 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDV-World: Benchmarking Data Visualization Agents in Real-World Scenarios
Apr 28, 2026Real-world data visualization (DV) requires native environmental grounding, cross-platform evolution, and proactive intent alignment. Yet, existing benchmarks often suffer from code-sandbox confinement, single-language creation-only tasks, and assumption of perfect intent. To bridge these gaps, we introduce DV-World, a benchmark of 260 tasks designed to evaluate DV agents across real-world professional lifecycles. DV-World spans three domains: DV-Sheet for native spreadsheet manipulation including chart and dashboard creation as well as diagnostic repair; DV-Evolution for adapting and restructuring reference visual artifacts to fit new data across diverse programming paradigms and DV-Interact for proactive intent alignment with a user simulator that mimics real-world ambiguous requirements. Our hybrid evaluation framework integrates Table-value Alignment for numerical precision and MLLM-as-a-Judge with rubrics for semantic-visual assessment. Experiments reveal that state-of-the-art models achieve less than 50% overall performance, exposing critical deficits in handling the complex challenges of real-world data visualization. DV-World provides a realistic testbed to steer development toward the versatile expertise required in enterprise workflows. Our data and code are available at \href{https://github.com/DA-Open/DV-World}{this project page}.
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
Apr 20, 2026Large language models are increasingly expected to serve as general-purpose agents that interact with external, stateful tool environments. The Model Context Protocol (MCP) and broader agent skills offer a unified interface for connecting agents with scalable real-world services, but training robust agents remains limited by the lack of realistic environments and principled mechanisms for life-long learning. In this paper, we present \textbf{Agent-World}, a self-evolving training arena for advancing general agent intelligence through scalable environments. Agent-World has two main components: (1) Agentic Environment-Task Discovery, which autonomously explores topic-aligned databases and executable tool ecosystems from thousands of real-world environment themes and synthesizes verifiable tasks with controllable difficulty; and (2) Continuous Self-Evolving Agent Training, which combines multi-environment reinforcement learning with a self-evolving agent arena that automatically identifies capability gaps through dynamic task synthesis and drives targeted learning, enabling the co-evolution of agent policies and environments. Across 23 challenging agent benchmarks, Agent-World-8B and 14B consistently outperforms strong proprietary models and environment scaling baselines. Further analyses reveal scaling trends in relation to environment diversity and self-evolution rounds, offering insights for building general agent intelligence.
OpenCUA: Open Foundations for Computer-Use Agents
Aug 12, 2025Vision-language models have demonstrated impressive capabilities as computer-use agents (CUAs) capable of automating diverse computer tasks. As their commercial potential grows, critical details of the most capable CUA systems remain closed. As these agents will increasingly mediate digital interactions and execute consequential decisions on our behalf, the research community needs access to open CUA frameworks to study their capabilities, limitations, and risks. To bridge this gap, we propose OpenCUA, a comprehensive open-source framework for scaling CUA data and foundation models. Our framework consists of: (1) an annotation infrastructure that seamlessly captures human computer-use demonstrations; (2) AgentNet, the first large-scale computer-use task dataset spanning 3 operating systems and 200+ applications and websites; (3) a scalable pipeline that transforms demonstrations into state-action pairs with reflective long Chain-of-Thought reasoning that sustain robust performance gains as data scales. Our end-to-end agent models demonstrate strong performance across CUA benchmarks. In particular, OpenCUA-32B achieves an average success rate of 34.8% on OSWorld-Verified, establishing a new state-of-the-art (SOTA) among open-source models and surpassing OpenAI CUA (GPT-4o). Further analysis confirms that our approach generalizes well across domains and benefits significantly from increased test-time computation. We release our annotation tool, datasets, code, and models to build open foundations for further CUA research.
Amplify Adjacent Token Differences: Enhancing Long Chain-of-Thought Reasoning with Shift-FFN
May 22, 2025Recently, models such as OpenAI-o1 and DeepSeek-R1 have demonstrated remarkable performance on complex reasoning tasks through Long Chain-of-Thought (Long-CoT) reasoning. Although distilling this capability into student models significantly enhances their performance, this paper finds that fine-tuning LLMs with full parameters or LoRA with a low rank on long CoT data often leads to Cyclical Reasoning, where models repeatedly reiterate previous inference steps until the maximum length limit. Further analysis reveals that smaller differences in representations between adjacent tokens correlates with a higher tendency toward Cyclical Reasoning. To mitigate this issue, this paper proposes Shift Feedforward Networks (Shift-FFN), a novel approach that edits the current token's representation with the previous one before inputting it to FFN. This architecture dynamically amplifies the representation differences between adjacent tokens. Extensive experiments on multiple mathematical reasoning tasks demonstrate that LoRA combined with Shift-FFN achieves higher accuracy and a lower rate of Cyclical Reasoning across various data sizes compared to full fine-tuning and standard LoRA. Our data and code are available at https://anonymous.4open.science/r/Shift-FFN
GATE: Graph-based Adaptive Tool Evolution Across Diverse Tasks
Feb 20, 2025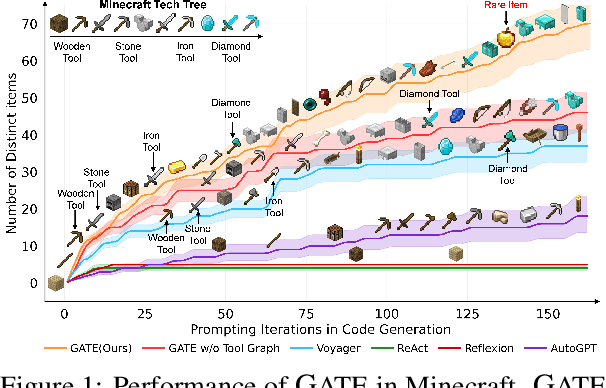
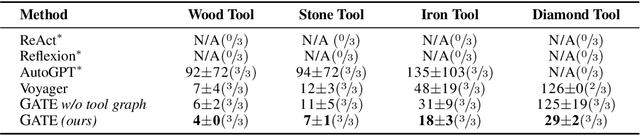
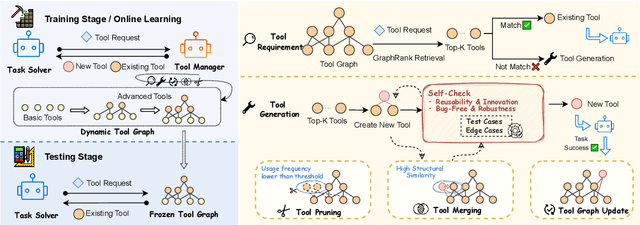
Large Language Models (LLMs) have shown great promise in tool-making, yet existing frameworks often struggle to efficiently construct reliable toolsets and are limited to single-task settings. To address these challenges, we propose GATE (Graph-based Adaptive Tool Evolution), an adaptive framework that dynamically constructs and evolves a hierarchical graph of reusable tools across multiple scenarios. We evaluate GATE on open-ended tasks (Minecraft), agent-based tasks (TextCraft, DABench), and code generation tasks (MATH, Date, TabMWP). Our results show that GATE achieves up to 4.3x faster milestone completion in Minecraft compared to the previous SOTA, and provides an average improvement of 9.23% over existing tool-making methods in code generation tasks and 10.03% in agent tasks. GATE demonstrates the power of adaptive evolution, balancing tool quantity, complexity, and functionality while maintaining high efficiency. Code and data are available at \url{https://github.com/ayanami2003/GATE}.
Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows
Nov 12, 2024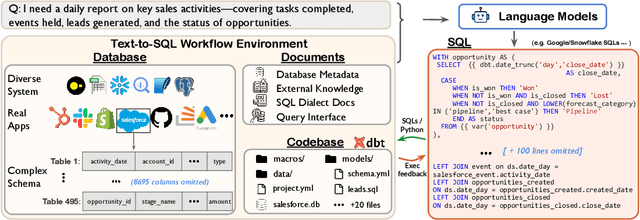


Real-world enterprise text-to-SQL workflows often involve complex cloud or local data across various database systems, multiple SQL queries in various dialects, and diverse operations from data transformation to analytics. We introduce Spider 2.0, an evaluation framework comprising 632 real-world text-to-SQL workflow problems derived from enterprise-level database use cases. The databases in Spider 2.0 are sourced from real data applications, often containing over 1,000 columns and stored in local or cloud database systems such as BigQuery and Snowflake. We show that solving problems in Spider 2.0 frequently requires understanding and searching through database metadata, dialect documentation, and even project-level codebases. This challenge calls for models to interact with complex SQL workflow environments, process extremely long contexts, perform intricate reasoning, and generate multiple SQL queries with diverse operations, often exceeding 100 lines, which goes far beyond traditional text-to-SQL challenges. Our evaluations indicate that based on o1-preview, our code agent framework successfully solves only 17.0% of the tasks, compared with 91.2% on Spider 1.0 and 73.0% on BIRD. Our results on Spider 2.0 show that while language models have demonstrated remarkable performance in code generation -- especially in prior text-to-SQL benchmarks -- they require significant improvement in order to achieve adequate performance for real-world enterprise usage. Progress on Spider 2.0 represents crucial steps towards developing intelligent, autonomous, code agents for real-world enterprise settings. Our code, baseline models, and data are available at https://spider2-sql.github.io.
DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models
Oct 09, 2024


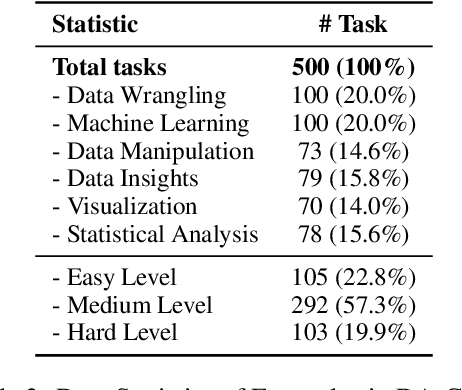
We introduce DA-Code, a code generation benchmark specifically designed to assess LLMs on agent-based data science tasks. This benchmark features three core elements: First, the tasks within DA-Code are inherently challenging, setting them apart from traditional code generation tasks and demanding advanced coding skills in grounding and planning. Second, examples in DA-Code are all based on real and diverse data, covering a wide range of complex data wrangling and analytics tasks. Third, to solve the tasks, the models must utilize complex data science programming languages, to perform intricate data processing and derive the answers. We set up the benchmark in a controllable and executable environment that aligns with real-world data analysis scenarios and is scalable. The annotators meticulously design the evaluation suite to ensure the accuracy and robustness of the evaluation. We develop the DA-Agent baseline. Experiments show that although the baseline performs better than other existing frameworks, using the current best LLMs achieves only 30.5% accuracy, leaving ample room for improvement. We release our benchmark at [https://da-code-bench.github.io](https://da-code-bench.github.io).
Spider2-V: How Far Are Multimodal Agents From Automating Data Science and Engineering Workflows?
Jul 15, 2024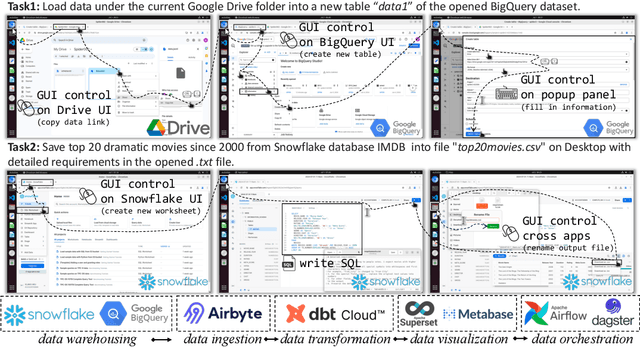
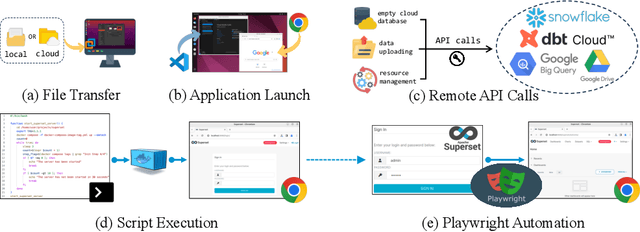
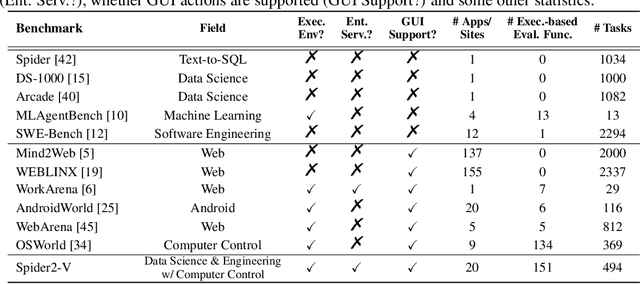
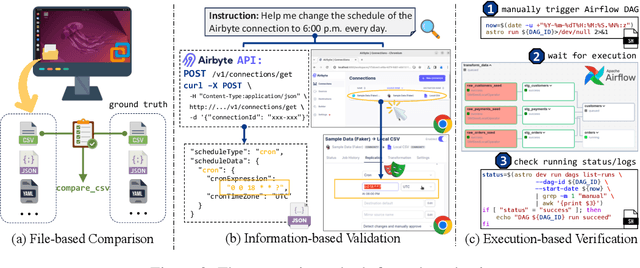
Data science and engineering workflows often span multiple stages, from warehousing to orchestration, using tools like BigQuery, dbt, and Airbyte. As vision language models (VLMs) advance in multimodal understanding and code generation, VLM-based agents could potentially automate these workflows by generating SQL queries, Python code, and GUI operations. This automation can improve the productivity of experts while democratizing access to large-scale data analysis. In this paper, we introduce Spider2-V, the first multimodal agent benchmark focusing on professional data science and engineering workflows, featuring 494 real-world tasks in authentic computer environments and incorporating 20 enterprise-level professional applications. These tasks, derived from real-world use cases, evaluate the ability of a multimodal agent to perform data-related tasks by writing code and managing the GUI in enterprise data software systems. To balance realistic simulation with evaluation simplicity, we devote significant effort to developing automatic configurations for task setup and carefully crafting evaluation metrics for each task. Furthermore, we supplement multimodal agents with comprehensive documents of these enterprise data software systems. Our empirical evaluation reveals that existing state-of-the-art LLM/VLM-based agents do not reliably automate full data workflows (14.0% success). Even with step-by-step guidance, these agents still underperform in tasks that require fine-grained, knowledge-intensive GUI actions (16.2%) and involve remote cloud-hosted workspaces (10.6%). We hope that Spider2-V paves the way for autonomous multimodal agents to transform the automation of data science and engineering workflow. Our code and data are available at https://spider2-v.github.io.
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Apr 11, 2024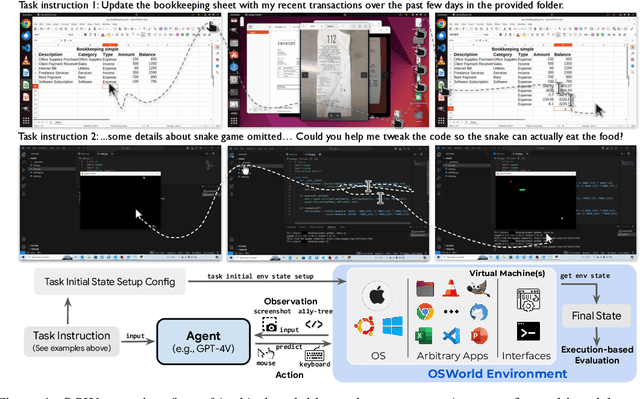

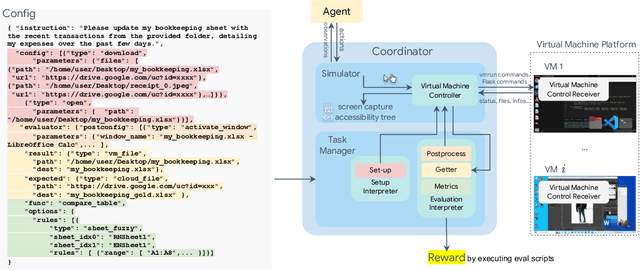

Autonomous agents that accomplish complex computer tasks with minimal human interventions have the potential to transform human-computer interaction, significantly enhancing accessibility and productivity. However, existing benchmarks either lack an interactive environment or are limited to environments specific to certain applications or domains, failing to reflect the diverse and complex nature of real-world computer use, thereby limiting the scope of tasks and agent scalability. To address this issue, we introduce OSWorld, the first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating systems such as Ubuntu, Windows, and macOS. OSWorld can serve as a unified, integrated computer environment for assessing open-ended computer tasks that involve arbitrary applications. Building upon OSWorld, we create a benchmark of 369 computer tasks involving real web and desktop apps in open domains, OS file I/O, and workflows spanning multiple applications. Each task example is derived from real-world computer use cases and includes a detailed initial state setup configuration and a custom execution-based evaluation script for reliable, reproducible evaluation. Extensive evaluation of state-of-the-art LLM/VLM-based agents on OSWorld reveals significant deficiencies in their ability to serve as computer assistants. While humans can accomplish over 72.36% of the tasks, the best model achieves only 12.24% success, primarily struggling with GUI grounding and operational knowledge. Comprehensive analysis using OSWorld provides valuable insights for developing multimodal generalist agents that were not possible with previous benchmarks. Our code, environment, baseline models, and data are publicly available at https://os-world.github.io.
Neeko: Leveraging Dynamic LoRA for Efficient Multi-Character Role-Playing Agent
Mar 01, 2024



Large Language Models (LLMs) have revolutionized open-domain dialogue agents but encounter challenges in multi-character role-playing (MCRP) scenarios. To address the issue, we present Neeko, an innovative framework designed for efficient multiple characters imitation. Unlike existing methods, Neeko employs a dynamic low-rank adapter (LoRA) strategy, enabling it to adapt seamlessly to diverse characters. Our framework breaks down the role-playing process into agent pre-training, multiple characters playing, and character incremental learning, effectively handling both seen and unseen roles. This dynamic approach, coupled with distinct LoRA blocks for each character, enhances Neeko's adaptability to unique attributes, personalities, and speaking patterns. As a result, Neeko demonstrates superior performance in MCRP over most existing methods, offering more engaging and versatile user interaction experiences. Code and data are available at https://github.com/weiyifan1023/Neeko.