 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVikingMem: A Memory Base Management System for Stateful LLM-based Applications
May 28, 2026Large Language Models have revolutionized interactive applications; however, their finite context windows pose a critical data management challenge for maintaining stateful, long-term interactions. Existing memory approaches often rely on simplistic extraction methods that lead to incomplete memories or use rigid, single-purpose memory extraction prompts tailored to a single use case, such as chatbots. Consequently, they lack generalizability and perform poorly across diverse downstream tasks. To bridge this gap, we introduce the Memory Base, a novel data management paradigm for managing the persistent state of long-term interactions. It is characterized by three core principles: selective extraction of high-value memories from raw information streams; inherent statefulness and evolution, where memory content is progressively summarized, corrected, and temporally weighted to prioritize recent interactions; and a generalizable abstraction paradigm designed for robust transferability across diverse applications, including education, recommendation, and agent memory. Building on this foundation, we present VikingMem, an end-to-end Memory Base Management System implemented on the VikingDB vector engine. VikingMem materializes this paradigm through interconnected event and entity abstractions. It features event-centric memory extraction to selectively handle complex information streams, while entities are dynamically updated by events to achieve stateful evolution. Using temporal compression via a topic-wise timeline and time-weighted recall, the system progressively produces high-level summary memories, prioritizes recent items, and compresses and fades older ones. Extensive evaluations on long-term memory benchmarks demonstrate that VikingMem outperformes baselines by up to 30% in memory retrieval effectiveness while maintaining the low latency essential for interactive applications.
Adaptive Graph Refinement and Label Propagation with LLMs for Cost-Effective Entity Resolution
May 25, 2026Dirty entity resolution (ER), which identifies records referring to the same real-world entity from a single, messy dataset, is a fundamental task in data management and mining. However, the dominant blocking-matching-clustering paradigm for ER suffers from critical flaws. Its cascaded, decoupled workflow essentially produces a static, sparse graph plagued by missing edges (due to blocking failures) and noisy links (due to matching errors), causing error propagation and yielding suboptimal clusters, particularly when rigid transitivity is imposed in the clustering. We contend that matching and clustering are fundamentally synergistic, both optimizing for the construction of an ideal entity graph. Building upon this insight, we propose Alper, a unified framework that integrates these steps into an iterative probabilistic label propagation process over a global, evolving graph. Unlike disjoint blocking, Alper refines the graph structure and labels dynamically by adaptively integrating "weak but cheap" signals from graph propagation with "strong but expensive" LLM-based pairwise queries. For higher cost-effectiveness, we formulate the signal selection as a constrained optimization problem maximizing cumulative marginal gain under a query budget, solved via our greedy algorithm with provable theoretical guarantees. Our extensive experiments over eight benchmark datasets demonstrate that Alper is consistently superior to state-of-the-art cascaded pipelines.
Reveal Hidden Pitfalls and Navigate Next Generation of Vector Similarity Search from Task-Centric Views
Dec 15, 2025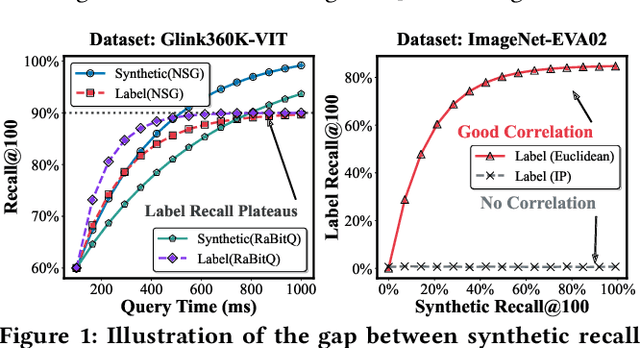

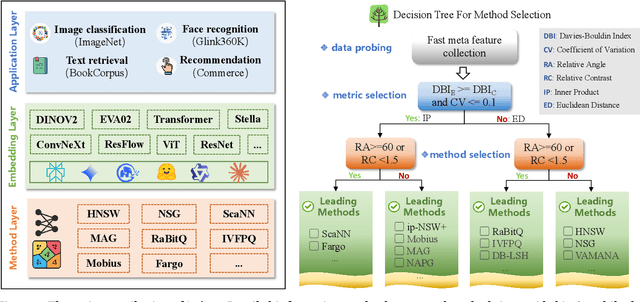
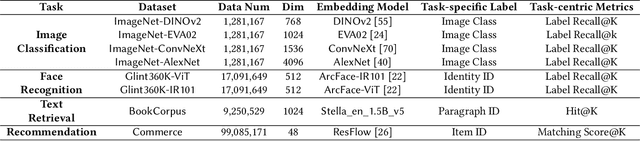
Vector Similarity Search (VSS) in high-dimensional spaces is rapidly emerging as core functionality in next-generation database systems for numerous data-intensive services -- from embedding lookups in large language models (LLMs), to semantic information retrieval and recommendation engines. Current benchmarks, however, evaluate VSS primarily on the recall-latency trade-off against a ground truth defined solely by distance metrics, neglecting how retrieval quality ultimately impacts downstream tasks. This disconnect can mislead both academic research and industrial practice. We present Iceberg, a holistic benchmark suite for end-to-end evaluation of VSS methods in realistic application contexts. From a task-centric view, Iceberg uncovers the Information Loss Funnel, which identifies three principal sources of end-to-end performance degradation: (1) Embedding Loss during feature extraction; (2) Metric Misuse, where distances poorly reflect task relevance; (3) Data Distribution Sensitivity, highlighting index robustness across skews and modalities. For a more comprehensive assessment, Iceberg spans eight diverse datasets across key domains such as image classification, face recognition, text retrieval, and recommendation systems. Each dataset, ranging from 1M to 100M vectors, includes rich, task-specific labels and evaluation metrics, enabling assessment of retrieval algorithms within the full application pipeline rather than in isolation. Iceberg benchmarks 13 state-of-the-art VSS methods and re-ranks them based on application-level metrics, revealing substantial deviations from traditional rankings derived purely from recall-latency evaluations. Building on these insights, we define a set of task-centric meta-features and derive an interpretable decision tree to guide practitioners in selecting and tuning VSS methods for their specific workloads.
Stitching Inner Product and Euclidean Metrics for Topology-aware Maximum Inner Product Search
Apr 21, 2025Maximum Inner Product Search (MIPS) is a fundamental challenge in machine learning and information retrieval, particularly in high-dimensional data applications. Existing approaches to MIPS either rely solely on Inner Product (IP) similarity, which faces issues with local optima and redundant computations, or reduce the MIPS problem to the Nearest Neighbor Search under the Euclidean metric via space projection, leading to topology destruction and information loss. Despite the divergence of the two paradigms, we argue that there is no inherent binary opposition between IP and Euclidean metrics. By stitching IP and Euclidean in the design of indexing and search algorithms, we can significantly enhance MIPS performance. Specifically, this paper explores the theoretical and empirical connections between these two metrics from the MIPS perspective. Our investigation, grounded in graph-based search, reveals that different indexing and search strategies offer distinct advantages for MIPS, depending on the underlying data topology. Building on these insights, we introduce a novel graph-based index called Metric-Amphibious Graph (MAG) and a corresponding search algorithm, Adaptive Navigation with Metric Switch (ANMS). To facilitate parameter tuning for optimal performance, we identify three statistical indicators that capture essential data topology properties and correlate strongly with parameter tuning. Extensive experiments on 12 real-world datasets demonstrate that MAG outperforms existing state-of-the-art methods, achieving up to 4x search speedup while maintaining adaptability and scalability.
Spectral Subspace Clustering for Attributed Graphs
Nov 17, 2024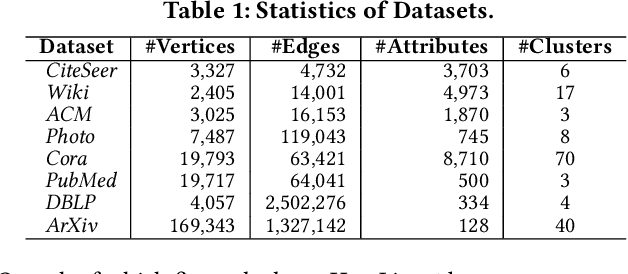
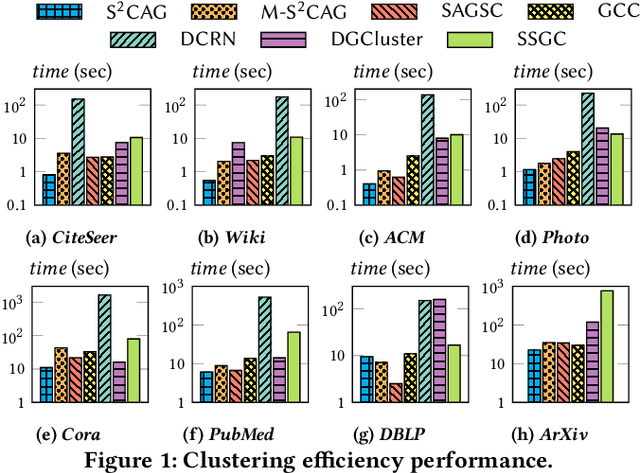
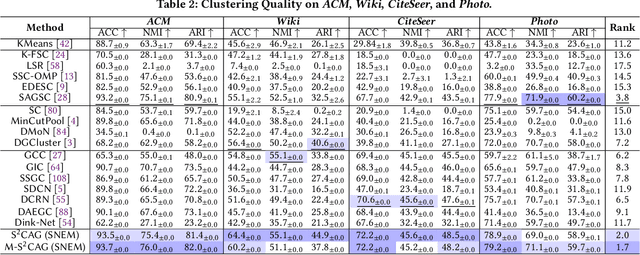
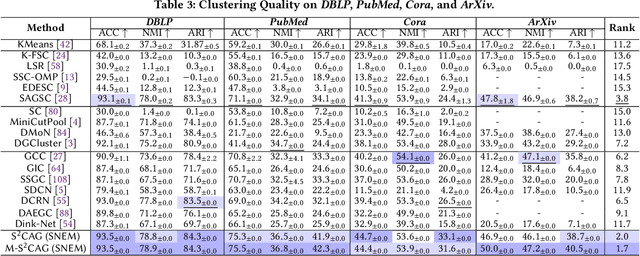
Subspace clustering seeks to identify subspaces that segment a set of n data points into k (k<<n) groups, which has emerged as a powerful tool for analyzing data from various domains, especially images and videos. Recently, several studies have demonstrated the great potential of subspace clustering models for partitioning vertices in attributed graphs, referred to as SCAG. However, these works either demand significant computational overhead for constructing the nxn self-expressive matrix, or fail to incorporate graph topology and attribute data into the subspace clustering framework effectively, and thus, compromise result quality. Motivated by this, this paper presents two effective and efficient algorithms, S2CAG and M-S2CAG, for SCAG computation. Particularly, S2CAG obtains superb performance through three major contributions. First, we formulate a new objective function for SCAG with a refined representation model for vertices and two non-trivial constraints. On top of that, an efficient linear-time optimization solver is developed based on our theoretically grounded problem transformation and well-thought-out adaptive strategy. We then conduct an in-depth analysis to disclose the theoretical connection of S2CAG to conductance minimization, which further inspires the design of M-S2CAG that maximizes the modularity. Our extensive experiments, comparing S2CAG and M-S2CAG against 17 competitors over 8 benchmark datasets, exhibit that our solutions outperform all baselines in terms of clustering quality measured against the ground truth while delivering high efficiency
An Interactive Multi-modal Query Answering System with Retrieval-Augmented Large Language Models
Jul 05, 2024
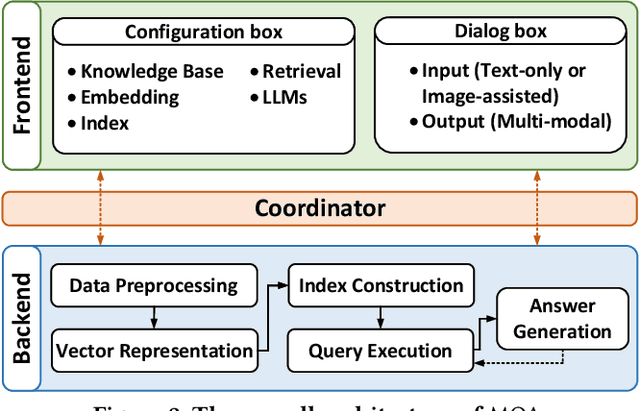
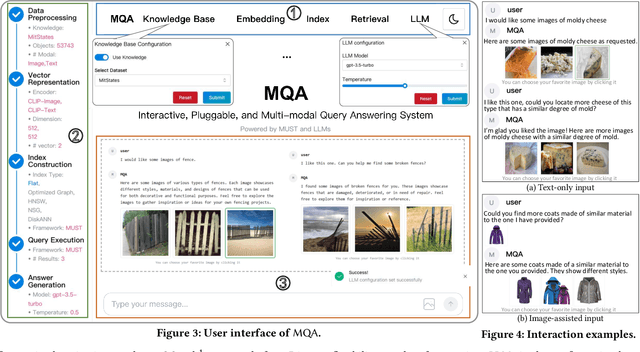

Retrieval-augmented Large Language Models (LLMs) have reshaped traditional query-answering systems, offering unparalleled user experiences. However, existing retrieval techniques often struggle to handle multi-modal query contexts. In this paper, we present an interactive Multi-modal Query Answering (MQA) system, empowered by our newly developed multi-modal retrieval framework and navigation graph index, integrated with cutting-edge LLMs. It comprises five core components: Data Preprocessing, Vector Representation, Index Construction, Query Execution, and Answer Generation, all orchestrated by a dedicated coordinator to ensure smooth data flow from input to answer generation. One notable aspect of MQA is its utilization of contrastive learning to assess the significance of different modalities, facilitating precise measurement of multi-modal information similarity. Furthermore, the system achieves efficient retrieval through our advanced navigation graph index, refined using computational pruning techniques. Another highlight of our system is its pluggable processing framework, allowing seamless integration of embedding models, graph indexes, and LLMs. This flexibility provides users diverse options for gaining insights from their multi-modal knowledge base. A preliminary video introduction of MQA is available at https://youtu.be/xvUuo2ZIqWk.
A Benchmark Study of Deep-RL Methods for Maximum Coverage Problems over Graphs
Jun 20, 2024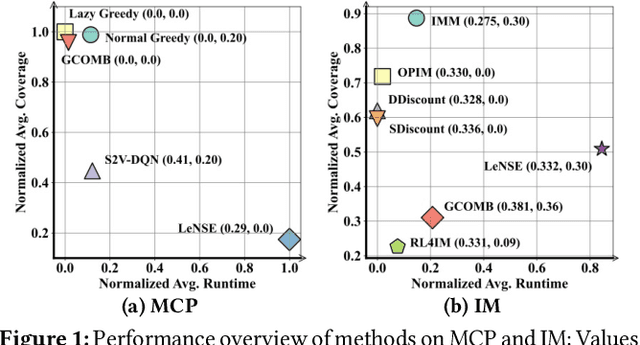
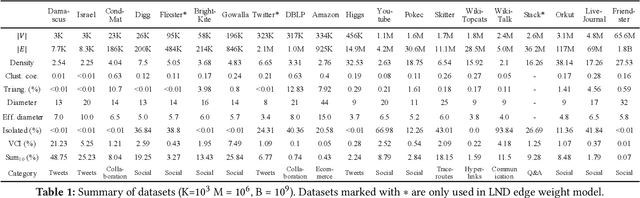
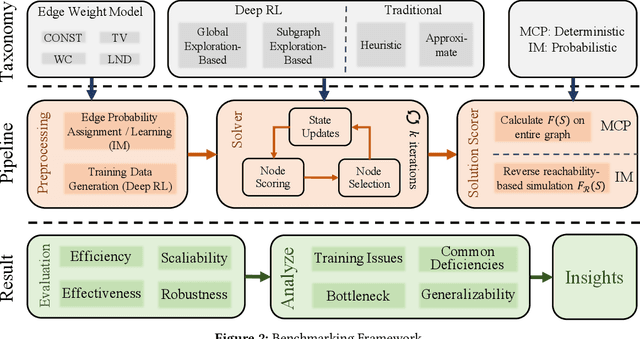
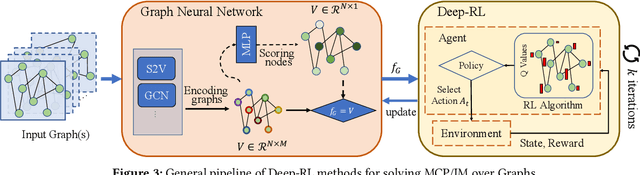
Recent years have witnessed a growing trend toward employing deep reinforcement learning (Deep-RL) to derive heuristics for combinatorial optimization (CO) problems on graphs. Maximum Coverage Problem (MCP) and its probabilistic variant on social networks, Influence Maximization (IM), have been particularly prominent in this line of research. In this paper, we present a comprehensive benchmark study that thoroughly investigates the effectiveness and efficiency of five recent Deep-RL methods for MCP and IM. These methods were published in top data science venues, namely S2V-DQN, Geometric-QN, GCOMB, RL4IM, and LeNSE. Our findings reveal that, across various scenarios, the Lazy Greedy algorithm consistently outperforms all Deep-RL methods for MCP. In the case of IM, theoretically sound algorithms like IMM and OPIM demonstrate superior performance compared to Deep-RL methods in most scenarios. Notably, we observe an abnormal phenomenon in IM problem where Deep-RL methods slightly outperform IMM and OPIM when the influence spread nearly does not increase as the budget increases. Furthermore, our experimental results highlight common issues when applying Deep-RL methods to MCP and IM in practical settings. Finally, we discuss potential avenues for improving Deep-RL methods. Our benchmark study sheds light on potential challenges in current deep reinforcement learning research for solving combinatorial optimization problems.
Starling: An I/O-Efficient Disk-Resident Graph Index Framework for High-Dimensional Vector Similarity Search on Data Segment
Jan 16, 2024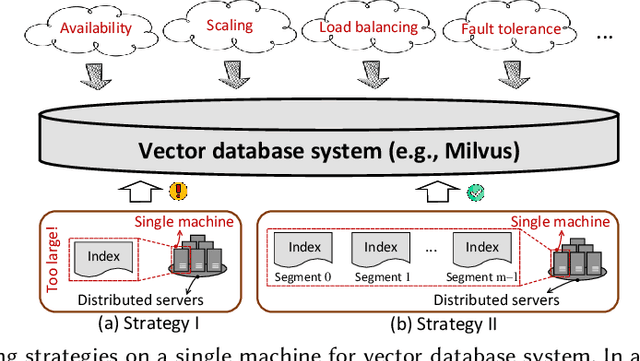

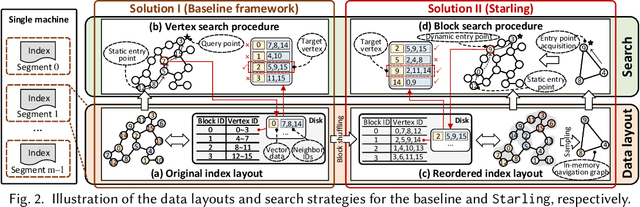

High-dimensional vector similarity search (HVSS) is gaining prominence as a powerful tool for various data science and AI applications. As vector data scales up, in-memory indexes pose a significant challenge due to the substantial increase in main memory requirements. A potential solution involves leveraging disk-based implementation, which stores and searches vector data on high-performance devices like NVMe SSDs. However, implementing HVSS for data segments proves to be intricate in vector databases where a single machine comprises multiple segments for system scalability. In this context, each segment operates with limited memory and disk space, necessitating a delicate balance between accuracy, efficiency, and space cost. Existing disk-based methods fall short as they do not holistically address all these requirements simultaneously. In this paper, we present Starling, an I/O-efficient disk-resident graph index framework that optimizes data layout and search strategy within the segment. It has two primary components: (1) a data layout incorporating an in-memory navigation graph and a reordered disk-based graph with enhanced locality, reducing the search path length and minimizing disk bandwidth wastage; and (2) a block search strategy designed to minimize costly disk I/O operations during vector query execution. Through extensive experiments, we validate the effectiveness, efficiency, and scalability of Starling. On a data segment with 2GB memory and 10GB disk capacity, Starling can accommodate up to 33 million vectors in 128 dimensions, offering HVSS with over 0.9 average precision and top-10 recall rate, and latency under 1 millisecond. The results showcase Starling's superior performance, exhibiting 43.9$\times$ higher throughput with 98% lower query latency compared to state-of-the-art methods while maintaining the same level of accuracy.
View-based Explanations for Graph Neural Networks
Jan 08, 2024



Generating explanations for graph neural networks (GNNs) has been studied to understand their behavior in analytical tasks such as graph classification. Existing approaches aim to understand the overall results of GNNs rather than providing explanations for specific class labels of interest, and may return explanation structures that are hard to access, nor directly queryable.We propose GVEX, a novel paradigm that generates Graph Views for EXplanation. (1) We design a two-tier explanation structure called explanation views. An explanation view consists of a set of graph patterns and a set of induced explanation subgraphs. Given a database G of multiple graphs and a specific class label l assigned by a GNN-based classifier M, it concisely describes the fraction of G that best explains why l is assigned by M. (2) We propose quality measures and formulate an optimization problem to compute optimal explanation views for GNN explanation. We show that the problem is $\Sigma^2_P$-hard. (3) We present two algorithms. The first one follows an explain-and-summarize strategy that first generates high-quality explanation subgraphs which best explain GNNs in terms of feature influence maximization, and then performs a summarization step to generate patterns. We show that this strategy provides an approximation ratio of 1/2. Our second algorithm performs a single-pass to an input node stream in batches to incrementally maintain explanation views, having an anytime quality guarantee of 1/4 approximation. Using real-world benchmark data, we experimentally demonstrate the effectiveness, efficiency, and scalability of GVEX. Through case studies, we showcase the practical applications of GVEX.
MUST: An Effective and Scalable Framework for Multimodal Search of Target Modality
Dec 11, 2023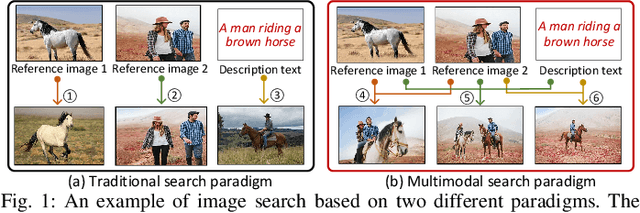
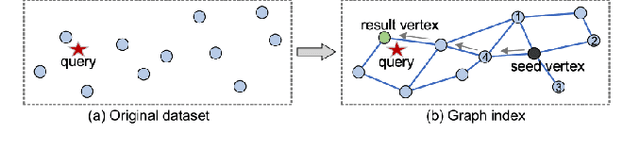
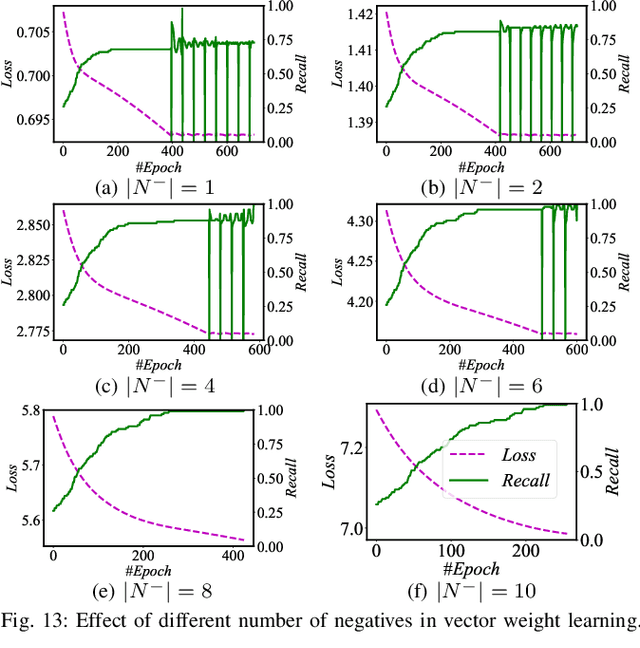
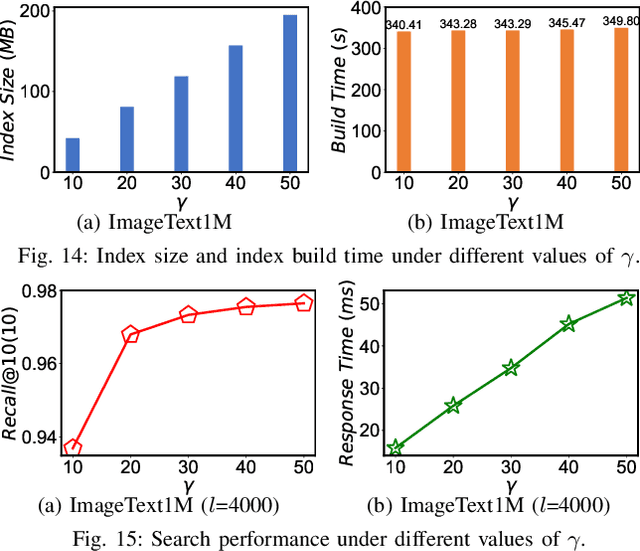
We investigate the problem of multimodal search of target modality, where the task involves enhancing a query in a specific target modality by integrating information from auxiliary modalities. The goal is to retrieve relevant objects whose contents in the target modality match the specified multimodal query. The paper first introduces two baseline approaches that integrate techniques from the Database, Information Retrieval, and Computer Vision communities. These baselines either merge the results of separate vector searches for each modality or perform a single-channel vector search by fusing all modalities. However, both baselines have limitations in terms of efficiency and accuracy as they fail to adequately consider the varying importance of fusing information across modalities. To overcome these limitations, the paper proposes a novel framework, called MUST. Our framework employs a hybrid fusion mechanism, combining different modalities at multiple stages. Notably, we leverage vector weight learning to determine the importance of each modality, thereby enhancing the accuracy of joint similarity measurement. Additionally, the proposed framework utilizes a fused proximity graph index, enabling efficient joint search for multimodal queries. MUST offers several other advantageous properties, including pluggable design to integrate any advanced embedding techniques, user flexibility to customize weight preferences, and modularized index construction. Extensive experiments on real-world datasets demonstrate the superiority of MUST over the baselines in terms of both search accuracy and efficiency. Our framework achieves over 10x faster search times while attaining an average of 93% higher accuracy. Furthermore, MUST exhibits scalability to datasets containing more than 10 million data elements.