 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogicEnvGen: Task-Logic Driven Generation of Diverse Simulated Environments for Embodied AI
Jan 20, 2026Simulated environments play an essential role in embodied AI, functionally analogous to test cases in software engineering. However, existing environment generation methods often emphasize visual realism (e.g., object diversity and layout coherence), overlooking a crucial aspect: logical diversity from the testing perspective. This limits the comprehensive evaluation of agent adaptability and planning robustness in distinct simulated environments. To bridge this gap, we propose LogicEnvGen, a novel method driven by Large Language Models (LLMs) that adopts a top-down paradigm to generate logically diverse simulated environments as test cases for agents. Given an agent task, LogicEnvGen first analyzes its execution logic to construct decision-tree-structured behavior plans and then synthesizes a set of logical trajectories. Subsequently, it adopts a heuristic algorithm to refine the trajectory set, reducing redundant simulation. For each logical trajectory, which represents a potential task situation, LogicEnvGen correspondingly instantiates a concrete environment. Notably, it employs constraint solving for physical plausibility. Furthermore, we introduce LogicEnvEval, a novel benchmark comprising four quantitative metrics for environment evaluation. Experimental results verify the lack of logical diversity in baselines and demonstrate that LogicEnvGen achieves 1.04-2.61x greater diversity, significantly improving the performance in revealing agent faults by 4.00%-68.00%.
HY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
Rethinking All Evidence: Enhancing Trustworthy Retrieval-Augmented Generation via Conflict-Driven Summarization
Jul 02, 2025Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by integrating their parametric knowledge with external retrieved content. However, knowledge conflicts caused by internal inconsistencies or noisy retrieved content can severely undermine the generation reliability of RAG systems.In this work, we argue that LLMs should rethink all evidence, including both retrieved content and internal knowledge, before generating responses.We propose CARE-RAG (Conflict-Aware and Reliable Evidence for RAG), a novel framework that improves trustworthiness through Conflict-Driven Summarization of all available evidence.CARE-RAG first derives parameter-aware evidence by comparing parameter records to identify diverse internal perspectives. It then refines retrieved evidences to produce context-aware evidence, removing irrelevant or misleading content. To detect and summarize conflicts, we distill a 3B LLaMA3.2 model to perform conflict-driven summarization, enabling reliable synthesis across multiple sources.To further ensure evaluation integrity, we introduce a QA Repair step to correct outdated or ambiguous benchmark answers.Experiments on revised QA datasets with retrieval data show that CARE-RAG consistently outperforms strong RAG baselines, especially in scenarios with noisy or conflicting evidence.
BeSimulator: A Large Language Model Powered Text-based Behavior Simulator
Sep 24, 2024



Traditional robot simulators focus on physical process modeling and realistic rendering, often suffering from high computational costs, inefficiencies, and limited adaptability. To handle this issue, we propose Behavior Simulation in robotics to emphasize checking the behavior logic of robots and achieving sufficient alignment between the outcome of robot actions and real scenarios. In this paper, we introduce BeSimulator, a modular and novel LLM-powered framework, as an attempt towards behavior simulation in the context of text-based environments. By constructing text-based virtual environments and performing semantic-level simulation, BeSimulator can generalize across scenarios and achieve long-horizon complex simulation. Inspired by human cognition processes, it employs a "consider-decide-capture-transfer" methodology, termed Chain of Behavior Simulation, which excels at analyzing action feasibility and state transitions. Additionally, BeSimulator incorporates code-driven reasoning to enable arithmetic operations and enhance reliability, as well as integrates reflective feedback to refine simulation. Based on our manually constructed behavior-tree-based simulation benchmark BTSIMBENCH, our experiments show a significant performance improvement in behavior simulation compared to baselines, ranging from 14.7% to 26.6%.
3D-EffiViTCaps: 3D Efficient Vision Transformer with Capsule for Medical Image Segmentation
Mar 25, 2024



Medical image segmentation (MIS) aims to finely segment various organs. It requires grasping global information from both parts and the entire image for better segmenting, and clinically there are often certain requirements for segmentation efficiency. Convolutional neural networks (CNNs) have made considerable achievements in MIS. However, they are difficult to fully collect global context information and their pooling layer may cause information loss. Capsule networks, which combine the benefits of CNNs while taking into account additional information such as relative location that CNNs do not, have lately demonstrated some advantages in MIS. Vision Transformer (ViT) employs transformers in visual tasks. Transformer based on attention mechanism has excellent global inductive modeling capabilities and is expected to capture longrange information. Moreover, there have been resent studies on making ViT more lightweight to minimize model complexity and increase efficiency. In this paper, we propose a U-shaped 3D encoder-decoder network named 3D-EffiViTCaps, which combines 3D capsule blocks with 3D EfficientViT blocks for MIS. Our encoder uses capsule blocks and EfficientViT blocks to jointly capture local and global semantic information more effectively and efficiently with less information loss, while the decoder employs CNN blocks and EfficientViT blocks to catch ffner details for segmentation. We conduct experiments on various datasets, including iSeg-2017, Hippocampus and Cardiac to verify the performance and efficiency of 3D-EffiViTCaps, which performs better than previous 3D CNN-based, 3D Capsule-based and 3D Transformer-based models. We further implement a series of ablation experiments on the main blocks. Our code is available at: https://github.com/HidNeuron/3D-EffiViTCaps.
Temporal Disentangled Contrastive Diffusion Model for Spatiotemporal Imputation
Feb 18, 2024



Spatiotemporal data analysis is pivotal across various domains, including transportation, meteorology, and healthcare. However, the data collected in real-world scenarios often suffers incompleteness due to sensor malfunctions and network transmission errors. Spatiotemporal imputation endeavours to predict missing values by exploiting the inherent spatial and temporal dependencies present in the observed data. Traditional approaches, which rely on classical statistical and machine learning techniques, are often inadequate, particularly when the data fails to meet strict distributional assumptions. In contrast, recent deep learning-based methods, leveraging graph and recurrent neural networks, have demonstrated enhanced efficacy. Nonetheless, these approaches are prone to error accumulation. Generative models have been increasingly adopted to circumvent the reliance on potentially inaccurate historical imputed values for future predictions. These models grapple with the challenge of producing unstable results, a particular issue in diffusion-based models. We aim to address these challenges by designing conditional features to guide the generative process and expedite training. Specifically, we introduce C$^2$TSD, a novel approach incorporating trend and seasonal information as conditional features and employing contrastive learning to improve model generalizability. The extensive experiments on three real-world datasets demonstrate the superior performance of C$^2$TSD over various state-of-the-art baselines.
A Survey on Graph Classification and Link Prediction based on GNN
Jul 03, 2023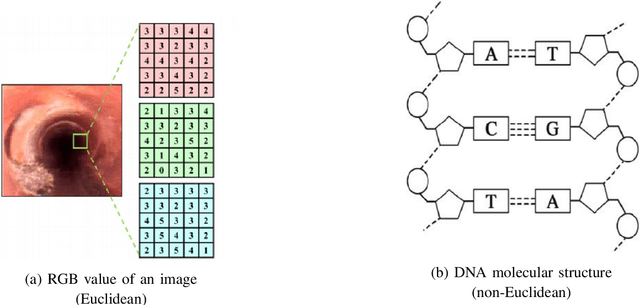
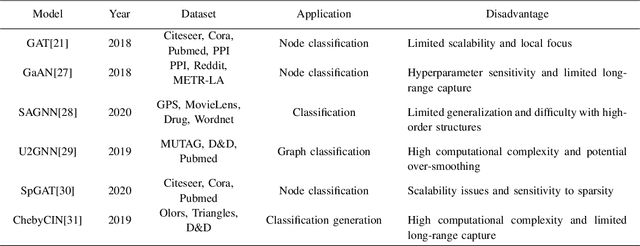
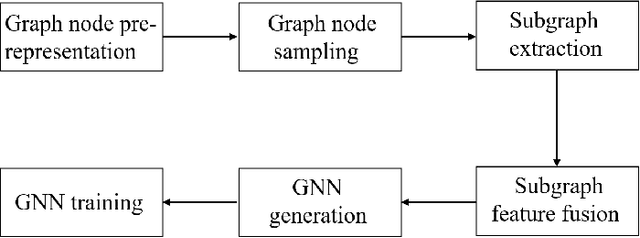
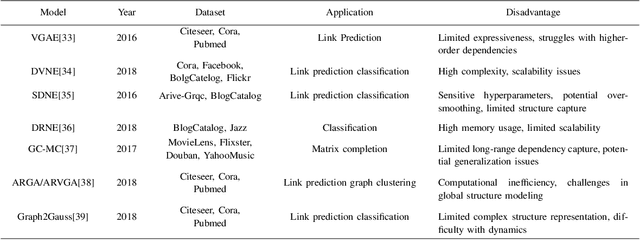
Traditional convolutional neural networks are limited to handling Euclidean space data, overlooking the vast realm of real-life scenarios represented as graph data, including transportation networks, social networks, and reference networks. The pivotal step in transferring convolutional neural networks to graph data analysis and processing lies in the construction of graph convolutional operators and graph pooling operators. This comprehensive review article delves into the world of graph convolutional neural networks. Firstly, it elaborates on the fundamentals of graph convolutional neural networks. Subsequently, it elucidates the graph neural network models based on attention mechanisms and autoencoders, summarizing their application in node classification, graph classification, and link prediction along with the associated datasets.
RTFN: Robust Temporal Feature Network
Aug 18, 2020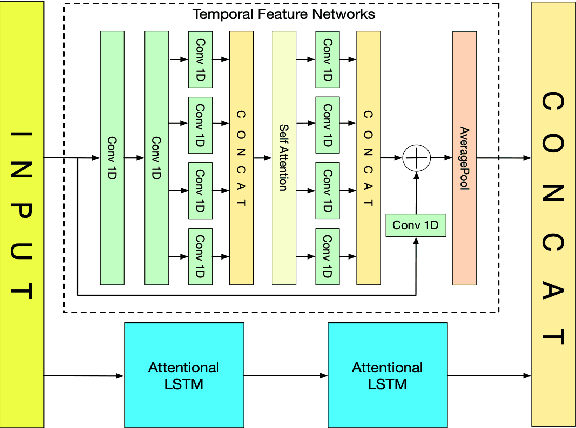

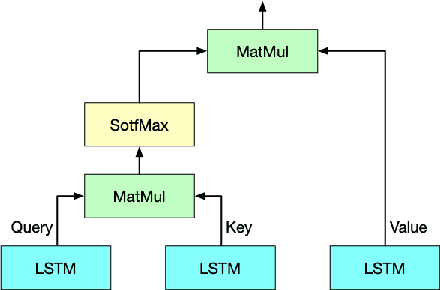
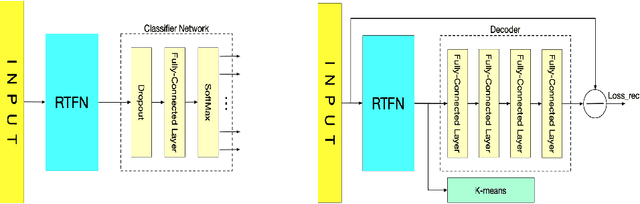
Time series analysis plays a vital role in various applications, for instance, healthcare, weather prediction, disaster forecast, etc. However, to obtain sufficient shapelets by a feature network is still challenging. To this end, we propose a novel robust temporal feature network (RTFN) that contains temporal feature networks and attentional LSTM networks. The temporal feature networks are built to extract basic features from input data while the attentional LSTM networks are devised to capture complicated shapelets and relationships to enrich features. In experiments, we embed RTFN into supervised structure as a feature extraction network and into unsupervised clustering as an encoder, respectively. The results show that the RTFN-based supervised structure is a winner of 40 out of 85 datasets and the RTFN-based unsupervised clustering performs the best on 4 out of 11 datasets in the UCR2018 archive.
STDPG: A Spatio-Temporal Deterministic Policy Gradient Agent for Dynamic Routing in SDN
Apr 21, 2020
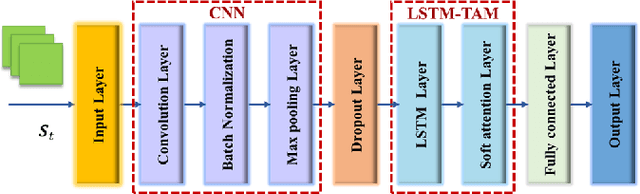
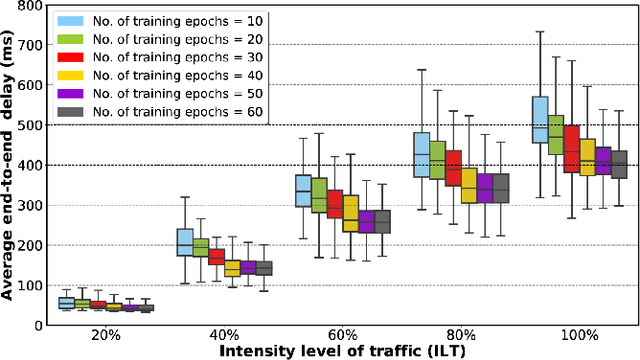

Dynamic routing in software-defined networking (SDN) can be viewed as a centralized decision-making problem. Most of the existing deep reinforcement learning (DRL) agents can address it, thanks to the deep neural network (DNN)incorporated. However, fully-connected feed-forward neural network (FFNN) is usually adopted, where spatial correlation and temporal variation of traffic flows are ignored. This drawback usually leads to significantly high computational complexity due to large number of training parameters. To overcome this problem, we propose a novel model-free framework for dynamic routing in SDN, which is referred to as spatio-temporal deterministic policy gradient (STDPG) agent. Both the actor and critic networks are based on identical DNN structure, where a combination of convolutional neural network (CNN) and long short-term memory network (LSTM) with temporal attention mechanism, CNN-LSTM-TAM, is devised. By efficiently exploiting spatial and temporal features, CNNLSTM-TAM helps the STDPG agent learn better from the experience transitions. Furthermore, we employ the prioritized experience replay (PER) method to accelerate the convergence of model training. The experimental results show that STDPG can automatically adapt for current network environment and achieve robust convergence. Compared with a number state-ofthe-art DRL agents, STDPG achieves better routing solutions in terms of the average end-to-end delay.