 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuSym-RAG: Hybrid Neural Symbolic Retrieval with Multiview Structuring for PDF Question Answering
May 26, 2025The increasing number of academic papers poses significant challenges for researchers to efficiently acquire key details. While retrieval augmented generation (RAG) shows great promise in large language model (LLM) based automated question answering, previous works often isolate neural and symbolic retrieval despite their complementary strengths. Moreover, conventional single-view chunking neglects the rich structure and layout of PDFs, e.g., sections and tables. In this work, we propose NeuSym-RAG, a hybrid neural symbolic retrieval framework which combines both paradigms in an interactive process. By leveraging multi-view chunking and schema-based parsing, NeuSym-RAG organizes semi-structured PDF content into both the relational database and vectorstore, enabling LLM agents to iteratively gather context until sufficient to generate answers. Experiments on three full PDF-based QA datasets, including a self-annotated one AIRQA-REAL, show that NeuSym-RAG stably defeats both the vector-based RAG and various structured baselines, highlighting its capacity to unify both retrieval schemes and utilize multiple views. Code and data are publicly available at https://github.com/X-LANCE/NeuSym-RAG.
StoryTeller: Improving Long Video Description through Global Audio-Visual Character Identification
Nov 11, 2024
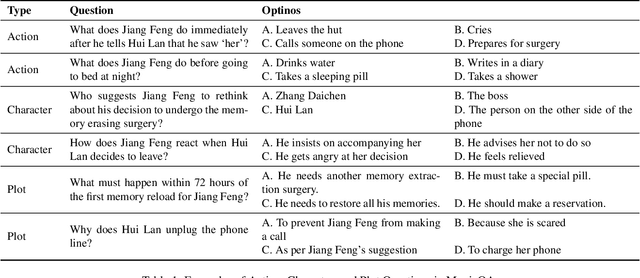

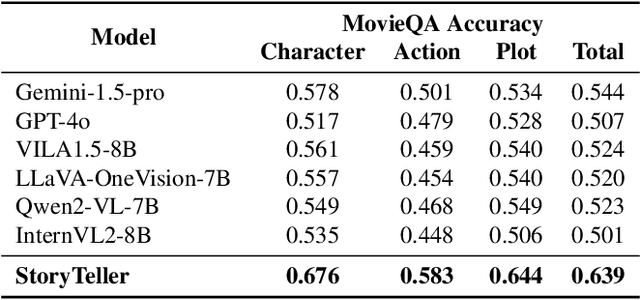
Existing large vision-language models (LVLMs) are largely limited to processing short, seconds-long videos and struggle with generating coherent descriptions for extended video spanning minutes or more. Long video description introduces new challenges, such as plot-level consistency across descriptions. To address these, we figure out audio-visual character identification, matching character names to each dialogue, as a key factor. We propose StoryTeller, a system for generating dense descriptions of long videos, incorporating both low-level visual concepts and high-level plot information. StoryTeller uses a multimodal large language model that integrates visual, audio, and text modalities to perform audio-visual character identification on minute-long video clips. The results are then fed into a LVLM to enhance consistency of video description. We validate our approach on movie description tasks and introduce MovieStory101, a dataset with dense descriptions for three-minute movie clips. To evaluate long video descriptions, we create MovieQA, a large set of multiple-choice questions for the MovieStory101 test set. We assess descriptions by inputting them into GPT-4 to answer these questions, using accuracy as an automatic evaluation metric. Experiments show that StoryTeller outperforms all open and closed-source baselines on MovieQA, achieving 9.5% higher accuracy than the strongest baseline, Gemini-1.5-pro, and demonstrating a +15.56% advantage in human side-by-side evaluations. Additionally, incorporating audio-visual character identification from StoryTeller improves the performance of all video description models, with Gemini-1.5-pro and GPT-4o showing relative improvement of 5.5% and 13.0%, respectively, in accuracy on MovieQA.
Spider2-V: How Far Are Multimodal Agents From Automating Data Science and Engineering Workflows?
Jul 15, 2024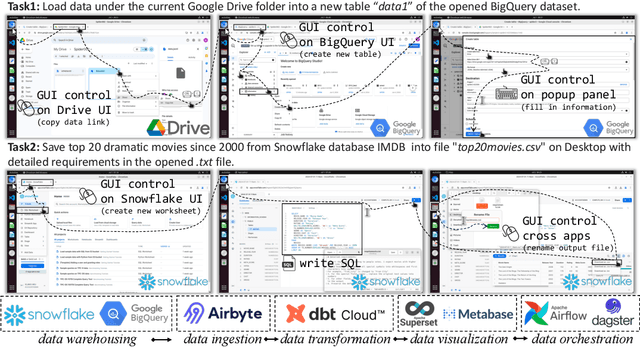
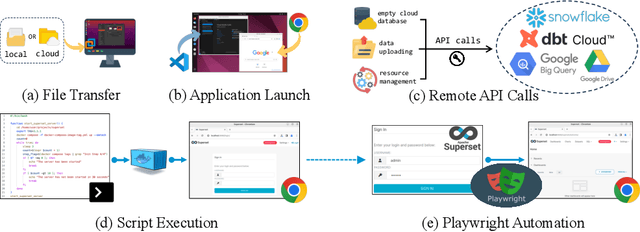
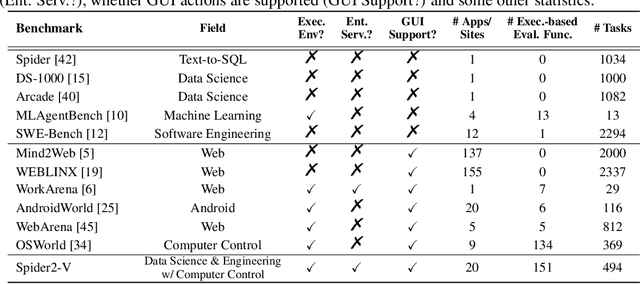
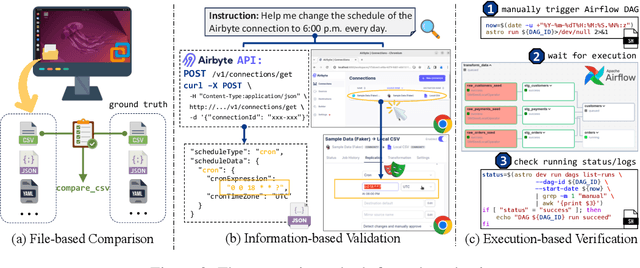
Data science and engineering workflows often span multiple stages, from warehousing to orchestration, using tools like BigQuery, dbt, and Airbyte. As vision language models (VLMs) advance in multimodal understanding and code generation, VLM-based agents could potentially automate these workflows by generating SQL queries, Python code, and GUI operations. This automation can improve the productivity of experts while democratizing access to large-scale data analysis. In this paper, we introduce Spider2-V, the first multimodal agent benchmark focusing on professional data science and engineering workflows, featuring 494 real-world tasks in authentic computer environments and incorporating 20 enterprise-level professional applications. These tasks, derived from real-world use cases, evaluate the ability of a multimodal agent to perform data-related tasks by writing code and managing the GUI in enterprise data software systems. To balance realistic simulation with evaluation simplicity, we devote significant effort to developing automatic configurations for task setup and carefully crafting evaluation metrics for each task. Furthermore, we supplement multimodal agents with comprehensive documents of these enterprise data software systems. Our empirical evaluation reveals that existing state-of-the-art LLM/VLM-based agents do not reliably automate full data workflows (14.0% success). Even with step-by-step guidance, these agents still underperform in tasks that require fine-grained, knowledge-intensive GUI actions (16.2%) and involve remote cloud-hosted workspaces (10.6%). We hope that Spider2-V paves the way for autonomous multimodal agents to transform the automation of data science and engineering workflow. Our code and data are available at https://spider2-v.github.io.
AGILE: A Novel Framework of LLM Agents
May 23, 2024



We introduce a novel framework of LLM agents named AGILE (AGent that Interacts and Learns from Environments) designed to perform complex conversational tasks with users, leveraging LLMs, memory, tools, and interactions with experts. The agent's abilities include not only conversation but also reflection, utilization of tools, and consultation with experts. We formulate the construction of such an LLM agent as a reinforcement learning problem, in which the LLM serves as the policy model. We fine-tune the LLM using labeled data of actions and the PPO algorithm. We focus on question answering and release a dataset for agents called ProductQA, comprising challenging questions in online shopping. Our extensive experiments on ProductQA and MedMCQA show that AGILE agents based on 13B and 7B LLMs trained with PPO can outperform GPT-4 agents. Our ablation study highlights the indispensability of memory, tools, consultation, reflection, and reinforcement learning in achieving the agent's strong performance.
CoE-SQL: In-Context Learning for Multi-Turn Text-to-SQL with Chain-of-Editions
May 04, 2024Recently, Large Language Models (LLMs) have been demonstrated to possess impressive capabilities in a variety of domains and tasks. We investigate the issue of prompt design in the multi-turn text-to-SQL task and attempt to enhance the LLMs' reasoning capacity when generating SQL queries. In the conversational context, the current SQL query can be modified from the preceding SQL query with only a few operations due to the context dependency. We introduce our method called CoE-SQL which can prompt LLMs to generate the SQL query based on the previously generated SQL query with an edition chain. We also conduct extensive ablation studies to determine the optimal configuration of our approach. Our approach outperforms different in-context learning baselines stably and achieves state-of-the-art performances on two benchmarks SParC and CoSQL using LLMs, which is also competitive to the SOTA fine-tuned models.
A BiRGAT Model for Multi-intent Spoken Language Understanding with Hierarchical Semantic Frames
Feb 28, 2024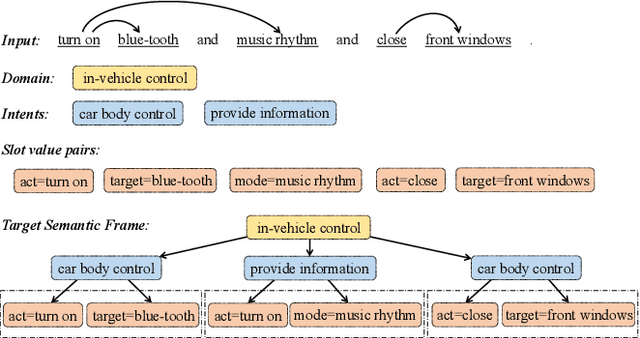
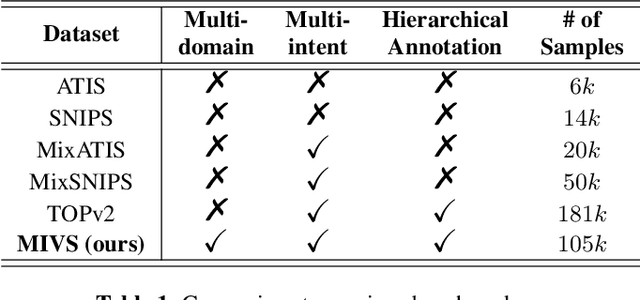
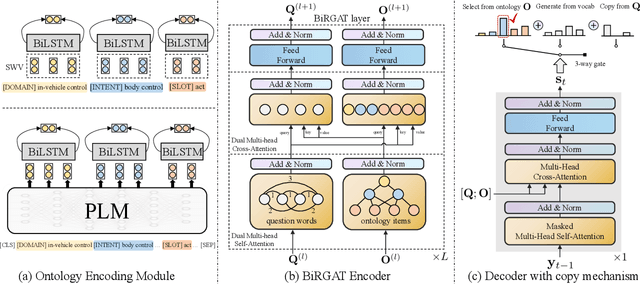
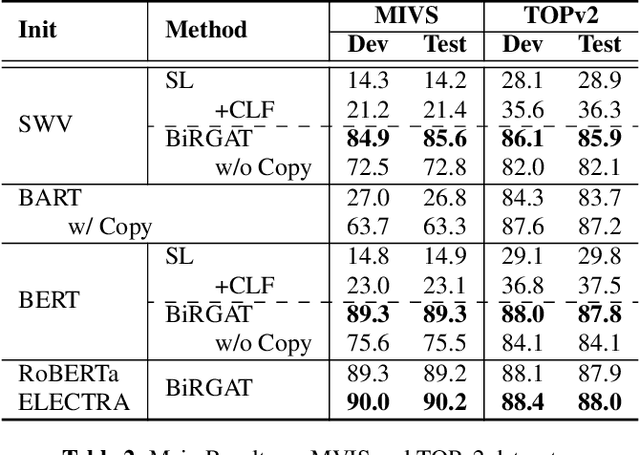
Previous work on spoken language understanding (SLU) mainly focuses on single-intent settings, where each input utterance merely contains one user intent. This configuration significantly limits the surface form of user utterances and the capacity of output semantics. In this work, we first propose a Multi-Intent dataset which is collected from a realistic in-Vehicle dialogue System, called MIVS. The target semantic frame is organized in a 3-layer hierarchical structure to tackle the alignment and assignment problems in multi-intent cases. Accordingly, we devise a BiRGAT model to encode the hierarchy of ontology items, the backbone of which is a dual relational graph attention network. Coupled with the 3-way pointer-generator decoder, our method outperforms traditional sequence labeling and classification-based schemes by a large margin.
ASTormer: An AST Structure-aware Transformer Decoder for Text-to-SQL
Oct 28, 2023Text-to-SQL aims to generate an executable SQL program given the user utterance and the corresponding database schema. To ensure the well-formedness of output SQLs, one prominent approach adopts a grammar-based recurrent decoder to produce the equivalent SQL abstract syntax tree (AST). However, previous methods mainly utilize an RNN-series decoder, which 1) is time-consuming and inefficient and 2) introduces very few structure priors. In this work, we propose an AST structure-aware Transformer decoder (ASTormer) to replace traditional RNN cells. The structural knowledge, such as node types and positions in the tree, is seamlessly incorporated into the decoder via both absolute and relative position embeddings. Besides, the proposed framework is compatible with different traversing orders even considering adaptive node selection. Extensive experiments on five text-to-SQL benchmarks demonstrate the effectiveness and efficiency of our structured decoder compared to competitive baselines.
ACT-SQL: In-Context Learning for Text-to-SQL with Automatically-Generated Chain-of-Thought
Oct 26, 2023Recently Large Language Models (LLMs) have been proven to have strong abilities in various domains and tasks. We study the problem of prompt designing in the text-to-SQL task and attempt to improve the LLMs' reasoning ability when generating SQL queries. Besides the trivial few-shot in-context learning setting, we design our chain-of-thought (CoT) prompt with a similar method to schema linking. We provide a method named ACT-SQL to automatically generate auto-CoT exemplars and thus the whole process doesn't need manual labeling. Our approach is cost-saving since we only use the LLMs' API call once when generating one SQL query. Furthermore, we extend our in-context learning method to the multi-turn text-to-SQL task. The experiment results show that the LLMs' performance can benefit from our ACT-SQL approach. Our approach achieves SOTA performance on the Spider dev set among existing in-context learning approaches.
CSS: A Large-scale Cross-schema Chinese Text-to-SQL Medical Dataset
May 25, 2023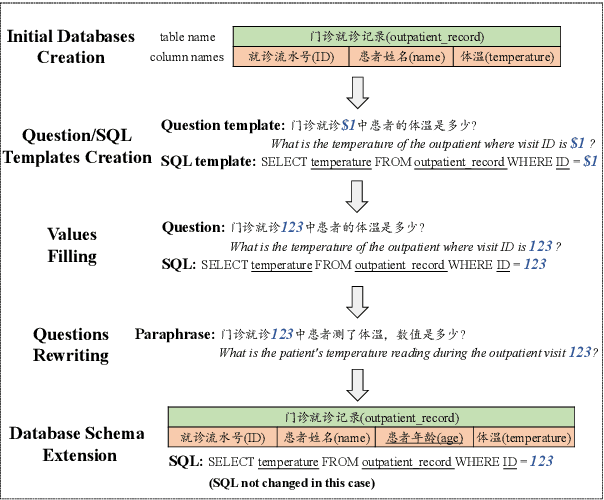
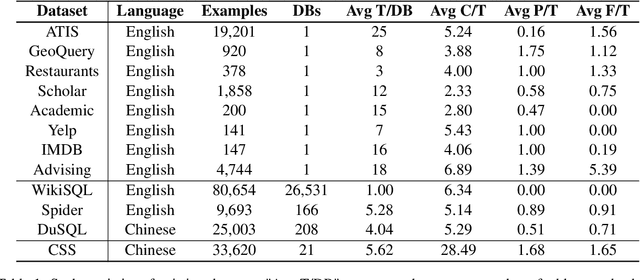
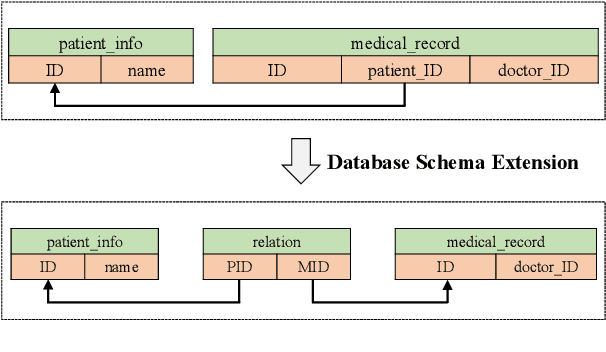
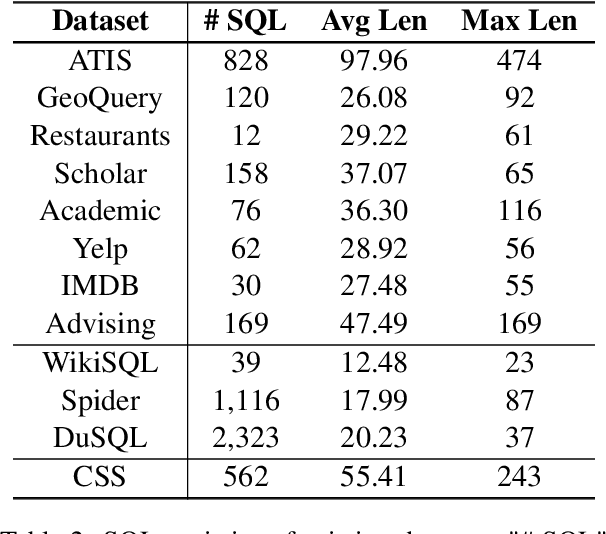
The cross-domain text-to-SQL task aims to build a system that can parse user questions into SQL on complete unseen databases, and the single-domain text-to-SQL task evaluates the performance on identical databases. Both of these setups confront unavoidable difficulties in real-world applications. To this end, we introduce the cross-schema text-to-SQL task, where the databases of evaluation data are different from that in the training data but come from the same domain. Furthermore, we present CSS, a large-scale CrosS-Schema Chinese text-to-SQL dataset, to carry on corresponding studies. CSS originally consisted of 4,340 question/SQL pairs across 2 databases. In order to generalize models to different medical systems, we extend CSS and create 19 new databases along with 29,280 corresponding dataset examples. Moreover, CSS is also a large corpus for single-domain Chinese text-to-SQL studies. We present the data collection approach and a series of analyses of the data statistics. To show the potential and usefulness of CSS, benchmarking baselines have been conducted and reported. Our dataset is publicly available at \url{https://huggingface.co/datasets/zhanghanchong/css}.
On the Structural Generalization in Text-to-SQL
Jan 21, 2023



Exploring the generalization of a text-to-SQL parser is essential for a system to automatically adapt the real-world databases. Previous works provided investigations focusing on lexical diversity, including the influence of the synonym and perturbations in both natural language questions and databases. However, research on the structure variety of database schema~(DS) is deficient. Specifically, confronted with the same input question, the target SQL is probably represented in different ways when the DS comes to a different structure. In this work, we provide in-deep discussions about the structural generalization of text-to-SQL tasks. We observe that current datasets are too templated to study structural generalization. To collect eligible test data, we propose a framework to generate novel text-to-SQL data via automatic and synchronous (DS, SQL) pair altering. In the experiments, significant performance reduction when evaluating well-trained text-to-SQL models on the synthetic samples demonstrates the limitation of current research regarding structural generalization. According to comprehensive analysis, we suggest the practical reason is the overfitting of (NL, SQL) patterns.