 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoCom: Kilobyte-Scale Communication-Efficient Collaborative Perception with Information Bottleneck
Dec 11, 2025Precise environmental perception is critical for the reliability of autonomous driving systems. While collaborative perception mitigates the limitations of single-agent perception through information sharing, it encounters a fundamental communication-performance trade-off. Existing communication-efficient approaches typically assume MB-level data transmission per collaboration, which may fail due to practical network constraints. To address these issues, we propose InfoCom, an information-aware framework establishing the pioneering theoretical foundation for communication-efficient collaborative perception via extended Information Bottleneck principles. Departing from mainstream feature manipulation, InfoCom introduces a novel information purification paradigm that theoretically optimizes the extraction of minimal sufficient task-critical information under Information Bottleneck constraints. Its core innovations include: i) An Information-Aware Encoding condensing features into minimal messages while preserving perception-relevant information; ii) A Sparse Mask Generation identifying spatial cues with negligible communication cost; and iii) A Multi-Scale Decoding that progressively recovers perceptual information through mask-guided mechanisms rather than simple feature reconstruction. Comprehensive experiments across multiple datasets demonstrate that InfoCom achieves near-lossless perception while reducing communication overhead from megabyte to kilobyte-scale, representing 440-fold and 90-fold reductions per agent compared to Where2comm and ERMVP, respectively.
Enabling Digital Twin in Vehicular Edge Computing: A Multi-Agent Multi-Objective Deep Reinforcement Learning Solution
Oct 31, 2022



With recent advances in sensing technologies, wireless communications, and computing paradigms, traditional vehicles are evolving to electronic consumer products, driving the research on digital twins in vehicular edge computing (DT-VEC). This paper makes the first attempt to achieve the quality-cost tradeoff in DT-VEC. First, a DT-VEC architecture is presented, where the heterogeneous information can be sensed by vehicles and uploaded to the edge node via vehicle-to-infrastructure (V2I) communications. The DT-VEC are modeled at the edge node, forming a logical view to reflect the physical vehicular environment. Second, we model the DT-VEC by deriving an ISAC (integrated sensing and communication)-assisted sensing model and a reliability-guaranteed uploading model. Third, we define the quality of DT-VEC by considering the timeliness and consistency, and define the cost of DT-VEC by considering the redundancy, sensing cost, and transmission cost. Then, a bi-objective problem is formulated to maximize the quality and minimize the cost. Fourth, we propose a multi-agent multi-objective (MAMO) deep reinforcement learning solution implemented distributedly in the vehicles and the edge nodes. Specifically, a dueling critic network is proposed to evaluate the advantage of action over the average of random actions. Finally, we give a comprehensive performance evaluation, demonstrating the superiority of the proposed MAMO.
On Jointly Optimizing Partial Offloading and SFC Mapping: A Cooperative Dual-agent Deep Reinforcement Learning Approach
May 20, 2022
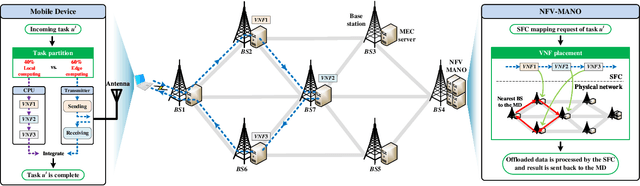
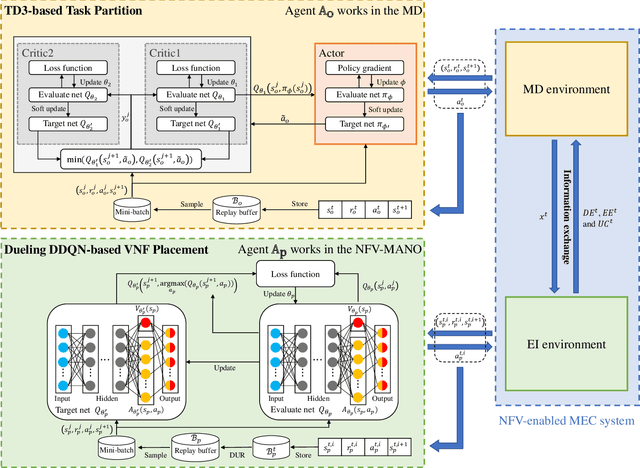

Multi-access edge computing (MEC) and network function virtualization (NFV) are promising technologies to support emerging IoT applications, especially those computation-intensive. In NFV-enabled MEC environment, service function chain (SFC), i.e., a set of ordered virtual network functions (VNFs), can be mapped on MEC servers. Mobile devices (MDs) can offload computation-intensive applications, which can be represented by SFCs, fully or partially to MEC servers for remote execution. This paper studies the partial offloading and SFC mapping joint optimization (POSMJO) problem in an NFV-enabled MEC system, where an incoming task can be partitioned into two parts, one for local execution and the other for remote execution. The objective is to minimize the average cost in the long term which is a combination of execution delay, MD's energy consumption, and usage charge for edge computing. This problem consists of two closely related decision-making steps, namely task partition and VNF placement, which is highly complex and quite challenging. To address this, we propose a cooperative dual-agent deep reinforcement learning (CDADRL) algorithm, where we design a framework enabling interaction between two agents. Simulation results show that the proposed algorithm outperforms three combinations of deep reinforcement learning algorithms in terms of cumulative and average episodic rewards and it overweighs a number of baseline algorithms with respect to execution delay, energy consumption, and usage charge.
Evolutionary Multi-Objective Reinforcement Learning Based Trajectory Control and Task Offloading in UAV-Assisted Mobile Edge Computing
Feb 24, 2022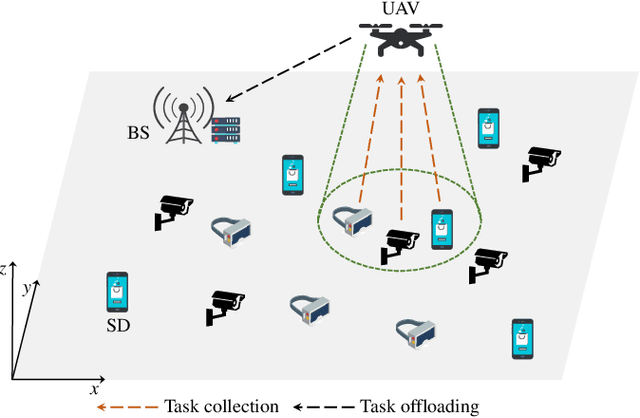

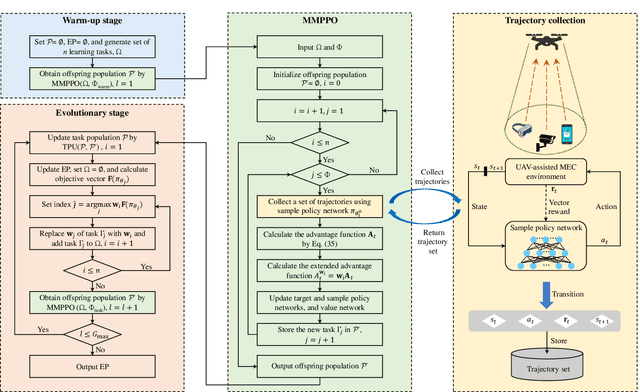
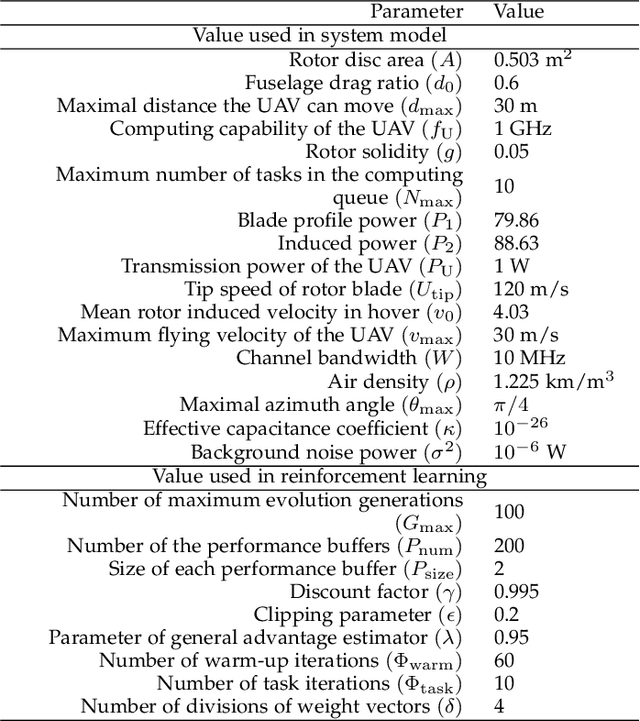
This paper studies the trajectory control and task offloading (TCTO) problem in an unmanned aerial vehicle (UAV)-assisted mobile edge computing system, where a UAV flies along a planned trajectory to collect computation tasks from smart devices (SDs). We consider a scenario that SDs are not directly connected by the base station (BS) and the UAV has two roles to play: MEC server or wireless relay. The UAV makes task offloading decisions online, in which the collected tasks can be executed locally on the UAV or offloaded to the BS for remote processing. The TCTO problem involves multi-objective optimization as its objectives are to minimize the task delay and the UAV's energy consumption, and maximize the number of tasks collected by the UAV, simultaneously. This problem is challenging because the three objectives conflict with each other. The existing reinforcement learning (RL) algorithms, either single-objective RLs or single-policy multi-objective RLs, cannot well address the problem since they cannot output multiple policies for various preferences (i.e. weights) across objectives in a single run. This paper adapts the evolutionary multi-objective RL (EMORL), a multi-policy multi-objective RL, to the TCTO problem. This algorithm can output multiple optimal policies in just one run, each optimizing a certain preference. The simulation results demonstrate that the proposed algorithm can obtain more excellent nondominated policies by striking a balance between the three objectives regarding policy quality, compared with two evolutionary and two multi-policy RL algorithms.
RTFN: A Robust Temporal Feature Network for Time Series Classification
Nov 24, 2020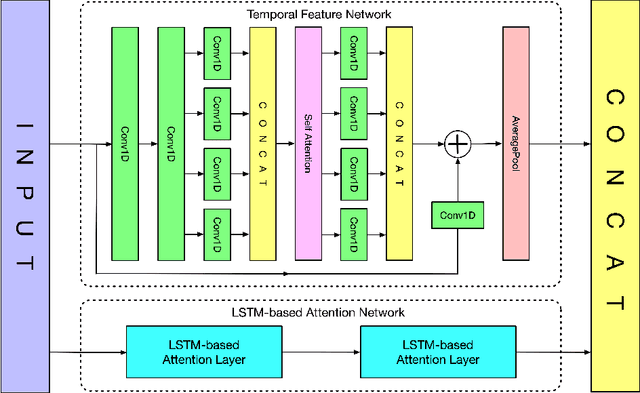
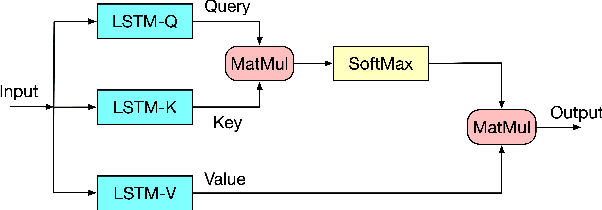
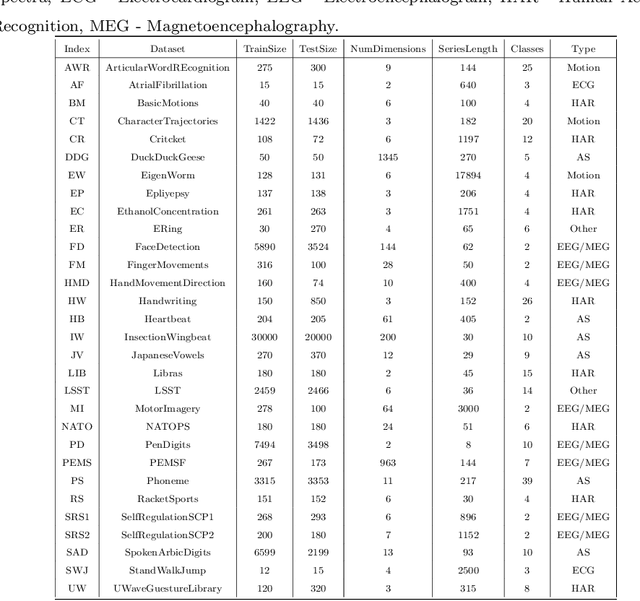
Time series data usually contains local and global patterns. Most of the existing feature networks pay more attention to local features rather than the relationships among them. The latter is, however, also important yet more difficult to explore. To obtain sufficient representations by a feature network is still challenging. To this end, we propose a novel robust temporal feature network (RTFN) for feature extraction in time series classification, containing a temporal feature network (TFN) and an LSTM-based attention network (LSTMaN). TFN is a residual structure with multiple convolutional layers. It functions as a local-feature extraction network to mine sufficient local features from data. LSTMaN is composed of two identical layers, where attention and long short-term memory (LSTM) networks are hybridized. This network acts as a relation extraction network to discover the intrinsic relationships among the extracted features at different positions in sequential data. In experiments, we embed RTFN into a supervised structure as a feature extractor and into an unsupervised structure as an encoder, respectively. The results show that the RTFN-based structures achieve excellent supervised and unsupervised performance on a large number of UCR2018 and UEA2018 datasets.
STDPG: A Spatio-Temporal Deterministic Policy Gradient Agent for Dynamic Routing in SDN
Apr 21, 2020
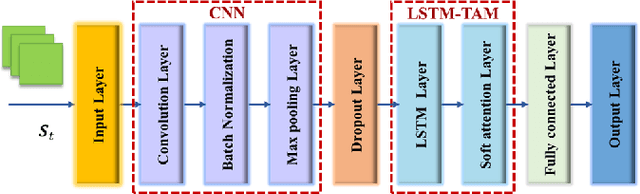
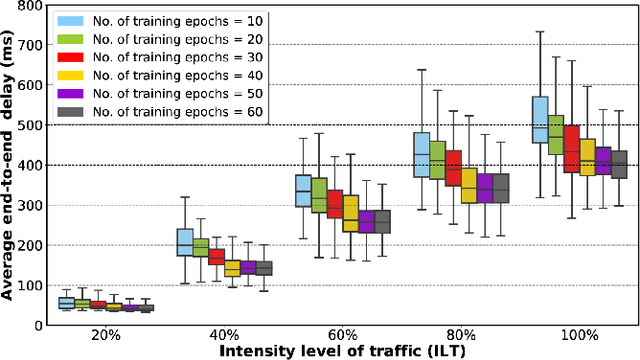

Dynamic routing in software-defined networking (SDN) can be viewed as a centralized decision-making problem. Most of the existing deep reinforcement learning (DRL) agents can address it, thanks to the deep neural network (DNN)incorporated. However, fully-connected feed-forward neural network (FFNN) is usually adopted, where spatial correlation and temporal variation of traffic flows are ignored. This drawback usually leads to significantly high computational complexity due to large number of training parameters. To overcome this problem, we propose a novel model-free framework for dynamic routing in SDN, which is referred to as spatio-temporal deterministic policy gradient (STDPG) agent. Both the actor and critic networks are based on identical DNN structure, where a combination of convolutional neural network (CNN) and long short-term memory network (LSTM) with temporal attention mechanism, CNN-LSTM-TAM, is devised. By efficiently exploiting spatial and temporal features, CNNLSTM-TAM helps the STDPG agent learn better from the experience transitions. Furthermore, we employ the prioritized experience replay (PER) method to accelerate the convergence of model training. The experimental results show that STDPG can automatically adapt for current network environment and achieve robust convergence. Compared with a number state-ofthe-art DRL agents, STDPG achieves better routing solutions in terms of the average end-to-end delay.