 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStoryTeller: Improving Long Video Description through Global Audio-Visual Character Identification
Paper and Code

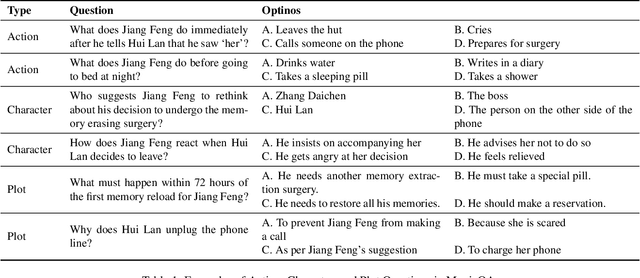

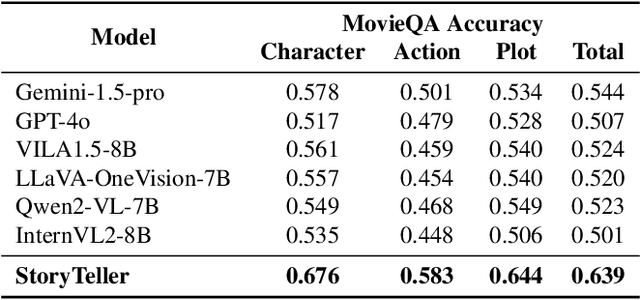
Existing large vision-language models (LVLMs) are largely limited to processing short, seconds-long videos and struggle with generating coherent descriptions for extended video spanning minutes or more. Long video description introduces new challenges, such as plot-level consistency across descriptions. To address these, we figure out audio-visual character identification, matching character names to each dialogue, as a key factor. We propose StoryTeller, a system for generating dense descriptions of long videos, incorporating both low-level visual concepts and high-level plot information. StoryTeller uses a multimodal large language model that integrates visual, audio, and text modalities to perform audio-visual character identification on minute-long video clips. The results are then fed into a LVLM to enhance consistency of video description. We validate our approach on movie description tasks and introduce MovieStory101, a dataset with dense descriptions for three-minute movie clips. To evaluate long video descriptions, we create MovieQA, a large set of multiple-choice questions for the MovieStory101 test set. We assess descriptions by inputting them into GPT-4 to answer these questions, using accuracy as an automatic evaluation metric. Experiments show that StoryTeller outperforms all open and closed-source baselines on MovieQA, achieving 9.5% higher accuracy than the strongest baseline, Gemini-1.5-pro, and demonstrating a +15.56% advantage in human side-by-side evaluations. Additionally, incorporating audio-visual character identification from StoryTeller improves the performance of all video description models, with Gemini-1.5-pro and GPT-4o showing relative improvement of 5.5% and 13.0%, respectively, in accuracy on MovieQA.