 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarling: An I/O-Efficient Disk-Resident Graph Index Framework for High-Dimensional Vector Similarity Search on Data Segment
Jan 16, 2024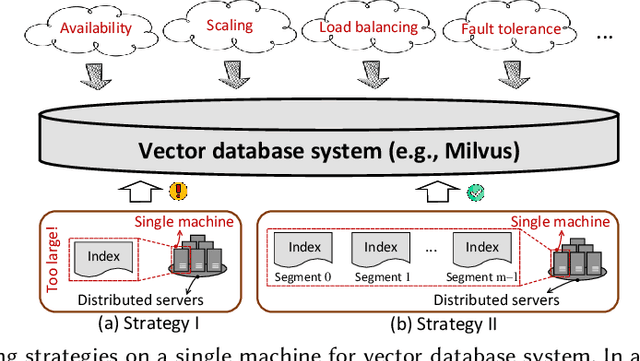

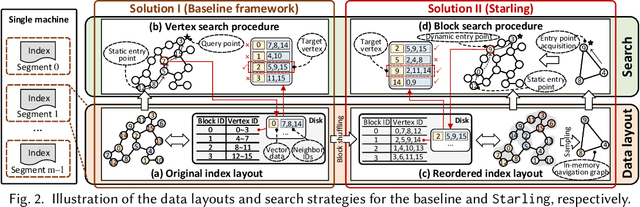

High-dimensional vector similarity search (HVSS) is gaining prominence as a powerful tool for various data science and AI applications. As vector data scales up, in-memory indexes pose a significant challenge due to the substantial increase in main memory requirements. A potential solution involves leveraging disk-based implementation, which stores and searches vector data on high-performance devices like NVMe SSDs. However, implementing HVSS for data segments proves to be intricate in vector databases where a single machine comprises multiple segments for system scalability. In this context, each segment operates with limited memory and disk space, necessitating a delicate balance between accuracy, efficiency, and space cost. Existing disk-based methods fall short as they do not holistically address all these requirements simultaneously. In this paper, we present Starling, an I/O-efficient disk-resident graph index framework that optimizes data layout and search strategy within the segment. It has two primary components: (1) a data layout incorporating an in-memory navigation graph and a reordered disk-based graph with enhanced locality, reducing the search path length and minimizing disk bandwidth wastage; and (2) a block search strategy designed to minimize costly disk I/O operations during vector query execution. Through extensive experiments, we validate the effectiveness, efficiency, and scalability of Starling. On a data segment with 2GB memory and 10GB disk capacity, Starling can accommodate up to 33 million vectors in 128 dimensions, offering HVSS with over 0.9 average precision and top-10 recall rate, and latency under 1 millisecond. The results showcase Starling's superior performance, exhibiting 43.9$\times$ higher throughput with 98% lower query latency compared to state-of-the-art methods while maintaining the same level of accuracy.