 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deployment Audit of Release-Side Risk in Conformal Triage under Prevalence Shift
May 20, 2026Conformal triage converts predictive scores into deployment actions that either release a case, flag it for urgent attention, or defer it to human review. Under prevalence shift, however, the usual summaries of marginal coverage and human-review rate can miss the safety-critical question of whether patients who truly experience the target event are released without review. To address this gap, we introduce a leakage-aware deployment audit for release-side conformal triage. It first assigns target subjects to three non-overlapping roles: prevalence correction, conformal calibration, and held-out release-safety evaluation. This separation then lets the audit evaluate release directly: how many event-positive patients are cleared without review, whether the pilot has enough event labels for calibration, and how the safety-review trade-off shifts. Applying this audit to a retrospective NSCLC pilot shows why lower review can be misleading: after prevalence correction, the pooled conformal branch lowers review by releasing more patients, some of whom are event-positive. Within the audit, the classwise branch acts as a scarcity diagnostic: the pilot has too few event labels to certify safe low-review release.
Leveraging Implicit Sentiments: Enhancing Reliability and Validity in Psychological Trait Evaluation of LLMs
Mar 26, 2025Recent advancements in Large Language Models (LLMs) have led to their increasing integration into human life. With the transition from mere tools to human-like assistants, understanding their psychological aspects-such as emotional tendencies and personalities-becomes essential for ensuring their trustworthiness. However, current psychological evaluations of LLMs, often based on human psychological assessments like the BFI, face significant limitations. The results from these approaches often lack reliability and have limited validity when predicting LLM behavior in real-world scenarios. In this work, we introduce a novel evaluation instrument specifically designed for LLMs, called Core Sentiment Inventory (CSI). CSI is a bilingual tool, covering both English and Chinese, that implicitly evaluates models' sentiment tendencies, providing an insightful psychological portrait of LLM across three dimensions: optimism, pessimism, and neutrality. Through extensive experiments, we demonstrate that: 1) CSI effectively captures nuanced emotional patterns, revealing significant variation in LLMs across languages and contexts; 2) Compared to current approaches, CSI significantly improves reliability, yielding more consistent results; and 3) The correlation between CSI scores and the sentiment of LLM's real-world outputs exceeds 0.85, demonstrating its strong validity in predicting LLM behavior. We make CSI public available via: https://github.com/dependentsign/CSI.
Training Data for Large Language Model
Nov 12, 2024In 2022, with the release of ChatGPT, large-scale language models gained widespread attention. ChatGPT not only surpassed previous models in terms of parameters and the scale of its pretraining corpus but also achieved revolutionary performance improvements through fine-tuning on a vast amount of high-quality, human-annotated data. This progress has led enterprises and research institutions to recognize that building smarter and more powerful models relies on rich and high-quality datasets. Consequently, the construction and optimization of datasets have become a critical focus in the field of artificial intelligence. This paper summarizes the current state of pretraining and fine-tuning data for training large-scale language models, covering aspects such as data scale, collection methods, data types and characteristics, processing workflows, and provides an overview of available open-source datasets.
Does Knowledge Localization Hold True? Surprising Differences Between Entity and Relation Perspectives in Language Models
Sep 01, 2024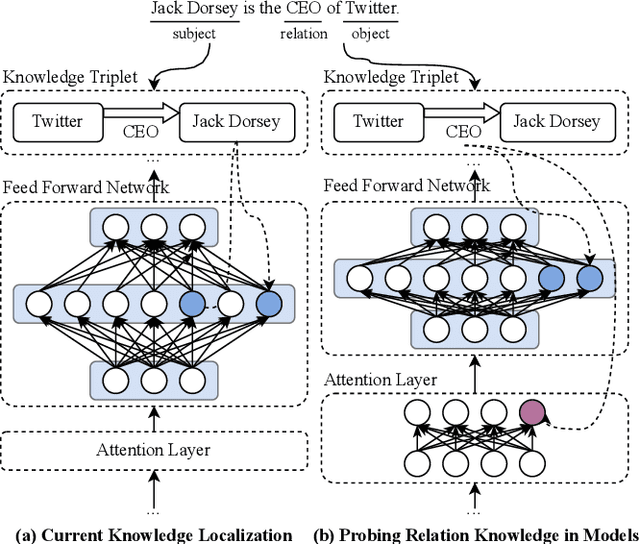
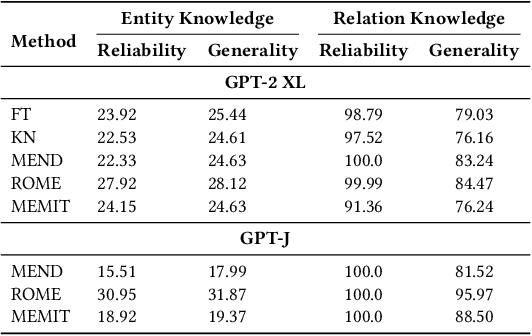

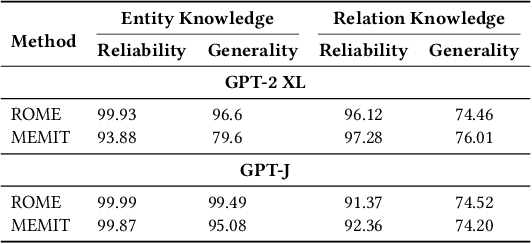
Large language models encapsulate knowledge and have demonstrated superior performance on various natural language processing tasks. Recent studies have localized this knowledge to specific model parameters, such as the MLP weights in intermediate layers. This study investigates the differences between entity and relational knowledge through knowledge editing. Our findings reveal that entity and relational knowledge cannot be directly transferred or mapped to each other. This result is unexpected, as logically, modifying the entity or the relation within the same knowledge triplet should yield equivalent outcomes. To further elucidate the differences between entity and relational knowledge, we employ causal analysis to investigate how relational knowledge is stored in pre-trained models. Contrary to prior research suggesting that knowledge is stored in MLP weights, our experiments demonstrate that relational knowledge is also significantly encoded in attention modules. This insight highlights the multifaceted nature of knowledge storage in language models, underscoring the complexity of manipulating specific types of knowledge within these models.
Navigating the Noisy Crowd: Finding Key Information for Claim Verification
Jul 17, 2024



Claim verification is a task that involves assessing the truthfulness of a given claim based on multiple evidence pieces. Using large language models (LLMs) for claim verification is a promising way. However, simply feeding all the evidence pieces to an LLM and asking if the claim is factual does not yield good results. The challenge lies in the noisy nature of both the evidence and the claim: evidence passages typically contain irrelevant information, with the key facts hidden within the context, while claims often convey multiple aspects simultaneously. To navigate this "noisy crowd" of information, we propose EACon (Evidence Abstraction and Claim Deconstruction), a framework designed to find key information within evidence and verify each aspect of a claim separately. EACon first finds keywords from the claim and employs fuzzy matching to select relevant keywords for each raw evidence piece. These keywords serve as a guide to extract and summarize critical information into abstracted evidence. Subsequently, EACon deconstructs the original claim into subclaims, which are then verified against both abstracted and raw evidence individually. We evaluate EACon using two open-source LLMs on two challenging datasets. Results demonstrate that EACon consistently and substantially improve LLMs' performance in claim verification.
Interpretable Multimodal Out-of-context Detection with Soft Logic Regularization
Jun 07, 2024


The rapid spread of information through mobile devices and media has led to the widespread of false or deceptive news, causing significant concerns in society. Among different types of misinformation, image repurposing, also known as out-of-context misinformation, remains highly prevalent and effective. However, current approaches for detecting out-of-context misinformation often lack interpretability and offer limited explanations. In this study, we propose a logic regularization approach for out-of-context detection called LOGRAN (LOGic Regularization for out-of-context ANalysis). The primary objective of LOGRAN is to decompose the out-of-context detection at the phrase level. By employing latent variables for phrase-level predictions, the final prediction of the image-caption pair can be aggregated using logical rules. The latent variables also provide an explanation for how the final result is derived, making this fine-grained detection method inherently explanatory. We evaluate the performance of LOGRAN on the NewsCLIPpings dataset, showcasing competitive overall results. Visualized examples also reveal faithful phrase-level predictions of out-of-context images, accompanied by explanations. This highlights the effectiveness of our approach in addressing out-of-context detection and enhancing interpretability.
Assessing Knowledge Editing in Language Models via Relation Perspective
Nov 15, 2023



Knowledge Editing (KE) for modifying factual knowledge in Large Language Models (LLMs) has been receiving increasing attention. However, existing knowledge editing methods are entity-centric, and it is unclear whether this approach is suitable for a relation-centric perspective. To address this gap, this paper constructs a new benchmark named RaKE, which focuses on Relation based Knowledge Editing. In this paper, we establish a suite of innovative metrics for evaluation and conduct comprehensive experiments involving various knowledge editing baselines. We notice that existing knowledge editing methods exhibit the potential difficulty in their ability to edit relations. Therefore, we further explore the role of relations in factual triplets within the transformer. Our research results confirm that knowledge related to relations is not only stored in the FFN network but also in the attention layers. This provides experimental support for future relation-based knowledge editing methods.
EX-FEVER: A Dataset for Multi-hop Explainable Fact Verification
Oct 15, 2023Fact verification aims to automatically probe the veracity of a claim based on several pieces of evidence. Existing works are always engaging in the accuracy improvement, let alone the explainability, a critical capability of fact verification system. Constructing an explainable fact verification system in a complex multi-hop scenario is consistently impeded by the absence of a relevant high-quality dataset. Previous dataset either suffer from excessive simplification or fail to incorporate essential considerations for explainability. To address this, we present EX-FEVER, a pioneering dataset for multi-hop explainable fact verification. With over 60,000 claims involving 2-hop and 3-hop reasoning, each is created by summarizing and modifying information from hyperlinked Wikipedia documents. Each instance is accompanied by a veracity label and an explanation that outlines the reasoning path supporting the veracity classification. Additionally, we demonstrate a novel baseline system on our EX-FEVER dataset, showcasing document retrieval, explanation generation, and claim verification and observe that existing fact verification models trained on previous datasets struggle to perform well on our dataset. Furthermore, we highlight the potential of utilizing Large Language Models in the fact verification task. We hope our dataset could make a significant contribution by providing ample opportunities to explore the integration of natural language explanations in the domain of fact verification.
MenatQA: A New Dataset for Testing the Temporal Comprehension and Reasoning Abilities of Large Language Models
Oct 08, 2023



Large language models (LLMs) have shown nearly saturated performance on many natural language processing (NLP) tasks. As a result, it is natural for people to believe that LLMs have also mastered abilities such as time understanding and reasoning. However, research on the temporal sensitivity of LLMs has been insufficiently emphasized. To fill this gap, this paper constructs Multiple Sensitive Factors Time QA (MenatQA), which encompasses three temporal factors (scope factor, order factor, counterfactual factor) with total 2,853 samples for evaluating the time comprehension and reasoning abilities of LLMs. This paper tests current mainstream LLMs with different parameter sizes, ranging from billions to hundreds of billions. The results show most LLMs fall behind smaller temporal reasoning models with different degree on these factors. In specific, LLMs show a significant vulnerability to temporal biases and depend heavily on the temporal information provided in questions. Furthermore, this paper undertakes a preliminary investigation into potential improvement strategies by devising specific prompts and leveraging external tools. These approaches serve as valuable baselines or references for future research endeavors.