 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Attention Mechanism in Time Series Classification
Jul 14, 2022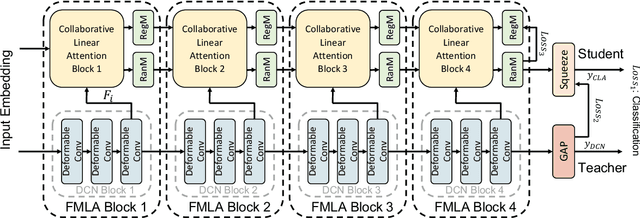
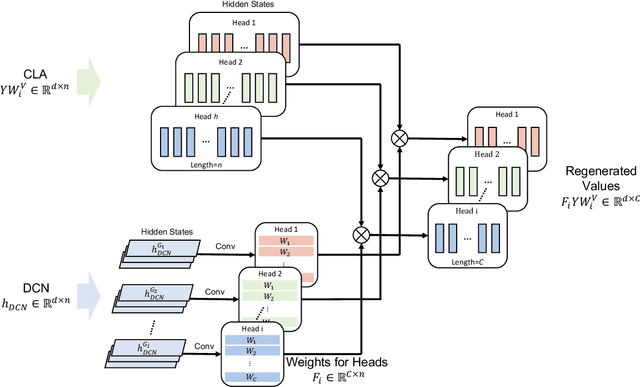
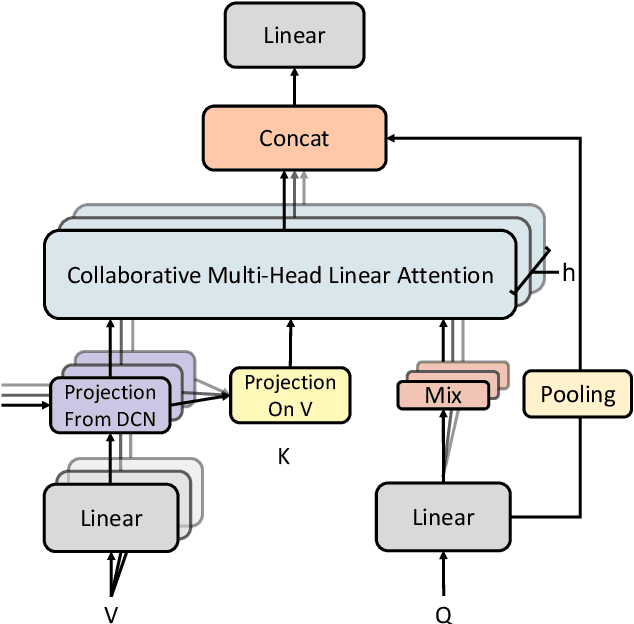
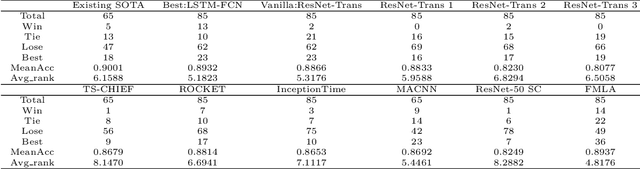
Attention-based models have been widely used in many areas, such as computer vision and natural language processing. However, relevant applications in time series classification (TSC) have not been explored deeply yet, causing a significant number of TSC algorithms still suffer from general problems of attention mechanism, like quadratic complexity. In this paper, we promote the efficiency and performance of the attention mechanism by proposing our flexible multi-head linear attention (FMLA), which enhances locality awareness by layer-wise interactions with deformable convolutional blocks and online knowledge distillation. What's more, we propose a simple but effective mask mechanism that helps reduce the noise influence in time series and decrease the redundancy of the proposed FMLA by masking some positions of each given series proportionally. To stabilize this mechanism, samples are forwarded through the model with random mask layers several times and their outputs are aggregated to teach the same model with regular mask layers. We conduct extensive experiments on 85 UCR2018 datasets to compare our algorithm with 11 well-known ones and the results show that our algorithm has comparable performance in terms of top-1 accuracy. We also compare our model with three Transformer-based models with respect to the floating-point operations per second and number of parameters and find that our algorithm achieves significantly better efficiency with lower complexity.
On Jointly Optimizing Partial Offloading and SFC Mapping: A Cooperative Dual-agent Deep Reinforcement Learning Approach
May 20, 2022
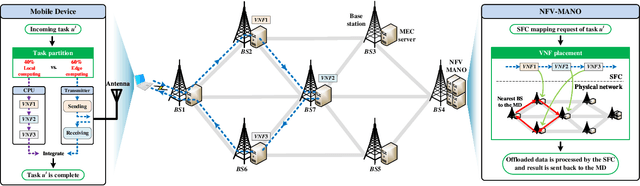
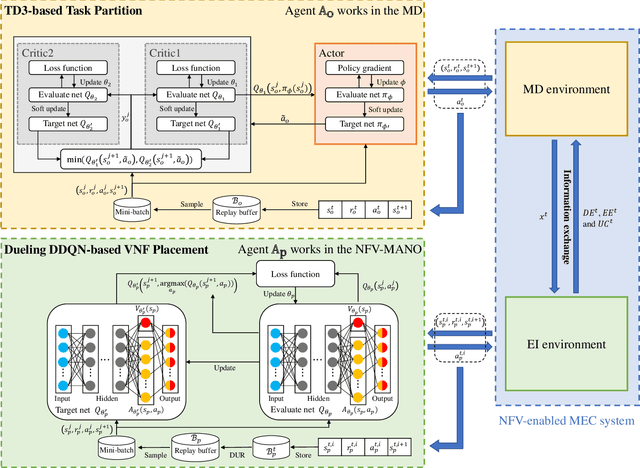

Multi-access edge computing (MEC) and network function virtualization (NFV) are promising technologies to support emerging IoT applications, especially those computation-intensive. In NFV-enabled MEC environment, service function chain (SFC), i.e., a set of ordered virtual network functions (VNFs), can be mapped on MEC servers. Mobile devices (MDs) can offload computation-intensive applications, which can be represented by SFCs, fully or partially to MEC servers for remote execution. This paper studies the partial offloading and SFC mapping joint optimization (POSMJO) problem in an NFV-enabled MEC system, where an incoming task can be partitioned into two parts, one for local execution and the other for remote execution. The objective is to minimize the average cost in the long term which is a combination of execution delay, MD's energy consumption, and usage charge for edge computing. This problem consists of two closely related decision-making steps, namely task partition and VNF placement, which is highly complex and quite challenging. To address this, we propose a cooperative dual-agent deep reinforcement learning (CDADRL) algorithm, where we design a framework enabling interaction between two agents. Simulation results show that the proposed algorithm outperforms three combinations of deep reinforcement learning algorithms in terms of cumulative and average episodic rewards and it overweighs a number of baseline algorithms with respect to execution delay, energy consumption, and usage charge.
Evolutionary Multi-Objective Reinforcement Learning Based Trajectory Control and Task Offloading in UAV-Assisted Mobile Edge Computing
Feb 24, 2022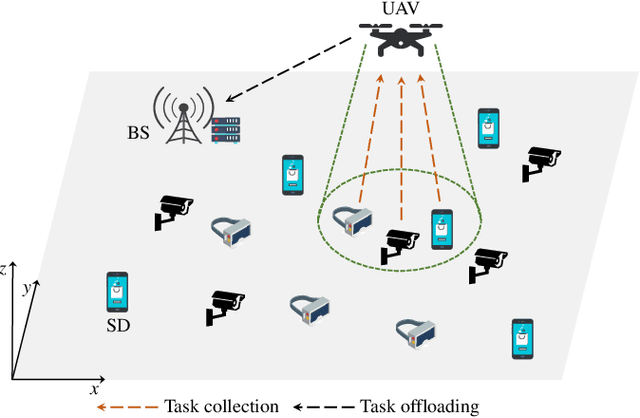

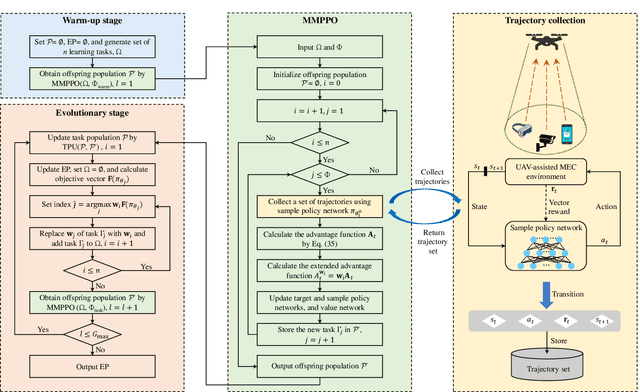
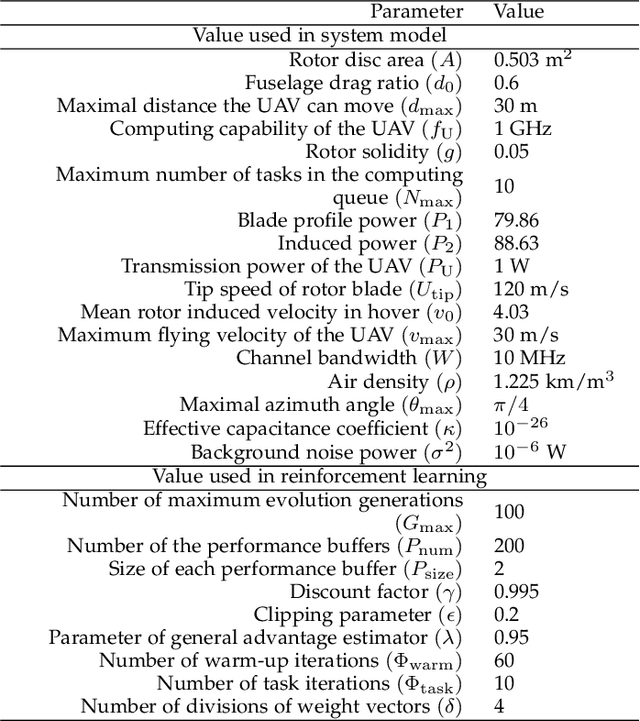
This paper studies the trajectory control and task offloading (TCTO) problem in an unmanned aerial vehicle (UAV)-assisted mobile edge computing system, where a UAV flies along a planned trajectory to collect computation tasks from smart devices (SDs). We consider a scenario that SDs are not directly connected by the base station (BS) and the UAV has two roles to play: MEC server or wireless relay. The UAV makes task offloading decisions online, in which the collected tasks can be executed locally on the UAV or offloaded to the BS for remote processing. The TCTO problem involves multi-objective optimization as its objectives are to minimize the task delay and the UAV's energy consumption, and maximize the number of tasks collected by the UAV, simultaneously. This problem is challenging because the three objectives conflict with each other. The existing reinforcement learning (RL) algorithms, either single-objective RLs or single-policy multi-objective RLs, cannot well address the problem since they cannot output multiple policies for various preferences (i.e. weights) across objectives in a single run. This paper adapts the evolutionary multi-objective RL (EMORL), a multi-policy multi-objective RL, to the TCTO problem. This algorithm can output multiple optimal policies in just one run, each optimizing a certain preference. The simulation results demonstrate that the proposed algorithm can obtain more excellent nondominated policies by striking a balance between the three objectives regarding policy quality, compared with two evolutionary and two multi-policy RL algorithms.
An Efficient Federated Distillation Learning System for Multi-task Time Series Classification
Dec 30, 2021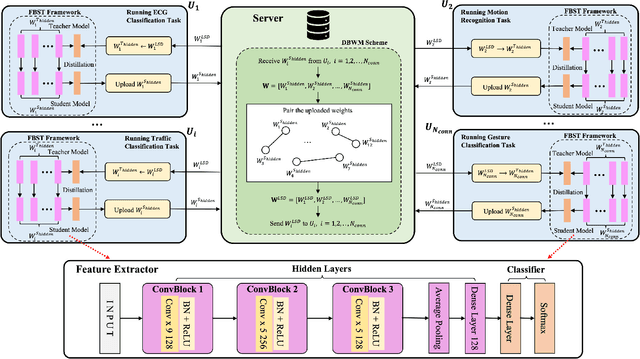
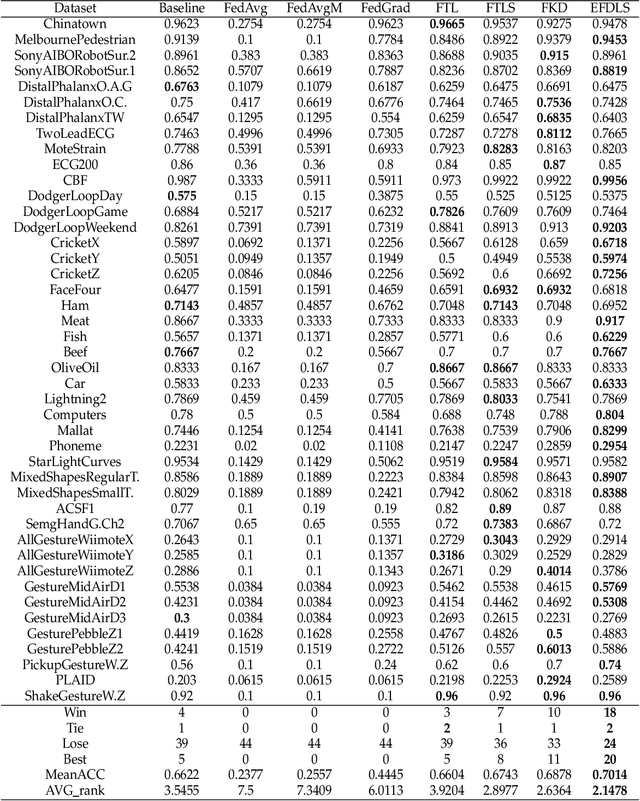
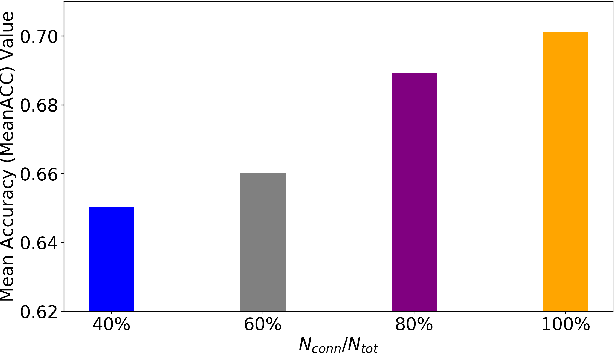
This paper proposes an efficient federated distillation learning system (EFDLS) for multi-task time series classification (TSC). EFDLS consists of a central server and multiple mobile users, where different users may run different TSC tasks. EFDLS has two novel components, namely a feature-based student-teacher (FBST) framework and a distance-based weights matching (DBWM) scheme. Within each user, the FBST framework transfers knowledge from its teacher's hidden layers to its student's hidden layers via knowledge distillation, with the teacher and student having identical network structure. For each connected user, its student model's hidden layers' weights are uploaded to the EFDLS server periodically. The DBWM scheme is deployed on the server, with the least square distance used to measure the similarity between the weights of two given models. This scheme finds a partner for each connected user such that the user's and its partner's weights are the closest among all the weights uploaded. The server exchanges and sends back the user's and its partner's weights to these two users which then load the received weights to their teachers' hidden layers. Experimental results show that the proposed EFDLS achieves excellent performance on a set of selected UCR2018 datasets regarding top-1 accuracy.
RTFN: A Robust Temporal Feature Network for Time Series Classification
Nov 24, 2020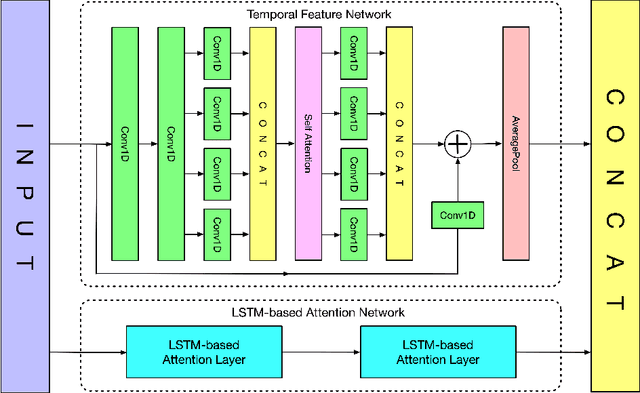
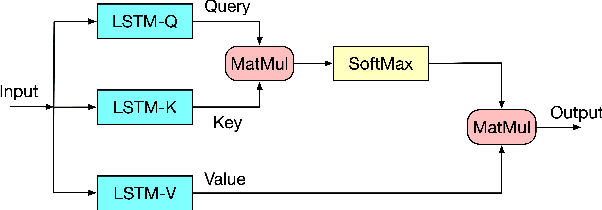
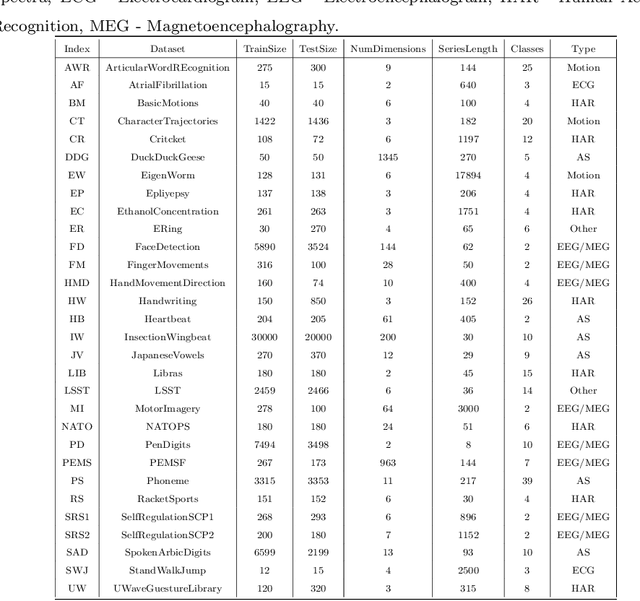
Time series data usually contains local and global patterns. Most of the existing feature networks pay more attention to local features rather than the relationships among them. The latter is, however, also important yet more difficult to explore. To obtain sufficient representations by a feature network is still challenging. To this end, we propose a novel robust temporal feature network (RTFN) for feature extraction in time series classification, containing a temporal feature network (TFN) and an LSTM-based attention network (LSTMaN). TFN is a residual structure with multiple convolutional layers. It functions as a local-feature extraction network to mine sufficient local features from data. LSTMaN is composed of two identical layers, where attention and long short-term memory (LSTM) networks are hybridized. This network acts as a relation extraction network to discover the intrinsic relationships among the extracted features at different positions in sequential data. In experiments, we embed RTFN into a supervised structure as a feature extractor and into an unsupervised structure as an encoder, respectively. The results show that the RTFN-based structures achieve excellent supervised and unsupervised performance on a large number of UCR2018 and UEA2018 datasets.
RTFN: Robust Temporal Feature Network
Aug 18, 2020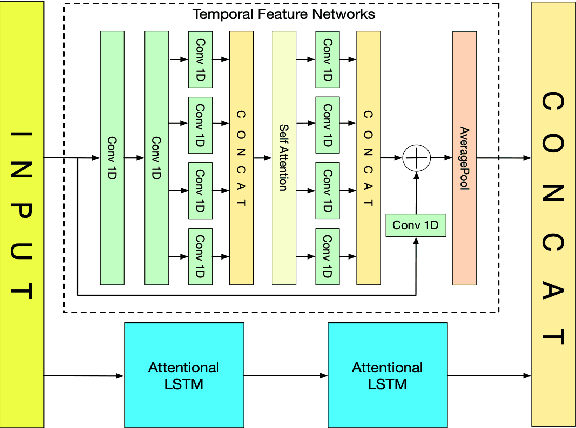

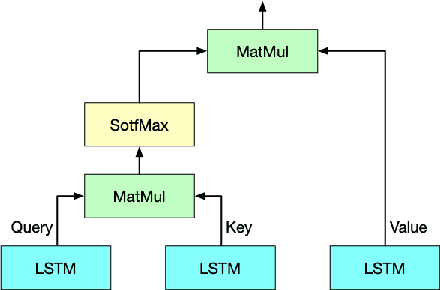
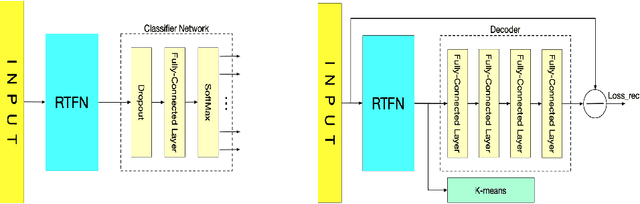
Time series analysis plays a vital role in various applications, for instance, healthcare, weather prediction, disaster forecast, etc. However, to obtain sufficient shapelets by a feature network is still challenging. To this end, we propose a novel robust temporal feature network (RTFN) that contains temporal feature networks and attentional LSTM networks. The temporal feature networks are built to extract basic features from input data while the attentional LSTM networks are devised to capture complicated shapelets and relationships to enrich features. In experiments, we embed RTFN into supervised structure as a feature extraction network and into unsupervised clustering as an encoder, respectively. The results show that the RTFN-based supervised structure is a winner of 40 out of 85 datasets and the RTFN-based unsupervised clustering performs the best on 4 out of 11 datasets in the UCR2018 archive.
STDPG: A Spatio-Temporal Deterministic Policy Gradient Agent for Dynamic Routing in SDN
Apr 21, 2020
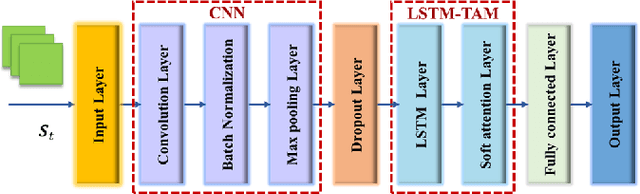
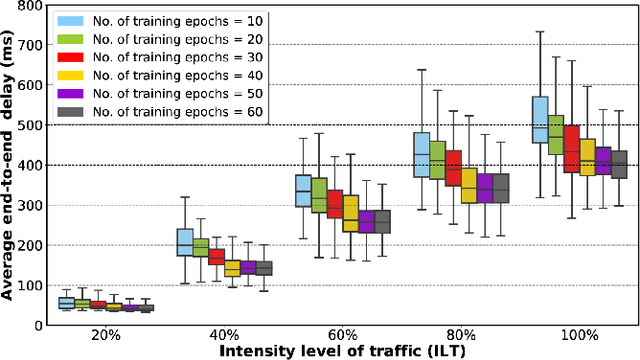

Dynamic routing in software-defined networking (SDN) can be viewed as a centralized decision-making problem. Most of the existing deep reinforcement learning (DRL) agents can address it, thanks to the deep neural network (DNN)incorporated. However, fully-connected feed-forward neural network (FFNN) is usually adopted, where spatial correlation and temporal variation of traffic flows are ignored. This drawback usually leads to significantly high computational complexity due to large number of training parameters. To overcome this problem, we propose a novel model-free framework for dynamic routing in SDN, which is referred to as spatio-temporal deterministic policy gradient (STDPG) agent. Both the actor and critic networks are based on identical DNN structure, where a combination of convolutional neural network (CNN) and long short-term memory network (LSTM) with temporal attention mechanism, CNN-LSTM-TAM, is devised. By efficiently exploiting spatial and temporal features, CNNLSTM-TAM helps the STDPG agent learn better from the experience transitions. Furthermore, we employ the prioritized experience replay (PER) method to accelerate the convergence of model training. The experimental results show that STDPG can automatically adapt for current network environment and achieve robust convergence. Compared with a number state-ofthe-art DRL agents, STDPG achieves better routing solutions in terms of the average end-to-end delay.