 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Emotion-Semantic Correlations for Empathetic Response Generation
Feb 27, 2024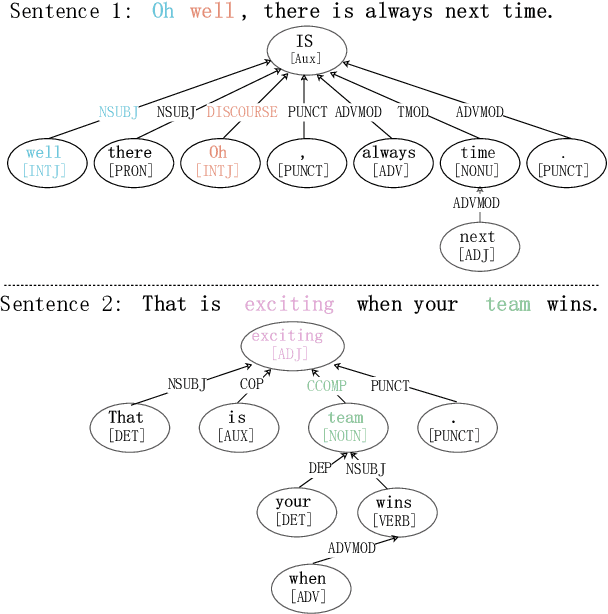
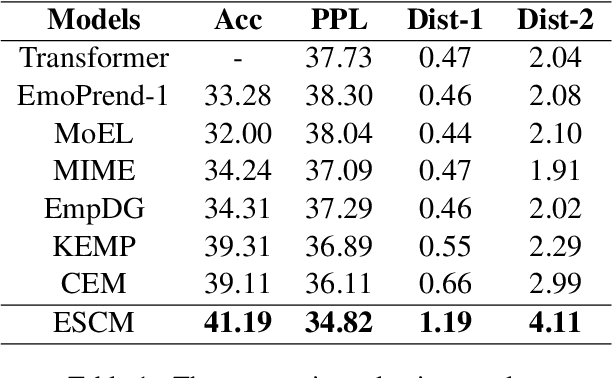
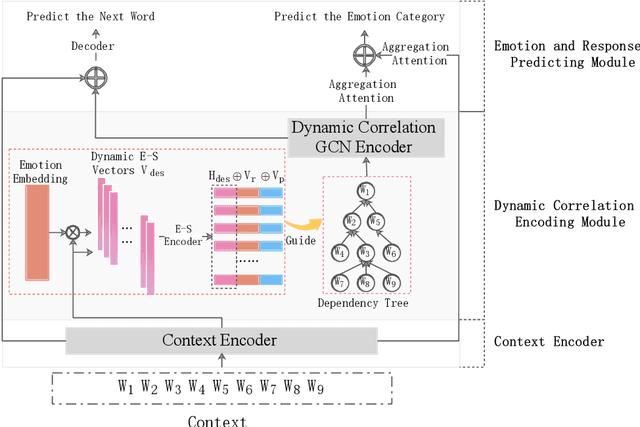
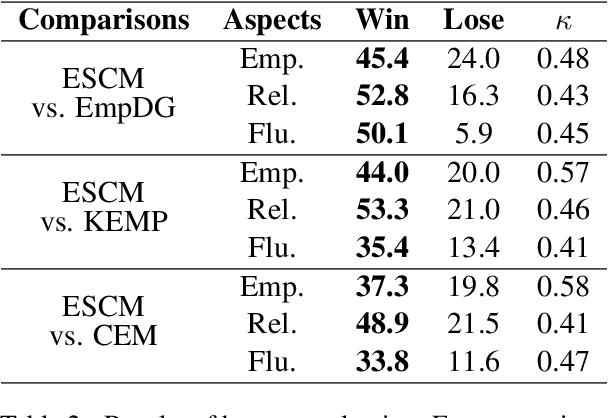
Empathetic response generation aims to generate empathetic responses by understanding the speaker's emotional feelings from the language of dialogue. Recent methods capture emotional words in the language of communicators and construct them as static vectors to perceive nuanced emotions. However, linguistic research has shown that emotional words in language are dynamic and have correlations with other grammar semantic roles, i.e., words with semantic meanings, in grammar. Previous methods overlook these two characteristics, which easily lead to misunderstandings of emotions and neglect of key semantics. To address this issue, we propose a dynamical Emotion-Semantic Correlation Model (ESCM) for empathetic dialogue generation tasks. ESCM constructs dynamic emotion-semantic vectors through the interaction of context and emotions. We introduce dependency trees to reflect the correlations between emotions and semantics. Based on dynamic emotion-semantic vectors and dependency trees, we propose a dynamic correlation graph convolutional network to guide the model in learning context meanings in dialogue and generating empathetic responses. Experimental results on the EMPATHETIC-DIALOGUES dataset show that ESCM understands semantics and emotions more accurately and expresses fluent and informative empathetic responses. Our analysis results also indicate that the correlations between emotions and semantics are frequently used in dialogues, which is of great significance for empathetic perception and expression.
MenatQA: A New Dataset for Testing the Temporal Comprehension and Reasoning Abilities of Large Language Models
Oct 08, 2023



Large language models (LLMs) have shown nearly saturated performance on many natural language processing (NLP) tasks. As a result, it is natural for people to believe that LLMs have also mastered abilities such as time understanding and reasoning. However, research on the temporal sensitivity of LLMs has been insufficiently emphasized. To fill this gap, this paper constructs Multiple Sensitive Factors Time QA (MenatQA), which encompasses three temporal factors (scope factor, order factor, counterfactual factor) with total 2,853 samples for evaluating the time comprehension and reasoning abilities of LLMs. This paper tests current mainstream LLMs with different parameter sizes, ranging from billions to hundreds of billions. The results show most LLMs fall behind smaller temporal reasoning models with different degree on these factors. In specific, LLMs show a significant vulnerability to temporal biases and depend heavily on the temporal information provided in questions. Furthermore, this paper undertakes a preliminary investigation into potential improvement strategies by devising specific prompts and leveraging external tools. These approaches serve as valuable baselines or references for future research endeavors.