 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Semantic Reasoning from Individual to Group Interests for Generative Recommendation with LLMs
Mar 14, 2026Recommendation systems aim to learn user interests from historical behaviors and deliver relevant items. Recent methods leverage large language models (LLMs) to construct and integrate semantic representations of users and items for capturing user interests. However, user behavior theories suggest that truly understanding user interests requires not only semantic integration but also semantic reasoning from explicit individual interests to implicit group interests. To this end, we propose an Iterative Semantic Reasoning Framework (ISRF) for generative recommendation. ISRF leverages LLMs to bridge explicit individual interests and implicit group interests in three steps. First, we perform multi-step bidirectional reasoning over item attributes to infer semantic item features and build a semantic interaction graph capturing users' explicit interests. Second, we generate semantic user features based on the semantic item features and construct a similarity-based user graph to infer the implicit interests of similar user groups. Third, we adopt an iterative batch optimization strategy, where individual explicit interests directly guide the refinement of group implicit interests, while group implicit interests indirectly enhance individual modeling. This iterative process ensures consistent and progressive interest reasoning, enabling more accurate and comprehensive user interest learning. Extensive experiments on the Sports, Beauty, and Toys datasets demonstrate that ISRF outperforms state-of-the-art baselines. The code is available at https://github.com/htired/ISRF.
DisenReason: Behavior Disentanglement and Latent Reasoning for Shared-Account Sequential Recommendation
Mar 04, 2026Shared-account usage is common on streaming and e-commerce platforms, where multiple users share one account. Existing shared-account sequential recommendation (SSR) methods often assume a fixed number of latent users per account, limiting their ability to adapt to diverse sharing patterns and reducing recommendation accuracy. Recent latent reasoning technique applied in sequential recommendation (SR) generate intermediate embeddings from the user embedding (e.g, last item embedding) to uncover users' potential interests, which inspires us to treat the problem of inferring the number of latent users as generating a series of intermediate embeddings, shifting from inferring preferences behind user to inferring the users behind account. However, the last item cannot be directly used for reasoning in SSR, as it can only represent the behavior of the most recent latent user, rather than the collective behavior of the entire account. To address this, we propose DisenReason, a two-stage reasoning method tailored to SSR. DisenReason combines behavior disentanglement stage from frequency-domain perspective to create a collective and unified account behavior representation, which serves as a pivot for latent user reasoning stage to infer the number of users behind the account. Experiments on four benchmark datasets show that DisenReason consistently outperforms all state-of-the-art baselines across four benchmark datasets, achieving relative improvements of up to 12.56\% in MRR@5 and 6.06\% in Recall@20.
Rethinking All Evidence: Enhancing Trustworthy Retrieval-Augmented Generation via Conflict-Driven Summarization
Jul 02, 2025Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by integrating their parametric knowledge with external retrieved content. However, knowledge conflicts caused by internal inconsistencies or noisy retrieved content can severely undermine the generation reliability of RAG systems.In this work, we argue that LLMs should rethink all evidence, including both retrieved content and internal knowledge, before generating responses.We propose CARE-RAG (Conflict-Aware and Reliable Evidence for RAG), a novel framework that improves trustworthiness through Conflict-Driven Summarization of all available evidence.CARE-RAG first derives parameter-aware evidence by comparing parameter records to identify diverse internal perspectives. It then refines retrieved evidences to produce context-aware evidence, removing irrelevant or misleading content. To detect and summarize conflicts, we distill a 3B LLaMA3.2 model to perform conflict-driven summarization, enabling reliable synthesis across multiple sources.To further ensure evaluation integrity, we introduce a QA Repair step to correct outdated or ambiguous benchmark answers.Experiments on revised QA datasets with retrieval data show that CARE-RAG consistently outperforms strong RAG baselines, especially in scenarios with noisy or conflicting evidence.
Cross-Modal Clustering-Guided Negative Sampling for Self-Supervised Joint Learning from Medical Images and Reports
Jun 13, 2025Learning medical visual representations directly from paired images and reports through multimodal self-supervised learning has emerged as a novel and efficient approach to digital diagnosis in recent years. However, existing models suffer from several severe limitations. 1) neglecting the selection of negative samples, resulting in the scarcity of hard negatives and the inclusion of false negatives; 2) focusing on global feature extraction, but overlooking the fine-grained local details that are crucial for medical image recognition tasks; and 3) contrastive learning primarily targets high-level features but ignoring low-level details which are essential for accurate medical analysis. Motivated by these critical issues, this paper presents a Cross-Modal Cluster-Guided Negative Sampling (CM-CGNS) method with two-fold ideas. First, it extends the k-means clustering used for local text features in the single-modal domain to the multimodal domain through cross-modal attention. This improvement increases the number of negative samples and boosts the model representation capability. Second, it introduces a Cross-Modal Masked Image Reconstruction (CM-MIR) module that leverages local text-to-image features obtained via cross-modal attention to reconstruct masked local image regions. This module significantly strengthens the model's cross-modal information interaction capabilities and retains low-level image features essential for downstream tasks. By well handling the aforementioned limitations, the proposed CM-CGNS can learn effective and robust medical visual representations suitable for various recognition tasks. Extensive experimental results on classification, detection, and segmentation tasks across five downstream datasets show that our method outperforms state-of-the-art approaches on multiple metrics, verifying its superior performance.
Exploring Information Processing in Large Language Models: Insights from Information Bottleneck Theory
Jan 06, 2025



Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of tasks by understanding input information and predicting corresponding outputs. However, the internal mechanisms by which LLMs comprehend input and make effective predictions remain poorly understood. In this paper, we explore the working mechanism of LLMs in information processing from the perspective of Information Bottleneck Theory. We propose a non-training construction strategy to define a task space and identify the following key findings: (1) LLMs compress input information into specific task spaces (e.g., sentiment space, topic space) to facilitate task understanding; (2) they then extract and utilize relevant information from the task space at critical moments to generate accurate predictions. Based on these insights, we introduce two novel approaches: an Information Compression-based Context Learning (IC-ICL) and a Task-Space-guided Fine-Tuning (TS-FT). IC-ICL enhances reasoning performance and inference efficiency by compressing retrieved example information into the task space. TS-FT employs a space-guided loss to fine-tune LLMs, encouraging the learning of more effective compression and selection mechanisms. Experiments across multiple datasets validate the effectiveness of task space construction. Additionally, IC-ICL not only improves performance but also accelerates inference speed by over 40\%, while TS-FT achieves superior results with a minimal strategy adjustment.
HEC-GCN: Hypergraph Enhanced Cascading Graph Convolution Network for Multi-Behavior Recommendation
Dec 19, 2024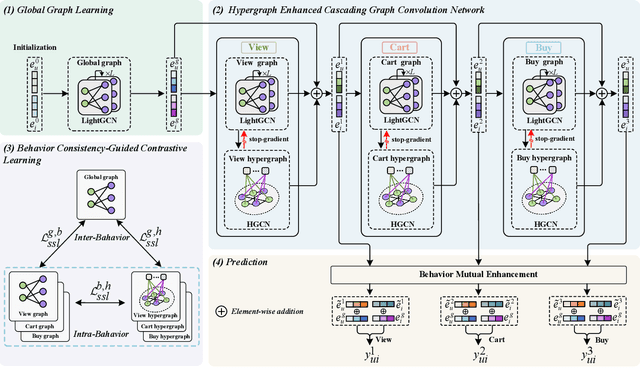
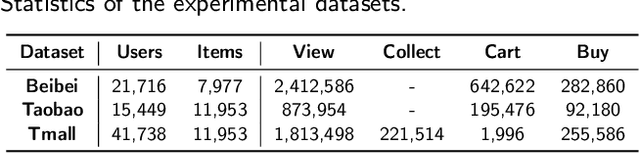
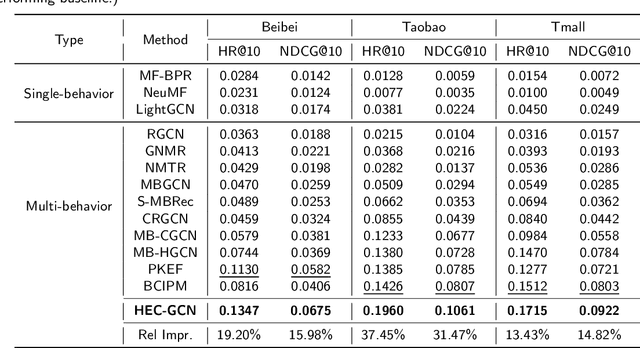
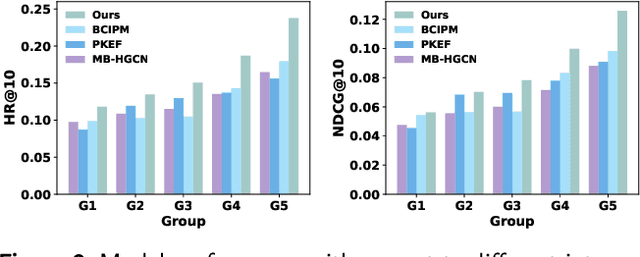
Multi-behavior recommendation (MBR) has garnered growing attention recently due to its ability to mitigate the sparsity issue by inferring user preferences from various auxiliary behaviors to improve predictions for the target behavior. Although existing research on MBR has yielded impressive results, they still face two major limitations. First, previous methods mainly focus on modeling fine-grained interaction information between users and items under each behavior, which may suffer from sparsity issue. Second, existing models usually concentrate on exploiting dependencies between two consecutive behaviors, leaving intra- and inter-behavior consistency largely unexplored. To the end, we propose a novel approach named Hypergraph Enhanced Cascading Graph Convolution Network for multi-behavior recommendation (HEC-GCN). To be specific, we first explore both fine- and coarse-grained correlations among users or items of each behavior by simultaneously modeling the behavior-specific interaction graph and its corresponding hypergraph in a cascaded manner. Then, we propose a behavior consistency-guided alignment strategy that ensures consistent representations between the interaction graph and its associated hypergraph for each behavior, while also maintaining representation consistency across different behaviors. Extensive experiments and analyses on three public benchmark datasets demonstrate that our proposed approach is consistently superior to previous state-of-the-art methods due to its capability to effectively attenuate the sparsity issue as well as preserve both intra- and inter-behavior consistencies. The code is available at https://github.com/marqu22/HEC-GCN.git.
CMATH: Cross-Modality Augmented Transformer with Hierarchical Variational Distillation for Multimodal Emotion Recognition in Conversation
Nov 15, 2024Multimodal emotion recognition in conversation (MER) aims to accurately identify emotions in conversational utterances by integrating multimodal information. Previous methods usually treat multimodal information as equal quality and employ symmetric architectures to conduct multimodal fusion. However, in reality, the quality of different modalities usually varies considerably, and utilizing a symmetric architecture is difficult to accurately recognize conversational emotions when dealing with uneven modal information. Furthermore, fusing multi-modality information in a single granularity may fail to adequately integrate modal information, exacerbating the inaccuracy in emotion recognition. In this paper, we propose a novel Cross-Modality Augmented Transformer with Hierarchical Variational Distillation, called CMATH, which consists of two major components, i.e., Multimodal Interaction Fusion and Hierarchical Variational Distillation. The former is comprised of two submodules, including Modality Reconstruction and Cross-Modality Augmented Transformer (CMA-Transformer), where Modality Reconstruction focuses on obtaining high-quality compressed representation of each modality, and CMA-Transformer adopts an asymmetric fusion strategy which treats one modality as the central modality and takes others as auxiliary modalities. The latter first designs a variational fusion network to fuse the fine-grained representations learned by CMA- Transformer into a coarse-grained representations. Then, it introduces a hierarchical distillation framework to maintain the consistency between modality representations with different granularities. Experiments on the IEMOCAP and MELD datasets demonstrate that our proposed model outperforms previous state-of-the-art baselines. Implementation codes can be available at https://github.com/ cjw-MER/CMATH.
MIMNet: Multi-Interest Meta Network with Multi-Granularity Target-Guided Attention for Cross-domain Recommendation
Jul 31, 2024Cross-domain recommendation (CDR) plays a critical role in alleviating the sparsity and cold-start problem and substantially boosting the performance of recommender systems. Existing CDR methods prefer to either learn a common preference bridge shared by all users or a personalized preference bridge tailored for each user to transfer user preference from the source domain to the target domain. Although these methods significantly improve the recommendation performance, there are still some limitations. First, these methods usually assume a user only has a unique interest, while ignoring the fact that a user may interact with items with different interest preferences. Second, they learn transformed preference representation mainly relies on the source domain signals, while neglecting the rich information available in the target domain. To handle these issues, in this paper, we propose a novel method named Multi-interest Meta Network with Multi-granularity Target-guided Attention (MIMNet) for cross-domain recommendation. To be specific, we employ the capsule network to learn user multiple interests in the source domain, which will be fed into a meta network to generate multiple interest-level preference bridges. Then, we transfer user representations from the source domain to the target domain based on these multi-interest bridges. In addition, we introduce both fine-grained and coarse-grained target signals to aggregate user transformed interest-level representations by incorporating a novel multi-granularity target-guided attention network. We conduct extensive experimental results on three real-world CDR tasks, and the results show that our proposed approach MIMNet consistently outperforms all baseline methods. The source code of MIMNet is released at https://github.com/marqu22/MIMNet.
E-ICL: Enhancing Fine-Grained Emotion Recognition through the Lens of Prototype Theory
Jun 04, 2024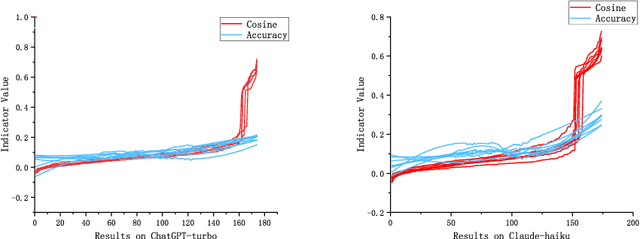
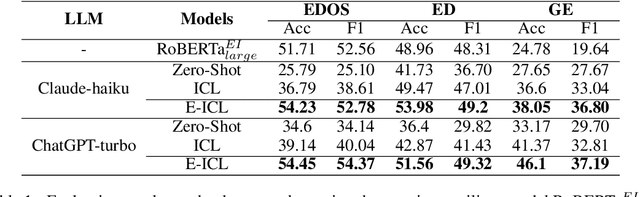
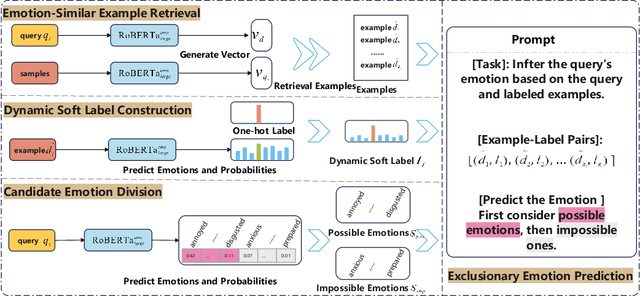
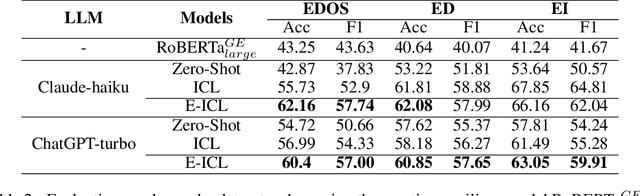
In-context learning (ICL) achieves remarkable performance in various domains such as knowledge acquisition, commonsense reasoning, and semantic understanding. However, its performance significantly deteriorates for emotion detection tasks, especially fine-grained emotion recognition. The underlying reasons for this remain unclear. In this paper, we identify the reasons behind ICL's poor performance from the perspective of prototype theory and propose a method to address this issue. Specifically, we conduct extensive pilot experiments and find that ICL conforms to the prototype theory on fine-grained emotion recognition. Based on this theory, we uncover the following deficiencies in ICL: (1) It relies on prototypes (example-label pairs) that are semantically similar but emotionally inaccurate to predict emotions. (2) It is prone to interference from irrelevant categories, affecting the accuracy and robustness of the predictions. To address these issues, we propose an Emotion Context Learning method (E-ICL) on fine-grained emotion recognition. E-ICL relies on more emotionally accurate prototypes to predict categories by referring to emotionally similar examples with dynamic labels. Simultaneously, E-ICL employs an exclusionary emotion prediction strategy to avoid interference from irrelevant categories, thereby increasing its accuracy and robustness. Note that the entire process is accomplished with the assistance of a plug-and-play emotion auxiliary model, without additional training. Experiments on the fine-grained emotion datasets EDOS, Empathetic-Dialogues, EmpatheticIntent, and GoEmotions show that E-ICL achieves superior emotion prediction performance. Furthermore, even when the emotion auxiliary model used is lower than 10% of the LLMs, E-ICL can still boost the performance of LLMs by over 4% on multiple datasets.
Multi-Level Sequence Denoising with Cross-Signal Contrastive Learning for Sequential Recommendation
Apr 22, 2024Sequential recommender systems (SRSs) aim to suggest next item for a user based on her historical interaction sequences. Recently, many research efforts have been devoted to attenuate the influence of noisy items in sequences by either assigning them with lower attention weights or discarding them directly. The major limitation of these methods is that the former would still prone to overfit noisy items while the latter may overlook informative items. To the end, in this paper, we propose a novel model named Multi-level Sequence Denoising with Cross-signal Contrastive Learning (MSDCCL) for sequential recommendation. To be specific, we first introduce a target-aware user interest extractor to simultaneously capture users' long and short term interest with the guidance of target items. Then, we develop a multi-level sequence denoising module to alleviate the impact of noisy items by employing both soft and hard signal denoising strategies. Additionally, we extend existing curriculum learning by simulating the learning pattern of human beings. It is worth noting that our proposed model can be seamlessly integrated with a majority of existing recommendation models and significantly boost their effectiveness. Experimental studies on five public datasets are conducted and the results demonstrate that the proposed MSDCCL is superior to the state-of-the-art baselines. The source code is publicly available at https://github.com/lalunex/MSDCCL/tree/main.