 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Faceted Continual Knowledge Graph Embedding for Semantic-Aware Link Prediction
Apr 13, 2026Continual Knowledge Graph Embedding (CKGE) aims to continually learn embeddings for new knowledge, i.e., entities and relations, while retaining previously acquired knowledge. Most existing CKGE methods mitigate catastrophic forgetting via regularization or replaying old knowledge. They conflate new and old knowledge of an entity within the same embedding space to seek a balance between them. However, entities inherently exhibit multi-faceted semantics that evolve dynamically as their relational contexts change over time. A shared embedding fails to capture and distinguish these temporal semantic variations, degrading lifelong link prediction accuracy across snapshots. To address this, we propose a Multi-Faceted CKGE framework (MF-CKGE) for semantic-aware link prediction. During offline learning, MF-CKGE separates temporal old and new knowledge into distinct embedding spaces to prevent knowledge entanglement and employs semantic decoupling to reduce semantic redundancy, thereby improving space efficiency. During online inference, MF-CKGE adaptively identifies semantically query-relevant entity embeddings by quantifying their semantic importance, reducing interference from query-irrelevant noise. Experiments on eight datasets show that MF-CKGE achieves an average (maximum) improvement of 1.7% (2.7%) and 1.4% (3.8%) in MRR and Hits@10, respectively, over the best baseline. Our source code and datasets are available at: https://anonymous.4open.science/r/MF-CKGE-04E5.
Graph Similarity Computation via Interpretable Neural Node Alignment
Dec 13, 2024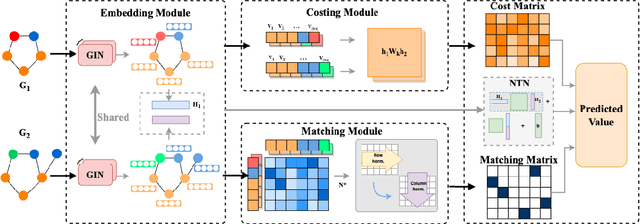

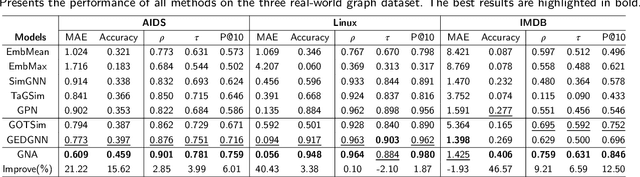
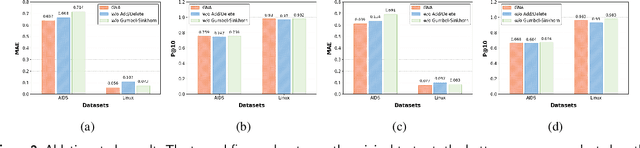
\Graph similarity computation is an essential task in many real-world graph-related applications such as retrieving the similar drugs given a query chemical compound or finding the user's potential friends from the social network database. Graph Edit Distance (GED) and Maximum Common Subgraphs (MCS) are the two commonly used domain-agnostic metrics to evaluate graph similarity in practice. Unfortunately, computing the exact GED is known to be a NP-hard problem. To solve this limitation, neural network based models have been proposed to approximate the calculations of GED/MCS. However, deep learning models are well-known ``black boxes'', thus the typically characteristic one-to-one node/subgraph alignment process in the classical computations of GED and MCS cannot be seen. Existing methods have paid attention to approximating the node/subgraph alignment (soft alignment), but the one-to-one node alignment (hard alignment) has not yet been solved. To fill this gap, in this paper we propose a novel interpretable neural node alignment model without relying on node alignment ground truth information. Firstly, the quadratic assignment problem in classical GED computation is relaxed to a linear alignment via embedding the features in the node embedding space. Secondly, a differentiable Gumbel-Sinkhorn module is proposed to unsupervised generate the optimal one-to-one node alignment matrix. Experimental results in real-world graph datasets demonstrate that our method outperforms the state-of-the-art methods in graph similarity computation and graph retrieval tasks, achieving up to 16\% reduction in the Mean Squared Error and up to 12\% improvement in the retrieval evaluation metrics, respectively.
Cross-composition Feature Disentanglement for Compositional Zero-shot Learning
Aug 19, 2024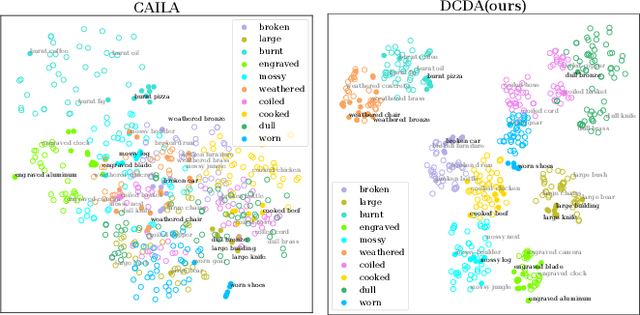
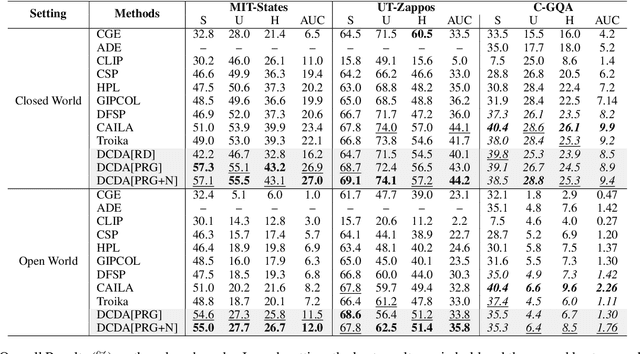
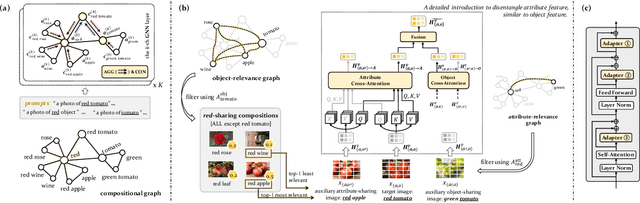
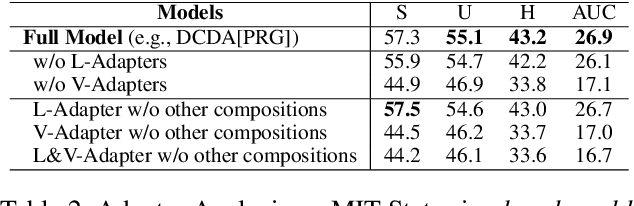
Disentanglement of visual features of primitives (i.e., attributes and objects) has shown exceptional results in Compositional Zero-shot Learning (CZSL). However, due to the feature divergence of an attribute (resp. object) when combined with different objects (resp. attributes), it is challenging to learn disentangled primitive features that are general across different compositions. To this end, we propose the solution of cross-composition feature disentanglement, which takes multiple primitive-sharing compositions as inputs and constrains the disentangled primitive features to be general across these compositions. More specifically, we leverage a compositional graph to define the overall primitive-sharing relationships between compositions, and build a task-specific architecture upon the recently successful large pre-trained vision-language model (VLM) CLIP, with dual cross-composition disentangling adapters (called L-Adapter and V-Adapter) inserted into CLIP's frozen text and image encoders, respectively. Evaluation on three popular CZSL benchmarks shows that our proposed solution significantly improves the performance of CZSL, and its components have been verified by solid ablation studies.
An Interactive Multi-modal Query Answering System with Retrieval-Augmented Large Language Models
Jul 05, 2024
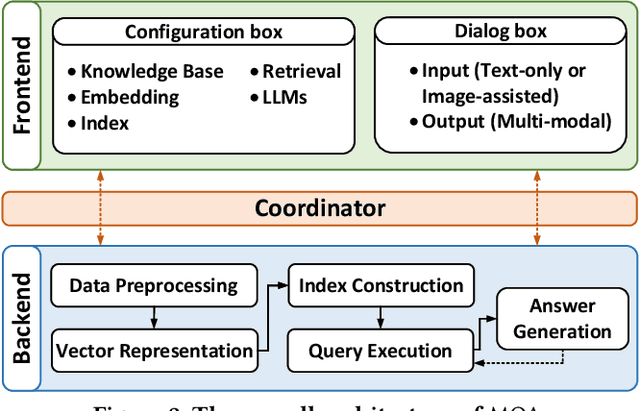
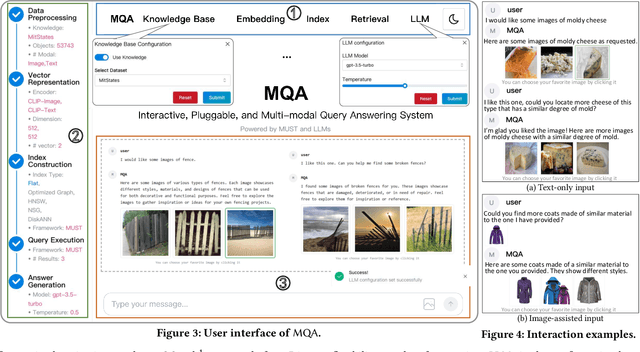

Retrieval-augmented Large Language Models (LLMs) have reshaped traditional query-answering systems, offering unparalleled user experiences. However, existing retrieval techniques often struggle to handle multi-modal query contexts. In this paper, we present an interactive Multi-modal Query Answering (MQA) system, empowered by our newly developed multi-modal retrieval framework and navigation graph index, integrated with cutting-edge LLMs. It comprises five core components: Data Preprocessing, Vector Representation, Index Construction, Query Execution, and Answer Generation, all orchestrated by a dedicated coordinator to ensure smooth data flow from input to answer generation. One notable aspect of MQA is its utilization of contrastive learning to assess the significance of different modalities, facilitating precise measurement of multi-modal information similarity. Furthermore, the system achieves efficient retrieval through our advanced navigation graph index, refined using computational pruning techniques. Another highlight of our system is its pluggable processing framework, allowing seamless integration of embedding models, graph indexes, and LLMs. This flexibility provides users diverse options for gaining insights from their multi-modal knowledge base. A preliminary video introduction of MQA is available at https://youtu.be/xvUuo2ZIqWk.
Starling: An I/O-Efficient Disk-Resident Graph Index Framework for High-Dimensional Vector Similarity Search on Data Segment
Jan 16, 2024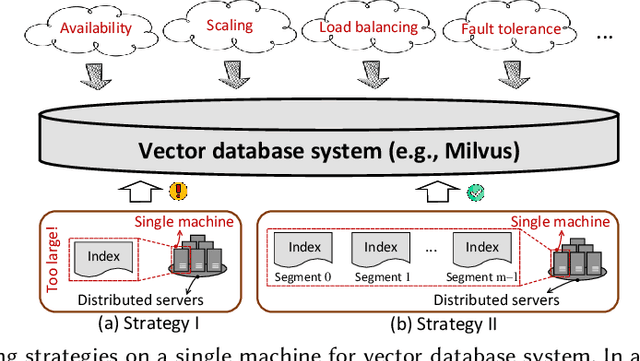

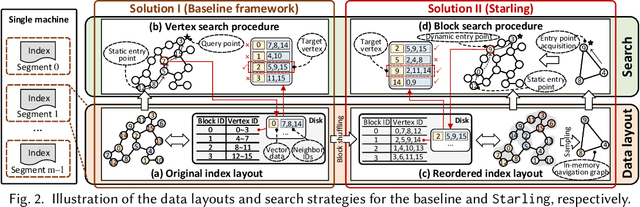

High-dimensional vector similarity search (HVSS) is gaining prominence as a powerful tool for various data science and AI applications. As vector data scales up, in-memory indexes pose a significant challenge due to the substantial increase in main memory requirements. A potential solution involves leveraging disk-based implementation, which stores and searches vector data on high-performance devices like NVMe SSDs. However, implementing HVSS for data segments proves to be intricate in vector databases where a single machine comprises multiple segments for system scalability. In this context, each segment operates with limited memory and disk space, necessitating a delicate balance between accuracy, efficiency, and space cost. Existing disk-based methods fall short as they do not holistically address all these requirements simultaneously. In this paper, we present Starling, an I/O-efficient disk-resident graph index framework that optimizes data layout and search strategy within the segment. It has two primary components: (1) a data layout incorporating an in-memory navigation graph and a reordered disk-based graph with enhanced locality, reducing the search path length and minimizing disk bandwidth wastage; and (2) a block search strategy designed to minimize costly disk I/O operations during vector query execution. Through extensive experiments, we validate the effectiveness, efficiency, and scalability of Starling. On a data segment with 2GB memory and 10GB disk capacity, Starling can accommodate up to 33 million vectors in 128 dimensions, offering HVSS with over 0.9 average precision and top-10 recall rate, and latency under 1 millisecond. The results showcase Starling's superior performance, exhibiting 43.9$\times$ higher throughput with 98% lower query latency compared to state-of-the-art methods while maintaining the same level of accuracy.
MUST: An Effective and Scalable Framework for Multimodal Search of Target Modality
Dec 11, 2023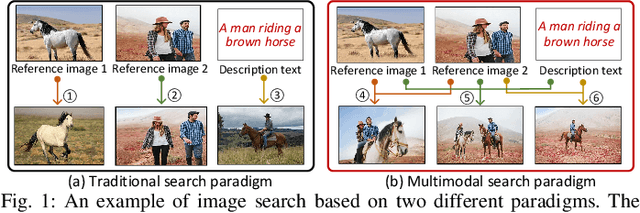
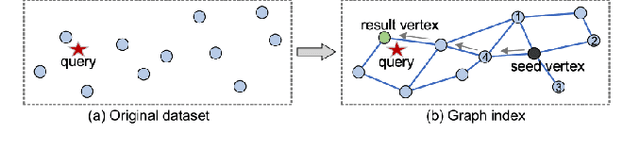
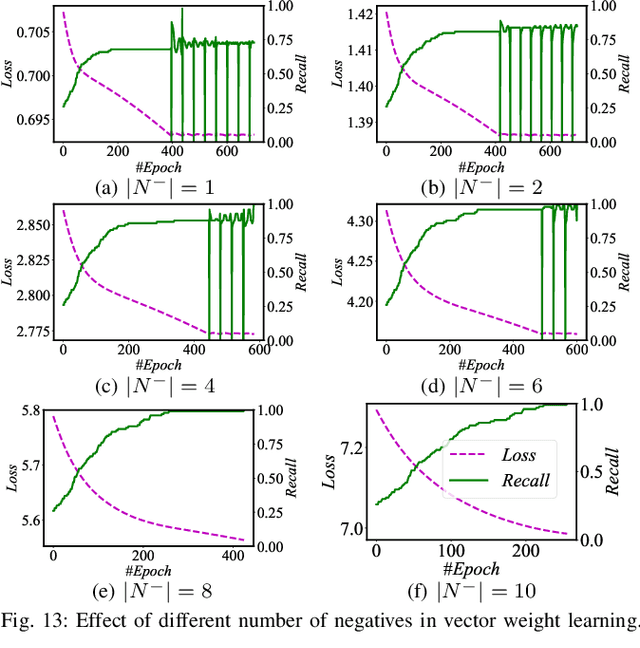
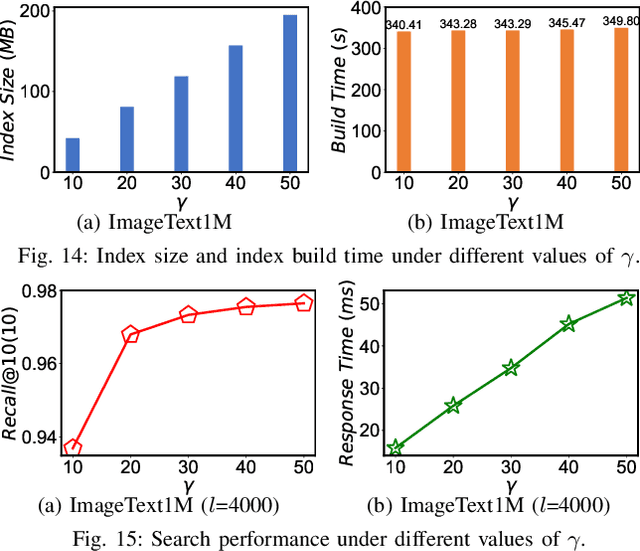
We investigate the problem of multimodal search of target modality, where the task involves enhancing a query in a specific target modality by integrating information from auxiliary modalities. The goal is to retrieve relevant objects whose contents in the target modality match the specified multimodal query. The paper first introduces two baseline approaches that integrate techniques from the Database, Information Retrieval, and Computer Vision communities. These baselines either merge the results of separate vector searches for each modality or perform a single-channel vector search by fusing all modalities. However, both baselines have limitations in terms of efficiency and accuracy as they fail to adequately consider the varying importance of fusing information across modalities. To overcome these limitations, the paper proposes a novel framework, called MUST. Our framework employs a hybrid fusion mechanism, combining different modalities at multiple stages. Notably, we leverage vector weight learning to determine the importance of each modality, thereby enhancing the accuracy of joint similarity measurement. Additionally, the proposed framework utilizes a fused proximity graph index, enabling efficient joint search for multimodal queries. MUST offers several other advantageous properties, including pluggable design to integrate any advanced embedding techniques, user flexibility to customize weight preferences, and modularized index construction. Extensive experiments on real-world datasets demonstrate the superiority of MUST over the baselines in terms of both search accuracy and efficiency. Our framework achieves over 10x faster search times while attaining an average of 93% higher accuracy. Furthermore, MUST exhibits scalability to datasets containing more than 10 million data elements.
Prompting Disentangled Embeddings for Knowledge Graph Completion with Pre-trained Language Model
Dec 04, 2023



Both graph structures and textual information play a critical role in Knowledge Graph Completion (KGC). With the success of Pre-trained Language Models (PLMs) such as BERT, they have been applied for text encoding for KGC. However, the current methods mostly prefer to fine-tune PLMs, leading to huge training costs and limited scalability to larger PLMs. In contrast, we propose to utilize prompts and perform KGC on a frozen PLM with only the prompts trained. Accordingly, we propose a new KGC method named PDKGC with two prompts -- a hard task prompt which is to adapt the KGC task to the PLM pre-training task of token prediction, and a disentangled structure prompt which learns disentangled graph representation so as to enable the PLM to combine more relevant structure knowledge with the text information. With the two prompts, PDKGC builds a textual predictor and a structural predictor, respectively, and their combination leads to more comprehensive entity prediction. Solid evaluation on two widely used KGC datasets has shown that PDKGC often outperforms the baselines including the state-of-the-art, and its components are all effective. Our codes and data are available at https://github.com/genggengcss/PDKGC.
Routing-Guided Learned Product Quantization for Graph-Based Approximate Nearest Neighbor Search
Nov 30, 2023Given a vector dataset $\mathcal{X}$, a query vector $\vec{x}_q$, graph-based Approximate Nearest Neighbor Search (ANNS) aims to build a proximity graph (PG) as an index of $\mathcal{X}$ and approximately return vectors with minimum distances to $\vec{x}_q$ by searching over the PG index. It suffers from the large-scale $\mathcal{X}$ because a PG with full vectors is too large to fit into the memory, e.g., a billion-scale $\mathcal{X}$ in 128 dimensions would consume nearly 600 GB memory. To solve this, Product Quantization (PQ) integrated graph-based ANNS is proposed to reduce the memory usage, using smaller compact codes of quantized vectors in memory instead of the large original vectors. Existing PQ methods do not consider the important routing features of PG, resulting in low-quality quantized vectors that affect the ANNS's effectiveness. In this paper, we present an end-to-end Routing-guided learned Product Quantization (RPQ) for graph-based ANNS. It consists of (1) a \textit{differentiable quantizer} used to make the standard discrete PQ differentiable to suit for back-propagation of end-to-end learning, (2) a \textit{sampling-based feature extractor} used to extract neighborhood and routing features of a PG, and (3) a \textit{multi-feature joint training module} with two types of feature-aware losses to continuously optimize the differentiable quantizer. As a result, the inherent features of a PG would be embedded into the learned PQ, generating high-quality quantized vectors. Moreover, we integrate our RPQ with the state-of-the-art DiskANN and existing popular PGs to improve their performance. Comprehensive experiments on real-world large-scale datasets (from 1M to 1B) demonstrate RPQ's superiority, e.g., 1.7$\times$-4.2$\times$ improvement on QPS at the same recall@10 of 95\%.
DiskANN++: Efficient Page-based Search over Isomorphic Mapped Graph Index using Query-sensitivity Entry Vertex
Sep 30, 2023Given a vector dataset $\mathcal{X}$ and a query vector $\vec{x}_q$, graph-based Approximate Nearest Neighbor Search (ANNS) aims to build a graph index $G$ and approximately return vectors with minimum distances to $\vec{x}_q$ by searching over $G$. The main drawback of graph-based ANNS is that a graph index would be too large to fit into the memory especially for a large-scale $\mathcal{X}$. To solve this, a Product Quantization (PQ)-based hybrid method called DiskANN is proposed to store a low-dimensional PQ index in memory and retain a graph index in SSD, thus reducing memory overhead while ensuring a high search accuracy. However, it suffers from two I/O issues that significantly affect the overall efficiency: (1) long routing path from an entry vertex to the query's neighborhood that results in large number of I/O requests and (2) redundant I/O requests during the routing process. We propose an optimized DiskANN++ to overcome above issues. Specifically, for the first issue, we present a query-sensitive entry vertex selection strategy to replace DiskANN's static graph-central entry vertex by a dynamically determined entry vertex that is close to the query. For the second I/O issue, we present an isomorphic mapping on DiskANN's graph index to optimize the SSD layout and propose an asynchronously optimized Pagesearch based on the optimized SSD layout as an alternative to DiskANN's beamsearch. Comprehensive experimental studies on eight real-world datasets demonstrate our DiskANN++'s superiority on efficiency. We achieve a notable 1.5 X to 2.2 X improvement on QPS compared to DiskANN, given the same accuracy constraint.
Navigable Proximity Graph-Driven Native Hybrid Queries with Structured and Unstructured Constraints
Mar 25, 2022

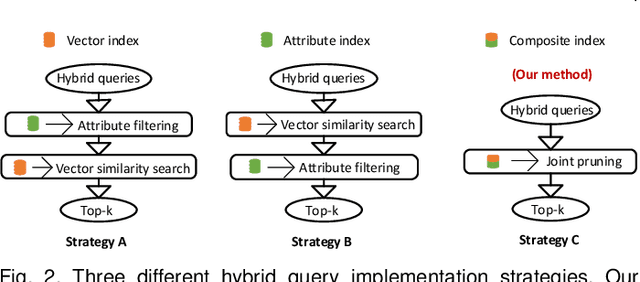
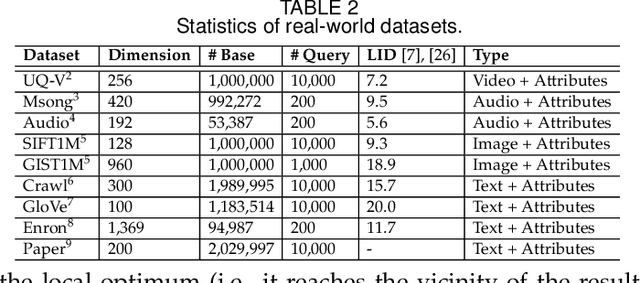
As research interest surges, vector similarity search is applied in multiple fields, including data mining, computer vision, and information retrieval. {Given a set of objects (e.g., a set of images) and a query object, we can easily transform each object into a feature vector and apply the vector similarity search to retrieve the most similar objects. However, the original vector similarity search cannot well support \textit{hybrid queries}, where users not only input unstructured query constraint (i.e., the feature vector of query object) but also structured query constraint (i.e., the desired attributes of interest). Hybrid query processing aims at identifying these objects with similar feature vectors to query object and satisfying the given attribute constraints. Recent efforts have attempted to answer a hybrid query by performing attribute filtering and vector similarity search separately and then merging the results later, which limits efficiency and accuracy because they are not purpose-built for hybrid queries.} In this paper, we propose a native hybrid query (NHQ) framework based on proximity graph (PG), which provides the specialized \textit{composite index and joint pruning} modules for hybrid queries. We easily deploy existing various PGs on this framework to process hybrid queries efficiently. Moreover, we present two novel navigable PGs (NPGs) with optimized edge selection and routing strategies, which obtain better overall performance than existing PGs. After that, we deploy the proposed NPGs in NHQ to form two hybrid query methods, which significantly outperform the state-of-the-art competitors on all experimental datasets (10$\times$ faster under the same \textit{Recall}), including eight public and one in-house real-world datasets. Our code and datasets have been released at \url{https://github.com/AshenOn3/NHQ}.