 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTDPG: A Spatio-Temporal Deterministic Policy Gradient Agent for Dynamic Routing in SDN
Paper and Code
Apr 21, 2020
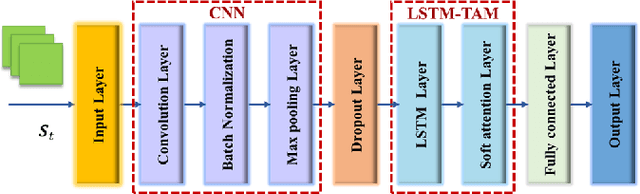
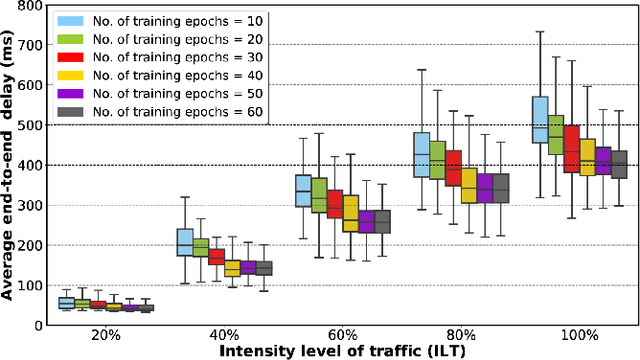

Dynamic routing in software-defined networking (SDN) can be viewed as a centralized decision-making problem. Most of the existing deep reinforcement learning (DRL) agents can address it, thanks to the deep neural network (DNN)incorporated. However, fully-connected feed-forward neural network (FFNN) is usually adopted, where spatial correlation and temporal variation of traffic flows are ignored. This drawback usually leads to significantly high computational complexity due to large number of training parameters. To overcome this problem, we propose a novel model-free framework for dynamic routing in SDN, which is referred to as spatio-temporal deterministic policy gradient (STDPG) agent. Both the actor and critic networks are based on identical DNN structure, where a combination of convolutional neural network (CNN) and long short-term memory network (LSTM) with temporal attention mechanism, CNN-LSTM-TAM, is devised. By efficiently exploiting spatial and temporal features, CNNLSTM-TAM helps the STDPG agent learn better from the experience transitions. Furthermore, we employ the prioritized experience replay (PER) method to accelerate the convergence of model training. The experimental results show that STDPG can automatically adapt for current network environment and achieve robust convergence. Compared with a number state-ofthe-art DRL agents, STDPG achieves better routing solutions in terms of the average end-to-end delay.