 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObtaining Optimal Spiking Neural Network in Sequence Learning via CRNN-SNN Conversion
Aug 18, 2024



Spiking neural networks (SNNs) are becoming a promising alternative to conventional artificial neural networks (ANNs) due to their rich neural dynamics and the implementation of energy-efficient neuromorphic chips. However, the non-differential binary communication mechanism makes SNN hard to converge to an ANN-level accuracy. When SNN encounters sequence learning, the situation becomes worse due to the difficulties in modeling long-range dependencies. To overcome these difficulties, researchers developed variants of LIF neurons and different surrogate gradients but still failed to obtain good results when the sequence became longer (e.g., $>$500). Unlike them, we obtain an optimal SNN in sequence learning by directly mapping parameters from a quantized CRNN. We design two sub-pipelines to support the end-to-end conversion of different structures in neural networks, which is called CNN-Morph (CNN $\rightarrow$ QCNN $\rightarrow$ BIFSNN) and RNN-Morph (RNN $\rightarrow$ QRNN $\rightarrow$ RBIFSNN). Using conversion pipelines and the s-analog encoding method, the conversion error of our framework is zero. Furthermore, we give the theoretical and experimental demonstration of the lossless CRNN-SNN conversion. Our results show the effectiveness of our method over short and long timescales tasks compared with the state-of-the-art learning- and conversion-based methods. We reach the highest accuracy of 99.16% (0.46 $\uparrow$) on S-MNIST, 94.95% (3.95 $\uparrow$) on PS-MNIST (sequence length of 784) respectively, and the lowest loss of 0.057 (0.013 $\downarrow$) within 8 time-steps in collision avoidance dataset.
Heterogeneous Graph Reasoning for Fact Checking over Texts and Tables
Feb 20, 2024Fact checking aims to predict claim veracity by reasoning over multiple evidence pieces. It usually involves evidence retrieval and veracity reasoning. In this paper, we focus on the latter, reasoning over unstructured text and structured table information. Previous works have primarily relied on fine-tuning pretrained language models or training homogeneous-graph-based models. Despite their effectiveness, we argue that they fail to explore the rich semantic information underlying the evidence with different structures. To address this, we propose a novel word-level Heterogeneous-graph-based model for Fact Checking over unstructured and structured information, namely HeterFC. Our approach leverages a heterogeneous evidence graph, with words as nodes and thoughtfully designed edges representing different evidence properties. We perform information propagation via a relational graph neural network, facilitating interactions between claims and evidence. An attention-based method is utilized to integrate information, combined with a language model for generating predictions. We introduce a multitask loss function to account for potential inaccuracies in evidence retrieval. Comprehensive experiments on the large fact checking dataset FEVEROUS demonstrate the effectiveness of HeterFC. Code will be released at: https://github.com/Deno-V/HeterFC.
Starling: An I/O-Efficient Disk-Resident Graph Index Framework for High-Dimensional Vector Similarity Search on Data Segment
Jan 16, 2024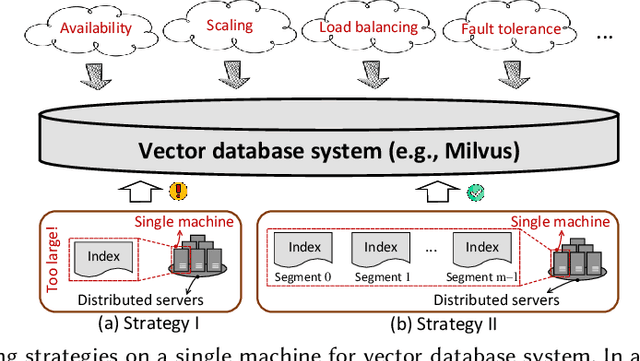

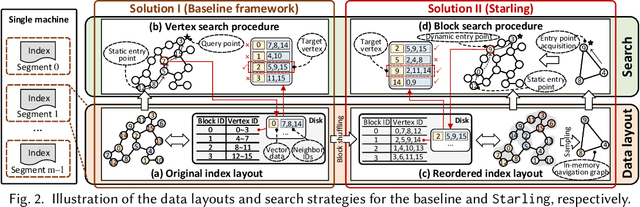

High-dimensional vector similarity search (HVSS) is gaining prominence as a powerful tool for various data science and AI applications. As vector data scales up, in-memory indexes pose a significant challenge due to the substantial increase in main memory requirements. A potential solution involves leveraging disk-based implementation, which stores and searches vector data on high-performance devices like NVMe SSDs. However, implementing HVSS for data segments proves to be intricate in vector databases where a single machine comprises multiple segments for system scalability. In this context, each segment operates with limited memory and disk space, necessitating a delicate balance between accuracy, efficiency, and space cost. Existing disk-based methods fall short as they do not holistically address all these requirements simultaneously. In this paper, we present Starling, an I/O-efficient disk-resident graph index framework that optimizes data layout and search strategy within the segment. It has two primary components: (1) a data layout incorporating an in-memory navigation graph and a reordered disk-based graph with enhanced locality, reducing the search path length and minimizing disk bandwidth wastage; and (2) a block search strategy designed to minimize costly disk I/O operations during vector query execution. Through extensive experiments, we validate the effectiveness, efficiency, and scalability of Starling. On a data segment with 2GB memory and 10GB disk capacity, Starling can accommodate up to 33 million vectors in 128 dimensions, offering HVSS with over 0.9 average precision and top-10 recall rate, and latency under 1 millisecond. The results showcase Starling's superior performance, exhibiting 43.9$\times$ higher throughput with 98% lower query latency compared to state-of-the-art methods while maintaining the same level of accuracy.
EX-FEVER: A Dataset for Multi-hop Explainable Fact Verification
Oct 15, 2023Fact verification aims to automatically probe the veracity of a claim based on several pieces of evidence. Existing works are always engaging in the accuracy improvement, let alone the explainability, a critical capability of fact verification system. Constructing an explainable fact verification system in a complex multi-hop scenario is consistently impeded by the absence of a relevant high-quality dataset. Previous dataset either suffer from excessive simplification or fail to incorporate essential considerations for explainability. To address this, we present EX-FEVER, a pioneering dataset for multi-hop explainable fact verification. With over 60,000 claims involving 2-hop and 3-hop reasoning, each is created by summarizing and modifying information from hyperlinked Wikipedia documents. Each instance is accompanied by a veracity label and an explanation that outlines the reasoning path supporting the veracity classification. Additionally, we demonstrate a novel baseline system on our EX-FEVER dataset, showcasing document retrieval, explanation generation, and claim verification and observe that existing fact verification models trained on previous datasets struggle to perform well on our dataset. Furthermore, we highlight the potential of utilizing Large Language Models in the fact verification task. We hope our dataset could make a significant contribution by providing ample opportunities to explore the integration of natural language explanations in the domain of fact verification.
Adversarial Contrastive Learning for Evidence-aware Fake News Detection with Graph Neural Networks
Oct 11, 2022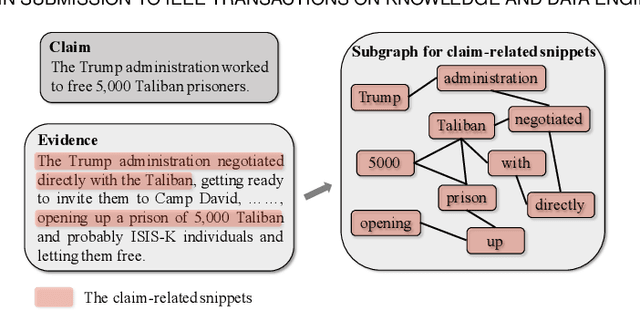

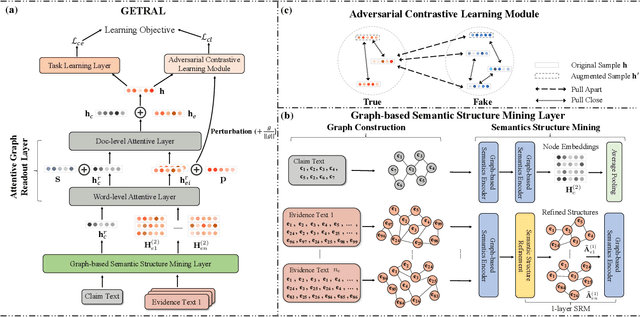

The prevalence and perniciousness of fake news have been a critical issue on the Internet, which stimulates the development of automatic fake news detection in turn. In this paper, we focus on evidence-based fake news detection, where several evidences are utilized to probe the veracity of news (i.e., a claim). Most previous methods first employ sequential models to embed the semantic information and then capture the claim-evidence interaction based on attention mechanisms. Despite their effectiveness, they still suffer from three weaknesses. Firstly, sequential models fail to integrate the relevant information that is scattered far apart in evidences. Secondly, they underestimate much redundant information in evidences may be useless or harmful. Thirdly, insufficient data utilization limits the separability and reliability of representations captured by the model. To solve these problems, we propose a unified Graph-based sEmantic structure mining framework with ConTRAstive Learning, namely GETRAL in short. Specifically, we first model claims and evidences as graph-structured data to capture the long-distance semantic dependency. Consequently, we reduce information redundancy by performing graph structure learning. Then the fine-grained semantic representations are fed into the claim-evidence interaction module for predictions. Finally, an adversarial contrastive learning module is applied to make full use of data and strengthen representation learning. Comprehensive experiments have demonstrated the superiority of GETRAL over the state-of-the-arts and validated the efficacy of semantic mining with graph structure and contrastive learning.
Application of Data Encryption in Chinese Named Entity Recognition
Aug 31, 2022
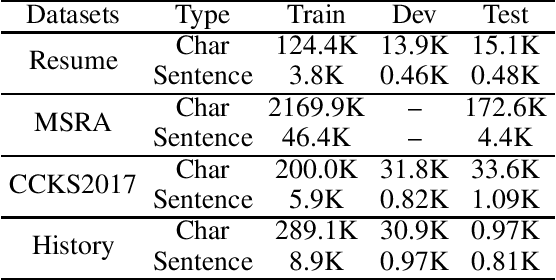


Recently, with the continuous development of deep learning, the performance of named entity recognition tasks has been dramatically improved. However, the privacy and the confidentiality of data in some specific fields, such as biomedical and military, cause insufficient data to support the training of deep neural networks. In this paper, we propose an encryption learning framework to address the problems of data leakage and inconvenient disclosure of sensitive data in certain domains. We introduce multiple encryption algorithms to encrypt training data in the named entity recognition task for the first time. In other words, we train the deep neural network using the encrypted data. We conduct experiments on six Chinese datasets, three of which are constructed by ourselves. The experimental results show that the encryption method achieves satisfactory results. The performance of some models trained with encrypted data even exceeds the performance of the unencrypted method, which verifies the effectiveness of the introduced encryption method and solves the problem of data leakage to a certain extent.
Evidence-aware Fake News Detection with Graph Neural Networks
Feb 08, 2022
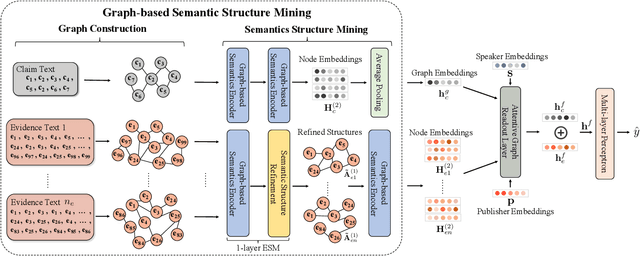
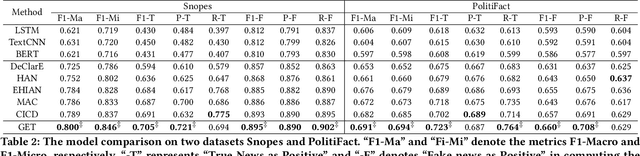
The prevalence and perniciousness of fake news has been a critical issue on the Internet, which stimulates the development of automatic fake news detection in turn. In this paper, we focus on the evidence-based fake news detection, where several evidences are utilized to probe the veracity of news (i.e., a claim). Most previous methods first employ sequential models to embed the semantic information and then capture the claim-evidence interaction based on different attention mechanisms. Despite their effectiveness, they still suffer from two main weaknesses. Firstly, due to the inherent drawbacks of sequential models, they fail to integrate the relevant information that is scattered far apart in evidences for veracity checking. Secondly, they neglect much redundant information contained in evidences that may be useless or even harmful. To solve these problems, we propose a unified Graph-based sEmantic sTructure mining framework, namely GET in short. Specifically, different from the existing work that treats claims and evidences as sequences, we model them as graph-structured data and capture the long-distance semantic dependency among dispersed relevant snippets via neighborhood propagation. After obtaining contextual semantic information, our model reduces information redundancy by performing graph structure learning. Finally, the fine-grained semantic representations are fed into the downstream claim-evidence interaction module for predictions. Comprehensive experiments have demonstrated the superiority of GET over the state-of-the-arts.
Deep Graph Structure Learning for Robust Representations: A Survey
Mar 04, 2021

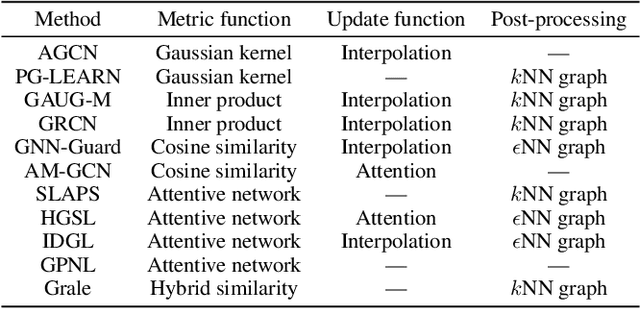

Graph Neural Networks (GNNs) are widely used for analyzing graph-structured data. Most GNN methods are highly sensitive to the quality of graph structures and usually require a perfect graph structure for learning informative embeddings. However, the pervasiveness of noise in graphs necessitates learning robust representations for real-world problems. To improve the robustness of GNN models, many studies have been proposed around the central concept of Graph Structure Learning (GSL), which aims to jointly learn an optimized graph structure and corresponding representations. Towards this end, in the presented survey, we broadly review recent progress of GSL methods for learning robust representations. Specifically, we first formulate a general paradigm of GSL, and then review state-of-the-art methods classified by how they model graph structures, followed by applications that incorporate the idea of GSL in other graph tasks. Finally, we point out some issues in current studies and discuss future directions.
Graph-based Hierarchical Relevance Matching Signals for Ad-hoc Retrieval
Feb 22, 2021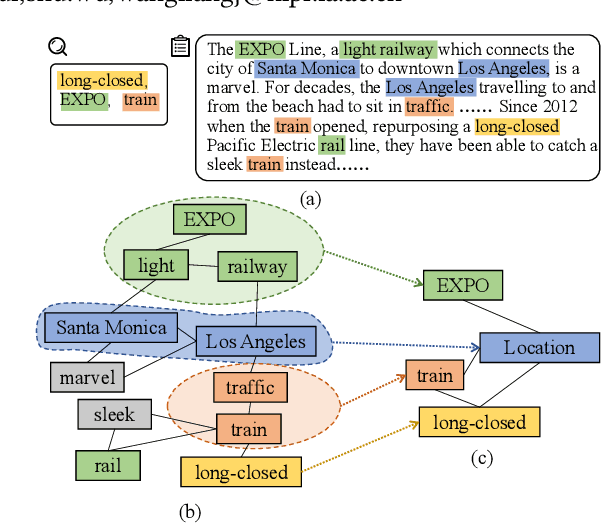

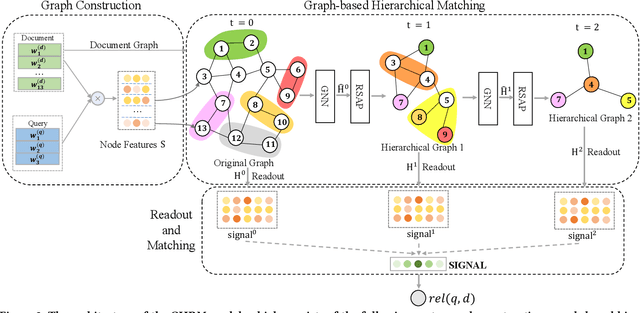
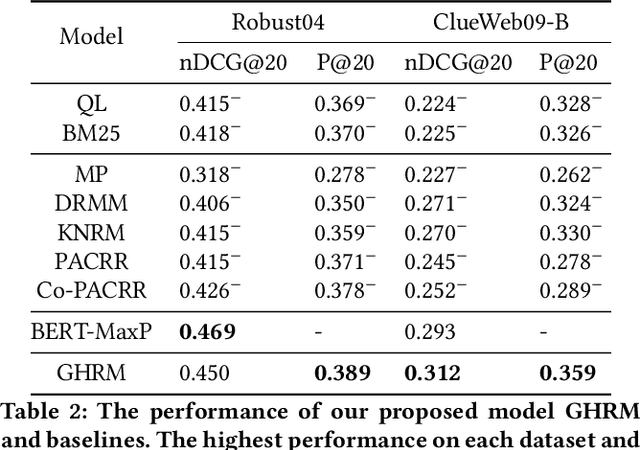
The ad-hoc retrieval task is to rank related documents given a query and a document collection. A series of deep learning based approaches have been proposed to solve such problem and gained lots of attention. However, we argue that they are inherently based on local word sequences, ignoring the subtle long-distance document-level word relationships. To solve the problem, we explicitly model the document-level word relationship through the graph structure, capturing the subtle information via graph neural networks. In addition, due to the complexity and scale of the document collections, it is considerable to explore the different grain-sized hierarchical matching signals at a more general level. Therefore, we propose a Graph-based Hierarchical Relevance Matching model (GHRM) for ad-hoc retrieval, by which we can capture the subtle and general hierarchical matching signals simultaneously. We validate the effects of GHRM over two representative ad-hoc retrieval benchmarks, the comprehensive experiments and results demonstrate its superiority over state-of-the-art methods.
Deep Active Graph Representation Learning
Oct 30, 2020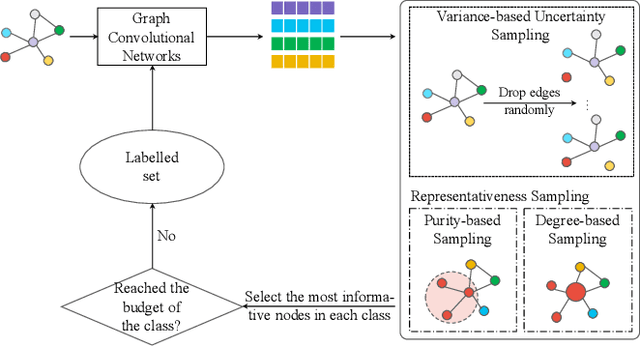
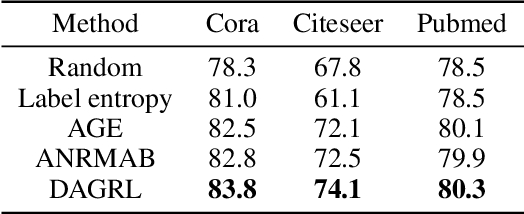
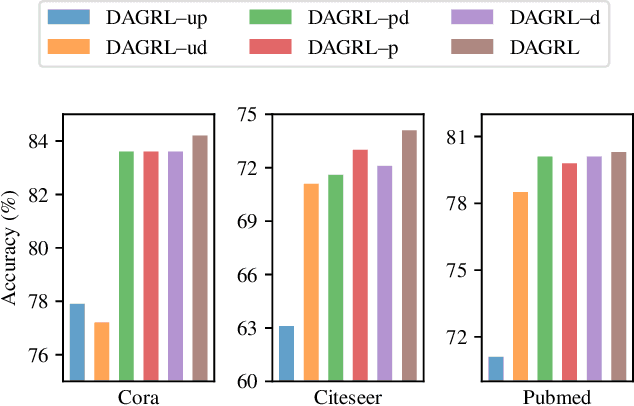
Graph neural networks (GNNs) aim to learn graph representations that preserve both attributive and structural information. In this paper, we study the problem of how to select high-quality nodes for training GNNs, considering GNNs are sensitive to different training datasets. Active learning (AL), whose purpose is to find the most informative instances to maximize the performance of the model, is a promising approach to solve this problem. Previous attempts have combined AL with graph representation learning by designing several selection criteria to measure how informative a node is. However, these methods do not directly utilize both the rich semantic and structural information and are prone to select sparsely-connected nodes (i.e. nodes having few neighbors) and low-purity nodes (i.e. nodes having noisy inter-class edges), which are less effective for training GNN models. To address these problems, we present a Deep Active Graph Representation Learning framework (DAGRL), in which three novel selection criteria are proposed. Specifically, we propose to measure the uncertainty of nodes via random topological perturbation. Besides, we propose two novel representativeness sampling criteria, which utilize both the structural and label information to find densely-connected nodes with many intra-class edges, hence enhance the performance of GNN models significantly. Then, we combine these three criteria with time-sensitive scheduling in accordance to the training progress of GNNs. Furthermore, considering the different size of classes, we employ a novel cluster-aware node selection policy, which ensures the number of selected nodes in each class is proportional to the size of the class. Comprehensive experiments on three public datasets show that our method outperforms previous baselines by a significant margin, which demonstrates its effectiveness.