 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicGUI-RMS: A Multi-Agent Reward Model System for Self-Evolving GUI Agents via Automated Feedback Reflux
Jan 19, 2026Graphical user interface (GUI) agents are rapidly progressing toward autonomous interaction and reliable task execution across diverse applications. However, two central challenges remain unresolved: automating the evaluation of agent trajectories and generating high-quality training data at scale to enable continual improvement. Existing approaches often depend on manual annotation or static rule-based verification, which restricts scalability and limits adaptability in dynamic environments. We present MagicGUI-RMS, a multi-agent reward model system that delivers adaptive trajectory evaluation, corrective feedback, and self-evolving learning capabilities. MagicGUI-RMS integrates a Domain-Specific Reward Model (DS-RM) with a General-Purpose Reward Model (GP-RM), enabling fine-grained action assessment and robust generalization across heterogeneous GUI tasks. To support reward learning at scale, we design a structured data construction pipeline that automatically produces balanced and diverse reward datasets, effectively reducing annotation costs while maintaining sample fidelity. During execution, the reward model system identifies erroneous actions, proposes refined alternatives, and continuously enhances agent behavior through an automated data-reflux mechanism. Extensive experiments demonstrate that MagicGUI-RMS yields substantial gains in task accuracy, behavioral robustness. These results establish MagicGUI-RMS as a principled and effective foundation for building self-improving GUI agents driven by reward-based adaptation.
MGML: A Plug-and-Play Meta-Guided Multi-Modal Learning Framework for Incomplete Multimodal Brain Tumor Segmentation
Dec 30, 2025Leveraging multimodal information from Magnetic Resonance Imaging (MRI) plays a vital role in lesion segmentation, especially for brain tumors. However, in clinical practice, multimodal MRI data are often incomplete, making it challenging to fully utilize the available information. Therefore, maximizing the utilization of this incomplete multimodal information presents a crucial research challenge. We present a novel meta-guided multi-modal learning (MGML) framework that comprises two components: meta-parameterized adaptive modality fusion and consistency regularization module. The meta-parameterized adaptive modality fusion (Meta-AMF) enables the model to effectively integrate information from multiple modalities under varying input conditions. By generating adaptive soft-label supervision signals based on the available modalities, Meta-AMF explicitly promotes more coherent multimodal fusion. In addition, the consistency regularization module enhances segmentation performance and implicitly reinforces the robustness and generalization of the overall framework. Notably, our approach does not alter the original model architecture and can be conveniently integrated into the training pipeline for end-to-end model optimization. We conducted extensive experiments on the public BraTS2020 and BraTS2023 datasets. Compared to multiple state-of-the-art methods from previous years, our method achieved superior performance. On BraTS2020, for the average Dice scores across fifteen missing modality combinations, building upon the baseline, our method obtained scores of 87.55, 79.36, and 62.67 for the whole tumor (WT), the tumor core (TC), and the enhancing tumor (ET), respectively. We have made our source code publicly available at https://github.com/worldlikerr/MGML.
Task-Oriented Data Synthesis and Control-Rectify Sampling for Remote Sensing Semantic Segmentation
Dec 18, 2025With the rapid progress of controllable generation, training data synthesis has become a promising way to expand labeled datasets and alleviate manual annotation in remote sensing (RS). However, the complexity of semantic mask control and the uncertainty of sampling quality often limit the utility of synthetic data in downstream semantic segmentation tasks. To address these challenges, we propose a task-oriented data synthesis framework (TODSynth), including a Multimodal Diffusion Transformer (MM-DiT) with unified triple attention and a plug-and-play sampling strategy guided by task feedback. Built upon the powerful DiT-based generative foundation model, we systematically evaluate different control schemes, showing that a text-image-mask joint attention scheme combined with full fine-tuning of the image and mask branches significantly enhances the effectiveness of RS semantic segmentation data synthesis, particularly in few-shot and complex-scene scenarios. Furthermore, we propose a control-rectify flow matching (CRFM) method, which dynamically adjusts sampling directions guided by semantic loss during the early high-plasticity stage, mitigating the instability of generated images and bridging the gap between synthetic data and downstream segmentation tasks. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art controllable generation methods, producing more stable and task-oriented synthetic data for RS semantic segmentation.
VisMem: Latent Vision Memory Unlocks Potential of Vision-Language Models
Nov 14, 2025Despite the remarkable success of Vision-Language Models (VLMs), their performance on a range of complex visual tasks is often hindered by a "visual processing bottleneck": a propensity to lose grounding in visual evidence and exhibit a deficit in contextualized visual experience during prolonged generation. Drawing inspiration from human cognitive memory theory, which distinguishes short-term visually-dominant memory and long-term semantically-dominant memory, we propose VisMem, a cognitively-aligned framework that equips VLMs with dynamic latent vision memories, a short-term module for fine-grained perceptual retention and a long-term module for abstract semantic consolidation. These memories are seamlessly invoked during inference, allowing VLMs to maintain both perceptual fidelity and semantic consistency across thinking and generation. Extensive experiments across diverse visual benchmarks for understanding, reasoning, and generation reveal that VisMem delivers a significant average performance boost of 11.8% relative to the vanilla model and outperforms all counterparts, establishing a new paradigm for latent-space memory enhancement. The code will be available: https://github.com/YU-deep/VisMem.git.
MG2FlowNet: Accelerating High-Reward Sample Generation via Enhanced MCTS and Greediness Control
Oct 01, 2025



Generative Flow Networks (GFlowNets) have emerged as a powerful tool for generating diverse and high-reward structured objects by learning to sample from a distribution proportional to a given reward function. Unlike conventional reinforcement learning (RL) approaches that prioritize optimization of a single trajectory, GFlowNets seek to balance diversity and reward by modeling the entire trajectory distribution. This capability makes them especially suitable for domains such as molecular design and combinatorial optimization. However, existing GFlowNets sampling strategies tend to overexplore and struggle to consistently generate high-reward samples, particularly in large search spaces with sparse high-reward regions. Therefore, improving the probability of generating high-reward samples without sacrificing diversity remains a key challenge under this premise. In this work, we integrate an enhanced Monte Carlo Tree Search (MCTS) into the GFlowNets sampling process, using MCTS-based policy evaluation to guide the generation toward high-reward trajectories and Polynomial Upper Confidence Trees (PUCT) to balance exploration and exploitation adaptively, and we introduce a controllable mechanism to regulate the degree of greediness. Our method enhances exploitation without sacrificing diversity by dynamically balancing exploration and reward-driven guidance. The experimental results show that our method can not only accelerate the speed of discovering high-reward regions but also continuously generate high-reward samples, while preserving the diversity of the generative distribution. All implementations are available at https://github.com/ZRNB/MG2FlowNet.
Cross-Modal Clustering-Guided Negative Sampling for Self-Supervised Joint Learning from Medical Images and Reports
Jun 13, 2025Learning medical visual representations directly from paired images and reports through multimodal self-supervised learning has emerged as a novel and efficient approach to digital diagnosis in recent years. However, existing models suffer from several severe limitations. 1) neglecting the selection of negative samples, resulting in the scarcity of hard negatives and the inclusion of false negatives; 2) focusing on global feature extraction, but overlooking the fine-grained local details that are crucial for medical image recognition tasks; and 3) contrastive learning primarily targets high-level features but ignoring low-level details which are essential for accurate medical analysis. Motivated by these critical issues, this paper presents a Cross-Modal Cluster-Guided Negative Sampling (CM-CGNS) method with two-fold ideas. First, it extends the k-means clustering used for local text features in the single-modal domain to the multimodal domain through cross-modal attention. This improvement increases the number of negative samples and boosts the model representation capability. Second, it introduces a Cross-Modal Masked Image Reconstruction (CM-MIR) module that leverages local text-to-image features obtained via cross-modal attention to reconstruct masked local image regions. This module significantly strengthens the model's cross-modal information interaction capabilities and retains low-level image features essential for downstream tasks. By well handling the aforementioned limitations, the proposed CM-CGNS can learn effective and robust medical visual representations suitable for various recognition tasks. Extensive experimental results on classification, detection, and segmentation tasks across five downstream datasets show that our method outperforms state-of-the-art approaches on multiple metrics, verifying its superior performance.
DMAF-Net: An Effective Modality Rebalancing Framework for Incomplete Multi-Modal Medical Image Segmentation
Jun 13, 2025Incomplete multi-modal medical image segmentation faces critical challenges from modality imbalance, including imbalanced modality missing rates and heterogeneous modality contributions. Due to their reliance on idealized assumptions of complete modality availability, existing methods fail to dynamically balance contributions and neglect the structural relationships between modalities, resulting in suboptimal performance in real-world clinical scenarios. To address these limitations, we propose a novel model, named Dynamic Modality-Aware Fusion Network (DMAF-Net). The DMAF-Net adopts three key ideas. First, it introduces a Dynamic Modality-Aware Fusion (DMAF) module to suppress missing-modality interference by combining transformer attention with adaptive masking and weight modality contributions dynamically through attention maps. Second, it designs a synergistic Relation Distillation and Prototype Distillation framework to enforce global-local feature alignment via covariance consistency and masked graph attention, while ensuring semantic consistency through cross-modal class-specific prototype alignment. Third, it presents a Dynamic Training Monitoring (DTM) strategy to stabilize optimization under imbalanced missing rates by tracking distillation gaps in real-time, and to balance convergence speeds across modalities by adaptively reweighting losses and scaling gradients. Extensive experiments on BraTS2020 and MyoPS2020 demonstrate that DMAF-Net outperforms existing methods for incomplete multi-modal medical image segmentation. Extensive experiments on BraTS2020 and MyoPS2020 demonstrate that DMAF-Net outperforms existing methods for incomplete multi-modal medical image segmentation. Our code is available at https://github.com/violet-42/DMAF-Net.
SWDL: Stratum-Wise Difference Learning with Deep Laplacian Pyramid for Semi-Supervised 3D Intracranial Hemorrhage Segmentation
Jun 12, 2025Recent advances in medical imaging have established deep learning-based segmentation as the predominant approach, though it typically requires large amounts of manually annotated data. However, obtaining annotations for intracranial hemorrhage (ICH) remains particularly challenging due to the tedious and costly labeling process. Semi-supervised learning (SSL) has emerged as a promising solution to address the scarcity of labeled data, especially in volumetric medical image segmentation. Unlike conventional SSL methods that primarily focus on high-confidence pseudo-labels or consistency regularization, we propose SWDL-Net, a novel SSL framework that exploits the complementary advantages of Laplacian pyramid and deep convolutional upsampling. The Laplacian pyramid excels at edge sharpening, while deep convolutions enhance detail precision through flexible feature mapping. Our framework achieves superior segmentation of lesion details and boundaries through a difference learning mechanism that effectively integrates these complementary approaches. Extensive experiments on a 271-case ICH dataset and public benchmarks demonstrate that SWDL-Net outperforms current state-of-the-art methods in scenarios with only 2% labeled data. Additional evaluations on the publicly available Brain Hemorrhage Segmentation Dataset (BHSD) with 5% labeled data further confirm the superiority of our approach. Code and data have been released at https://github.com/SIAT-CT-LAB/SWDL.
MSLAU-Net: A Hybird CNN-Transformer Network for Medical Image Segmentation
May 24, 2025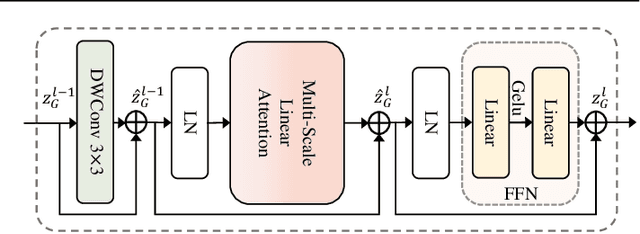
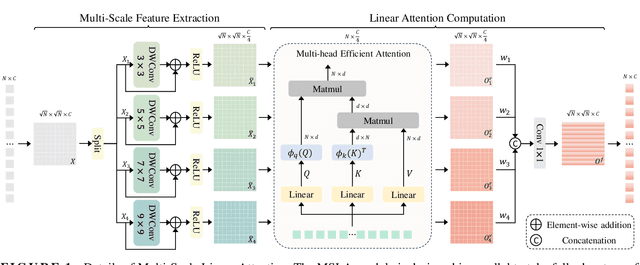
Both CNN-based and Transformer-based methods have achieved remarkable success in medical image segmentation tasks. However, CNN-based methods struggle to effectively capture global contextual information due to the inherent limitations of convolution operations. Meanwhile, Transformer-based methods suffer from insufficient local feature modeling and face challenges related to the high computational complexity caused by the self-attention mechanism. To address these limitations, we propose a novel hybrid CNN-Transformer architecture, named MSLAU-Net, which integrates the strengths of both paradigms. The proposed MSLAU-Net incorporates two key ideas. First, it introduces Multi-Scale Linear Attention, designed to efficiently extract multi-scale features from medical images while modeling long-range dependencies with low computational complexity. Second, it adopts a top-down feature aggregation mechanism, which performs multi-level feature aggregation and restores spatial resolution using a lightweight structure. Extensive experiments conducted on benchmark datasets covering three imaging modalities demonstrate that the proposed MSLAU-Net outperforms other state-of-the-art methods on nearly all evaluation metrics, validating the superiority, effectiveness, and robustness of our approach. Our code is available at https://github.com/Monsoon49/MSLAU-Net.
QAVA: Query-Agnostic Visual Attack to Large Vision-Language Models
Apr 15, 2025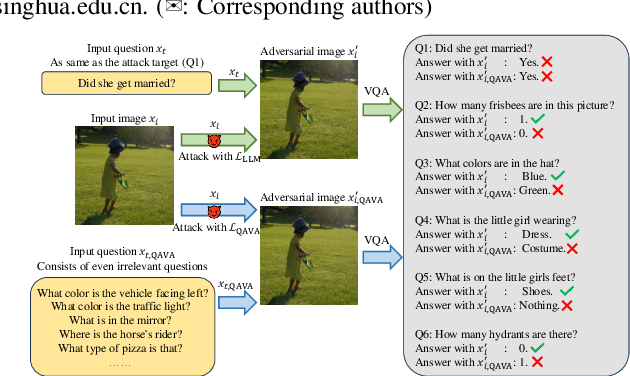
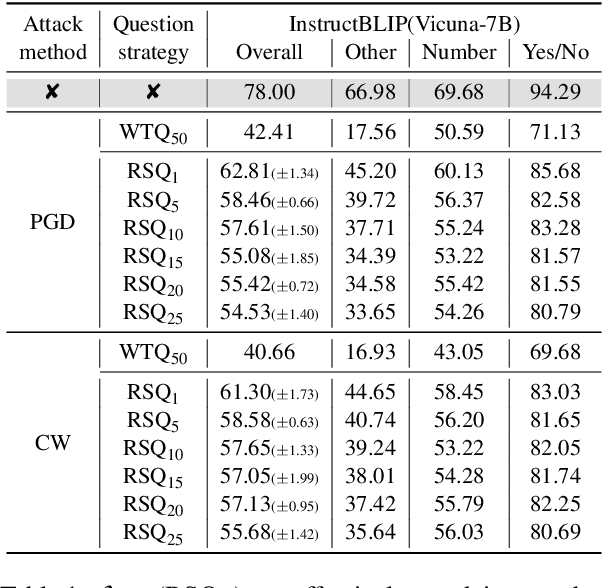
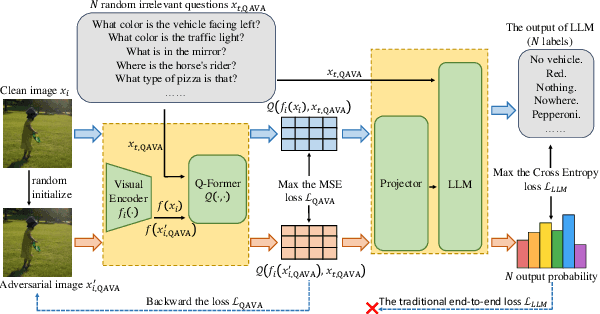
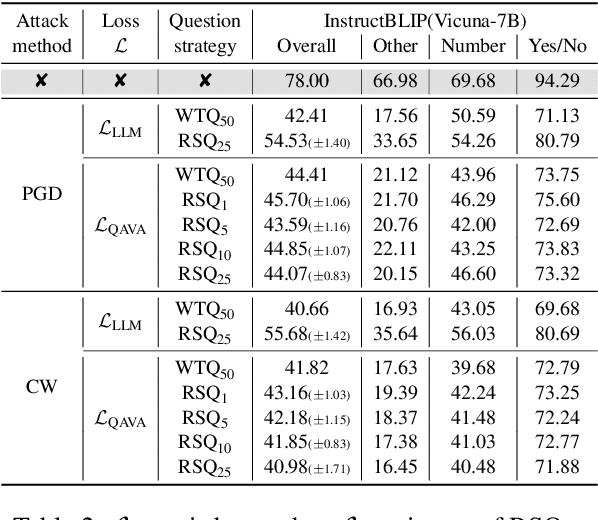
In typical multimodal tasks, such as Visual Question Answering (VQA), adversarial attacks targeting a specific image and question can lead large vision-language models (LVLMs) to provide incorrect answers. However, it is common for a single image to be associated with multiple questions, and LVLMs may still answer other questions correctly even for an adversarial image attacked by a specific question. To address this, we introduce the query-agnostic visual attack (QAVA), which aims to create robust adversarial examples that generate incorrect responses to unspecified and unknown questions. Compared to traditional adversarial attacks focused on specific images and questions, QAVA significantly enhances the effectiveness and efficiency of attacks on images when the question is unknown, achieving performance comparable to attacks on known target questions. Our research broadens the scope of visual adversarial attacks on LVLMs in practical settings, uncovering previously overlooked vulnerabilities, particularly in the context of visual adversarial threats. The code is available at https://github.com/btzyd/qava.