 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Focused Memorization for Multimodal Agents
May 29, 2026Long-term memory is essential for multimodal agents to build coherent experience, accumulate world knowledge, and achieve continual learning. However, constructing effective memory goes beyond memory module design and basic requirements such as accuracy and fidelity; the key challenge lies in determining what to memorize. Multimodal agents, such as embodied agents, continuously perceive, reason, and act in real or virtual environments, receiving an unbounded stream of multimodal observations. From this combinatorial explosion of information, an agent must selectively retain content that is relevant to its role in the environment and valuable for future tasks. To bridge this gap, we frame memory generation as a learnable memorization policy and introduce TaskMem (Task-focused Memorization Policy Learning), a reinforcement-learning-based framework that enables the policy to dynamically adjust its focus to the demands of real tasks encountered in the environment. TaskMem adopts a two-phase training paradigm: Phase One learns how to memorize by optimizing memory quality under fundamental fidelity requirements; Phase Two occurs after deployment, where the agent learns what to memorize by tuning an adapter on its base MLLM, using recent environment tasks to define a reward model that guides the memorization policy toward task-relevant content. To evaluate our approach, we reformulate VideoMME, EgoLife, and EgoTempo into streaming benchmarks that simulate a realistic setting in which an agent processes streaming observations and handles tasks arriving online. To isolate memory assessment, the questions must be answered using only the agent's memory, without access to raw video. Built on Qwen3-VL-30B-A3B, TaskMem improves VQA accuracy by 6.3%, 7.0%, and 5.3% on these benchmarks, respectively.
X-Foresight: A Joint Vision-Action Causal Forecasting Network via Predictive World Modeling
May 24, 2026Physical world knowledge resides mainly in videos. Equipping Vision-Language-Action (VLA) models with such knowledge is fundamental for safe and generalizable planning. Predictive world modeling enables VLA to internalize physical dynamics and long-term causality by predicting future video from past observations. However, naive next-frame prediction faces two challenges: 1) unlike semantically distinct text tokens, video tokens are low-entropy and redundant, causing prediction to degenerate into trivial extrapolation. 2) world modeling poses a temporal dilemma: dense prediction captures instantaneous dynamics, but cannot efficiently model long-horizon causality. To learn world knowledge effectively, we introduce X-Foresight, a predictive world model integrated directly into the VLA architecture to jointly learn world modeling and real-time action control. At its core lies a long-horizon chunk-wise auto-regressive strategy that addresses both challenges: by predicting semantically distant chunks rather than adjacent frames, it escapes trivial extrapolation, while preserving dense intra-chunk frames for instantaneous dynamics and sparse inter-chunk transitions for long-term causality. A curriculum learning schedule progressively extends prediction horizons and stabilizes long-horizon training. To capture long-term causality effectively, we present temporal importance sampling, which concentrates supervision on safety-critical chunks identified by ego-motion and behavioral signals. We further delegate photorealistic synthesis to a diffusion-based multi-view renderer, improving photorealistic appearance. Comprehensive experiments demonstrate that X-Foresight significantly outperforms VLA baselines in planning performance while maintaining strong generative fidelity, establishing a robust paradigm for world-knowledge-driven autonomous systems.
PatRe: A Full-Stage Office Action and Rebuttal Generation Benchmark for Patent Examination
May 05, 2026Patent examination is a complex, multi-stage process requiring both technical expertise and legal reasoning, increasingly challenged by rising application volumes. Prior benchmarks predominantly view patent examination as discriminative classification or static extraction, failing to capture its inherently interactive and iterative nature, similar to the peer review and rebuttal process in academic publishing. In this paper, we introduce PatRe, the first benchmark that models the full patent examination lifecycle, including Office Action generation and applicant rebuttal. PatRe comprises 480 real-world cases and supports both oracle and retrieval-simulated evaluation settings. Our benchmark reframes patent examination as a dynamic, multi-turn process of justification and response. Extensive experiments across various LLMs reveal critical insights into model performance, including differences between proprietary and open-source models, as well as task asymmetries between examiner analysis and applicant-side rebuttal. These findings highlight both the potential and current limitations of LLMs in modeling complex, real-world legal reasoning and technical novelty judgment in patent examination. We release our code and dataset to facilitate future research on patent examination modeling.
FlowPIE: Test-Time Scientific Idea Evolution with Flow-Guided Literature Exploration
Mar 31, 2026Scientific idea generation (SIG) is critical to AI-driven autonomous research, yet existing approaches are often constrained by a static retrieval-then-generation paradigm, leading to homogeneous and insufficiently divergent ideas. In this work, we propose FlowPIE, a tightly coupled retrieval-generation framework that treats literature exploration and idea generation as a co-evolving process. FlowPIE expands literature trajectories via a flow-guided Monte Carlo Tree Search (MCTS) inspired by GFlowNets, using the quality of current ideas assessed by an LLM-based generative reward model (GRM) as a supervised signal to guide adaptive retrieval and construct a diverse, high-quality initial population. Based on this population, FlowPIE models idea generation as a test-time idea evolution process, applying selection, crossover, and mutation with the isolation island paradigm and GRM-based fitness computation to incorporate cross-domain knowledge. It effectively mitigates the information cocoons arising from over-reliance on parametric knowledge and static literature. Extensive evaluations demonstrate that FlowPIE consistently produces ideas with higher novelty, feasibility and diversity compared to strong LLM-based and agent-based frameworks, while enabling reward scaling during test time.
Propagating Similarity, Mitigating Uncertainty: Similarity Propagation-enhanced Uncertainty for Multimodal Recommendation
Jan 27, 2026Multimodal Recommendation (MMR) systems are crucial for modern platforms but are often hampered by inherent noise and uncertainty in modal features, such as blurry images, diverse visual appearances, or ambiguous text. Existing methods often overlook this modality-specific uncertainty, leading to ineffective feature fusion. Furthermore, they fail to leverage rich similarity patterns among users and items to refine representations and their corresponding uncertainty estimates. To address these challenges, we propose a novel framework, Similarity Propagation-enhanced Uncertainty for Multimodal Recommendation (SPUMR). SPUMR explicitly models and mitigates uncertainty by first constructing the Modality Similarity Graph and the Collaborative Similarity Graph to refine representations from both content and behavioral perspectives. The Uncertainty-aware Preference Aggregation module then adaptively fuses the refined multimodal features, assigning greater weight to more reliable modalities. Extensive experiments on three benchmark datasets demonstrate that SPUMR achieves significant improvements over existing leading methods.
ProGiDiff: Prompt-Guided Diffusion-Based Medical Image Segmentation
Jan 22, 2026Widely adopted medical image segmentation methods, although efficient, are primarily deterministic and remain poorly amenable to natural language prompts. Thus, they lack the capability to estimate multiple proposals, human interaction, and cross-modality adaptation. Recently, text-to-image diffusion models have shown potential to bridge the gap. However, training them from scratch requires a large dataset-a limitation for medical image segmentation. Furthermore, they are often limited to binary segmentation and cannot be conditioned on a natural language prompt. To this end, we propose a novel framework called ProGiDiff that leverages existing image generation models for medical image segmentation purposes. Specifically, we propose a ControlNet-style conditioning mechanism with a custom encoder, suitable for image conditioning, to steer a pre-trained diffusion model to output segmentation masks. It naturally extends to a multi-class setting simply by prompting the target organ. Our experiment on organ segmentation from CT images demonstrates strong performance compared to previous methods and could greatly benefit from an expert-in-the-loop setting to leverage multiple proposals. Importantly, we demonstrate that the learned conditioning mechanism can be easily transferred through low-rank, few-shot adaptation to segment MR images.
Harnessing Uncertainty: Entropy-Modulated Policy Gradients for Long-Horizon LLM Agents
Sep 11, 2025In long-horizon tasks, recent agents based on Large Language Models (LLMs) face a significant challenge that sparse, outcome-based rewards make it difficult to assign credit to intermediate steps. Previous methods mainly focus on creating dense reward signals to guide learning, either through traditional reinforcement learning techniques like inverse reinforcement learning or by using Process Reward Models for step-by-step feedback. In this paper, we identify a fundamental problem in the learning dynamics of LLMs: the magnitude of policy gradients is inherently coupled with the entropy, which leads to inefficient small updates for confident correct actions and potentially destabilizes large updates for uncertain ones. To resolve this, we propose Entropy-Modulated Policy Gradients (EMPG), a framework that re-calibrates the learning signal based on step-wise uncertainty and the final task outcome. EMPG amplifies updates for confident correct actions, penalizes confident errors, and attenuates updates from uncertain steps to stabilize exploration. We further introduce a bonus term for future clarity that encourages agents to find more predictable solution paths. Through comprehensive experiments on three challenging agent tasks, WebShop, ALFWorld, and Deep Search, we demonstrate that EMPG achieves substantial performance gains and significantly outperforms strong policy gradient baselines. Project page is at https://empgseed-seed.github.io/
IPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
Apr 22, 2025

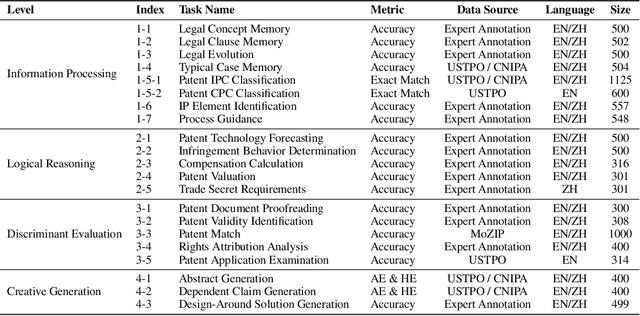
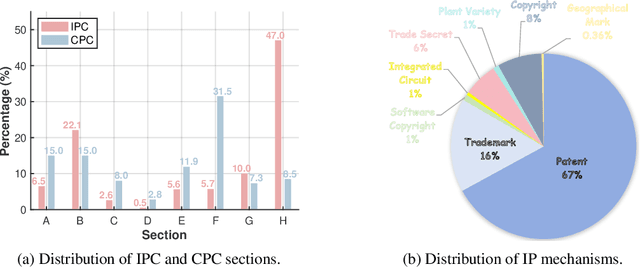
Intellectual Property (IP) is a unique domain that integrates technical and legal knowledge, making it inherently complex and knowledge-intensive. As large language models (LLMs) continue to advance, they show great potential for processing IP tasks, enabling more efficient analysis, understanding, and generation of IP-related content. However, existing datasets and benchmarks either focus narrowly on patents or cover limited aspects of the IP field, lacking alignment with real-world scenarios. To bridge this gap, we introduce the first comprehensive IP task taxonomy and a large, diverse bilingual benchmark, IPBench, covering 8 IP mechanisms and 20 tasks. This benchmark is designed to evaluate LLMs in real-world intellectual property applications, encompassing both understanding and generation. We benchmark 16 LLMs, ranging from general-purpose to domain-specific models, and find that even the best-performing model achieves only 75.8% accuracy, revealing substantial room for improvement. Notably, open-source IP and law-oriented models lag behind closed-source general-purpose models. We publicly release all data and code of IPBench and will continue to update it with additional IP-related tasks to better reflect real-world challenges in the intellectual property domain.
PaSa: An LLM Agent for Comprehensive Academic Paper Search
Jan 17, 2025



We introduce PaSa, an advanced Paper Search agent powered by large language models. PaSa can autonomously make a series of decisions, including invoking search tools, reading papers, and selecting relevant references, to ultimately obtain comprehensive and accurate results for complex scholarly queries. We optimize PaSa using reinforcement learning with a synthetic dataset, AutoScholarQuery, which includes 35k fine-grained academic queries and corresponding papers sourced from top-tier AI conference publications. Additionally, we develop RealScholarQuery, a benchmark collecting real-world academic queries to assess PaSa performance in more realistic scenarios. Despite being trained on synthetic data, PaSa significantly outperforms existing baselines on RealScholarQuery, including Google, Google Scholar, Google with GPT-4 for paraphrased queries, chatGPT (search-enabled GPT-4o), GPT-o1, and PaSa-GPT-4o (PaSa implemented by prompting GPT-4o). Notably, PaSa-7B surpasses the best Google-based baseline, Google with GPT-4o, by 37.78% in recall@20 and 39.90% in recall@50. It also exceeds PaSa-GPT-4o by 30.36% in recall and 4.25% in precision. Model, datasets, and code are available at https://github.com/bytedance/pasa.
Tarsier2: Advancing Large Vision-Language Models from Detailed Video Description to Comprehensive Video Understanding
Jan 14, 2025We introduce Tarsier2, a state-of-the-art large vision-language model (LVLM) designed for generating detailed and accurate video descriptions, while also exhibiting superior general video understanding capabilities. Tarsier2 achieves significant advancements through three key upgrades: (1) Scaling pre-training data from 11M to 40M video-text pairs, enriching both volume and diversity; (2) Performing fine-grained temporal alignment during supervised fine-tuning; (3) Using model-based sampling to automatically construct preference data and applying DPO training for optimization. Extensive experiments show that Tarsier2-7B consistently outperforms leading proprietary models, including GPT-4o and Gemini 1.5 Pro, in detailed video description tasks. On the DREAM-1K benchmark, Tarsier2-7B improves F1 by 2.8\% over GPT-4o and 5.8\% over Gemini-1.5-Pro. In human side-by-side evaluations, Tarsier2-7B shows a +8.6\% performance advantage over GPT-4o and +24.9\% over Gemini-1.5-Pro. Tarsier2-7B also sets new state-of-the-art results across 15 public benchmarks, spanning tasks such as video question-answering, video grounding, hallucination test, and embodied question-answering, demonstrating its versatility as a robust generalist vision-language model.