 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Focused Memorization for Multimodal Agents
May 29, 2026Long-term memory is essential for multimodal agents to build coherent experience, accumulate world knowledge, and achieve continual learning. However, constructing effective memory goes beyond memory module design and basic requirements such as accuracy and fidelity; the key challenge lies in determining what to memorize. Multimodal agents, such as embodied agents, continuously perceive, reason, and act in real or virtual environments, receiving an unbounded stream of multimodal observations. From this combinatorial explosion of information, an agent must selectively retain content that is relevant to its role in the environment and valuable for future tasks. To bridge this gap, we frame memory generation as a learnable memorization policy and introduce TaskMem (Task-focused Memorization Policy Learning), a reinforcement-learning-based framework that enables the policy to dynamically adjust its focus to the demands of real tasks encountered in the environment. TaskMem adopts a two-phase training paradigm: Phase One learns how to memorize by optimizing memory quality under fundamental fidelity requirements; Phase Two occurs after deployment, where the agent learns what to memorize by tuning an adapter on its base MLLM, using recent environment tasks to define a reward model that guides the memorization policy toward task-relevant content. To evaluate our approach, we reformulate VideoMME, EgoLife, and EgoTempo into streaming benchmarks that simulate a realistic setting in which an agent processes streaming observations and handles tasks arriving online. To isolate memory assessment, the questions must be answered using only the agent's memory, without access to raw video. Built on Qwen3-VL-30B-A3B, TaskMem improves VQA accuracy by 6.3%, 7.0%, and 5.3% on these benchmarks, respectively.
PaSa: An LLM Agent for Comprehensive Academic Paper Search
Jan 17, 2025



We introduce PaSa, an advanced Paper Search agent powered by large language models. PaSa can autonomously make a series of decisions, including invoking search tools, reading papers, and selecting relevant references, to ultimately obtain comprehensive and accurate results for complex scholarly queries. We optimize PaSa using reinforcement learning with a synthetic dataset, AutoScholarQuery, which includes 35k fine-grained academic queries and corresponding papers sourced from top-tier AI conference publications. Additionally, we develop RealScholarQuery, a benchmark collecting real-world academic queries to assess PaSa performance in more realistic scenarios. Despite being trained on synthetic data, PaSa significantly outperforms existing baselines on RealScholarQuery, including Google, Google Scholar, Google with GPT-4 for paraphrased queries, chatGPT (search-enabled GPT-4o), GPT-o1, and PaSa-GPT-4o (PaSa implemented by prompting GPT-4o). Notably, PaSa-7B surpasses the best Google-based baseline, Google with GPT-4o, by 37.78% in recall@20 and 39.90% in recall@50. It also exceeds PaSa-GPT-4o by 30.36% in recall and 4.25% in precision. Model, datasets, and code are available at https://github.com/bytedance/pasa.
StoryTeller: Improving Long Video Description through Global Audio-Visual Character Identification
Nov 11, 2024

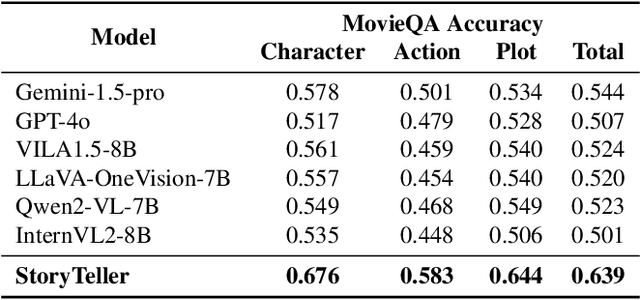
Existing large vision-language models (LVLMs) are largely limited to processing short, seconds-long videos and struggle with generating coherent descriptions for extended video spanning minutes or more. Long video description introduces new challenges, such as plot-level consistency across descriptions. To address these, we figure out audio-visual character identification, matching character names to each dialogue, as a key factor. We propose StoryTeller, a system for generating dense descriptions of long videos, incorporating both low-level visual concepts and high-level plot information. StoryTeller uses a multimodal large language model that integrates visual, audio, and text modalities to perform audio-visual character identification on minute-long video clips. The results are then fed into a LVLM to enhance consistency of video description. We validate our approach on movie description tasks and introduce MovieStory101, a dataset with dense descriptions for three-minute movie clips. To evaluate long video descriptions, we create MovieQA, a large set of multiple-choice questions for the MovieStory101 test set. We assess descriptions by inputting them into GPT-4 to answer these questions, using accuracy as an automatic evaluation metric. Experiments show that StoryTeller outperforms all open and closed-source baselines on MovieQA, achieving 9.5% higher accuracy than the strongest baseline, Gemini-1.5-pro, and demonstrating a +15.56% advantage in human side-by-side evaluations. Additionally, incorporating audio-visual character identification from StoryTeller improves the performance of all video description models, with Gemini-1.5-pro and GPT-4o showing relative improvement of 5.5% and 13.0%, respectively, in accuracy on MovieQA.
AGILE: A Novel Framework of LLM Agents
May 23, 2024



We introduce a novel framework of LLM agents named AGILE (AGent that Interacts and Learns from Environments) designed to perform complex conversational tasks with users, leveraging LLMs, memory, tools, and interactions with experts. The agent's abilities include not only conversation but also reflection, utilization of tools, and consultation with experts. We formulate the construction of such an LLM agent as a reinforcement learning problem, in which the LLM serves as the policy model. We fine-tune the LLM using labeled data of actions and the PPO algorithm. We focus on question answering and release a dataset for agents called ProductQA, comprising challenging questions in online shopping. Our extensive experiments on ProductQA and MedMCQA show that AGILE agents based on 13B and 7B LLMs trained with PPO can outperform GPT-4 agents. Our ablation study highlights the indispensability of memory, tools, consultation, reflection, and reinforcement learning in achieving the agent's strong performance.