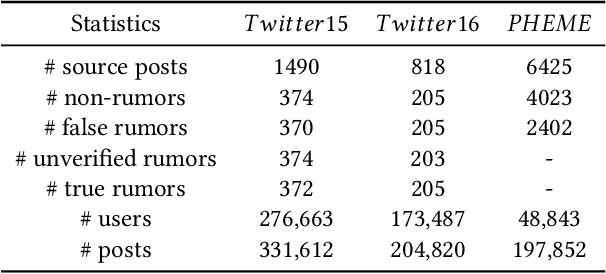
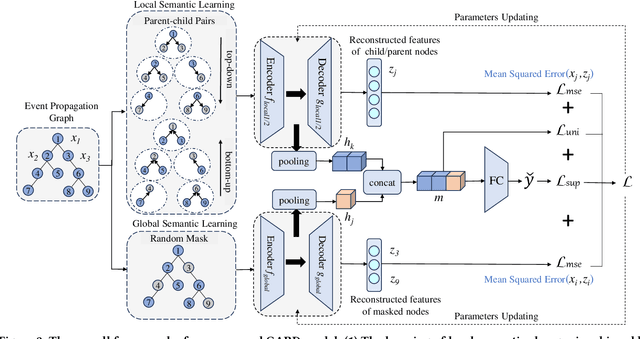
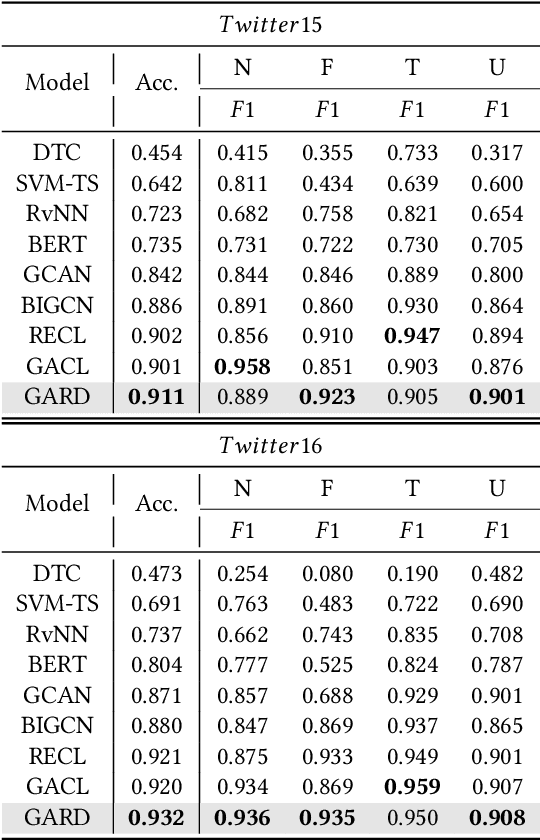
Due to the rapid spread of rumors on social media, rumor detection has become an extremely important challenge. Recently, numerous rumor detection models which utilize textual information and the propagation structure of events have been proposed. However, these methods overlook the importance of semantic evolvement information of event in propagation process, which is often challenging to be truly learned in supervised training paradigms and traditional rumor detection methods. To address this issue, we propose a novel semantic evolvement enhanced Graph Autoencoder for Rumor Detection (GARD) model in this paper. The model learns semantic evolvement information of events by capturing local semantic changes and global semantic evolvement information through specific graph autoencoder and reconstruction strategies. By combining semantic evolvement information and propagation structure information, the model achieves a comprehensive understanding of event propagation and perform accurate and robust detection, while also detecting rumors earlier by capturing semantic evolvement information in the early stages. Moreover, in order to enhance the model's ability to learn the distinct patterns of rumors and non-rumors, we introduce a uniformity regularizer to further improve the model's performance. Experimental results on three public benchmark datasets confirm the superiority of our GARD method over the state-of-the-art approaches in both overall performance and early rumor detection.
Out-of-distribution Rumor Detection via Test-Time Adaptation
Mar 26, 2024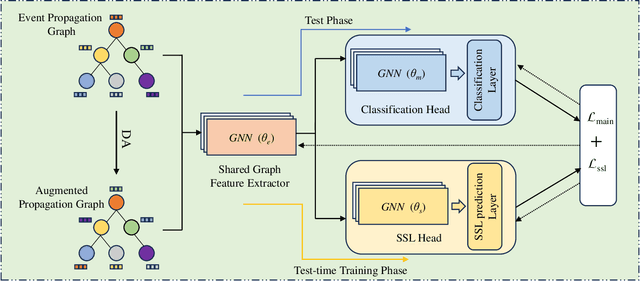
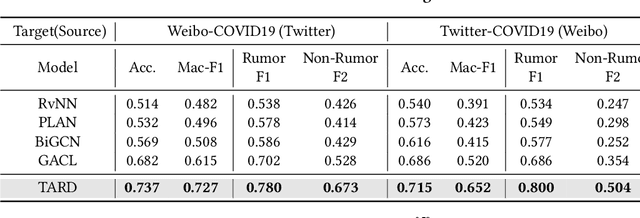
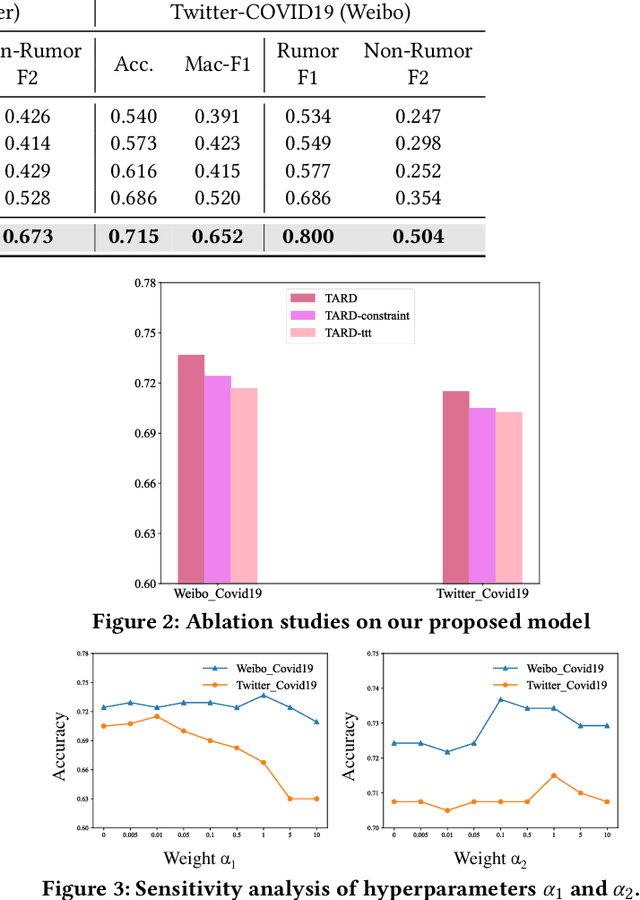
Due to the rapid spread of rumors on social media, rumor detection has become an extremely important challenge. Existing methods for rumor detection have achieved good performance, as they have collected enough corpus from the same data distribution for model training. However, significant distribution shifts between the training data and real-world test data occur due to differences in news topics, social media platforms, languages and the variance in propagation scale caused by news popularity. This leads to a substantial decline in the performance of these existing methods in Out-Of-Distribution (OOD) situations. To address this problem, we propose a simple and efficient method named Test-time Adaptation for Rumor Detection under distribution shifts (TARD). This method models the propagation of news in the form of a propagation graph, and builds propagation graph test-time adaptation framework, enhancing the model's adaptability and robustness when facing OOD problems. Extensive experiments conducted on two group datasets collected from real-world social platforms demonstrate that our framework outperforms the state-of-the-art methods in performance.
Rethinking Graph Masked Autoencoders through Alignment and Uniformity
Feb 11, 2024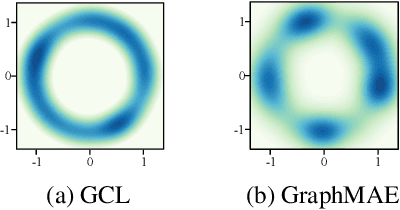
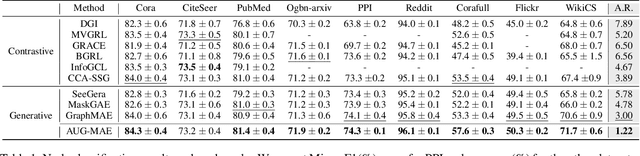
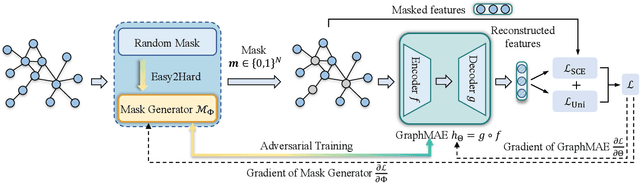
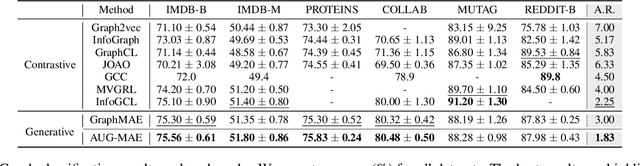
Self-supervised learning on graphs can be bifurcated into contrastive and generative methods. Contrastive methods, also known as graph contrastive learning (GCL), have dominated graph self-supervised learning in the past few years, but the recent advent of graph masked autoencoder (GraphMAE) rekindles the momentum behind generative methods. Despite the empirical success of GraphMAE, there is still a dearth of theoretical understanding regarding its efficacy. Moreover, while both generative and contrastive methods have been shown to be effective, their connections and differences have yet to be thoroughly investigated. Therefore, we theoretically build a bridge between GraphMAE and GCL, and prove that the node-level reconstruction objective in GraphMAE implicitly performs context-level GCL. Based on our theoretical analysis, we further identify the limitations of the GraphMAE from the perspectives of alignment and uniformity, which have been considered as two key properties of high-quality representations in GCL. We point out that GraphMAE's alignment performance is restricted by the masking strategy, and the uniformity is not strictly guaranteed. To remedy the aforementioned limitations, we propose an Alignment-Uniformity enhanced Graph Masked AutoEncoder, named AUG-MAE. Specifically, we propose an easy-to-hard adversarial masking strategy to provide hard-to-align samples, which improves the alignment performance. Meanwhile, we introduce an explicit uniformity regularizer to ensure the uniformity of the learned representations. Experimental results on benchmark datasets demonstrate the superiority of our model over existing state-of-the-art methods.
Can Large Language Models Detect Rumors on Social Media?
Feb 08, 2024



In this work, we investigate to use Large Language Models (LLMs) for rumor detection on social media. However, it is challenging for LLMs to reason over the entire propagation information on social media, which contains news contents and numerous comments, due to LLMs may not concentrate on key clues in the complex propagation information, and have trouble in reasoning when facing massive and redundant information. Accordingly, we propose an LLM-empowered Rumor Detection (LeRuD) approach, in which we design prompts to teach LLMs to reason over important clues in news and comments, and divide the entire propagation information into a Chain-of-Propagation for reducing LLMs' burden. We conduct extensive experiments on the Twitter and Weibo datasets, and LeRuD outperforms several state-of-the-art rumor detection models by 3.2% to 7.7%. Meanwhile, by applying LLMs, LeRuD requires no data for training, and thus shows more promising rumor detection ability in few-shot or zero-shot scenarios.