 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStoryTeller: Improving Long Video Description through Global Audio-Visual Character Identification
Nov 11, 2024

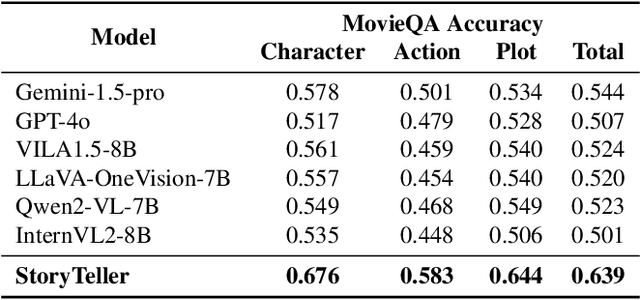
Existing large vision-language models (LVLMs) are largely limited to processing short, seconds-long videos and struggle with generating coherent descriptions for extended video spanning minutes or more. Long video description introduces new challenges, such as plot-level consistency across descriptions. To address these, we figure out audio-visual character identification, matching character names to each dialogue, as a key factor. We propose StoryTeller, a system for generating dense descriptions of long videos, incorporating both low-level visual concepts and high-level plot information. StoryTeller uses a multimodal large language model that integrates visual, audio, and text modalities to perform audio-visual character identification on minute-long video clips. The results are then fed into a LVLM to enhance consistency of video description. We validate our approach on movie description tasks and introduce MovieStory101, a dataset with dense descriptions for three-minute movie clips. To evaluate long video descriptions, we create MovieQA, a large set of multiple-choice questions for the MovieStory101 test set. We assess descriptions by inputting them into GPT-4 to answer these questions, using accuracy as an automatic evaluation metric. Experiments show that StoryTeller outperforms all open and closed-source baselines on MovieQA, achieving 9.5% higher accuracy than the strongest baseline, Gemini-1.5-pro, and demonstrating a +15.56% advantage in human side-by-side evaluations. Additionally, incorporating audio-visual character identification from StoryTeller improves the performance of all video description models, with Gemini-1.5-pro and GPT-4o showing relative improvement of 5.5% and 13.0%, respectively, in accuracy on MovieQA.
Context-Aware RCNN: A Baseline for Action Detection in Videos
Jul 20, 2020
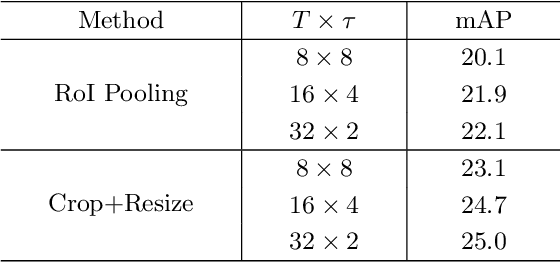
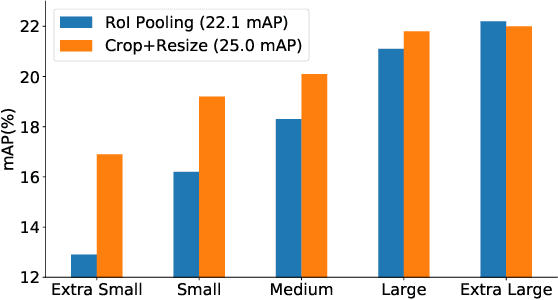

Video action detection approaches usually conduct actor-centric action recognition over RoI-pooled features following the standard pipeline of Faster-RCNN. In this work, we first empirically find the recognition accuracy is highly correlated with the bounding box size of an actor, and thus higher resolution of actors contributes to better performance. However, video models require dense sampling in time to achieve accurate recognition. To fit in GPU memory, the frames to backbone network must be kept low-resolution, resulting in a coarse feature map in RoI-Pooling layer. Thus, we revisit RCNN for actor-centric action recognition via cropping and resizing image patches around actors before feature extraction with I3D deep network. Moreover, we found that expanding actor bounding boxes slightly and fusing the context features can further boost the performance. Consequently, we develop a surpringly effective baseline (Context-Aware RCNN) and it achieves new state-of-the-art results on two challenging action detection benchmarks of AVA and JHMDB. Our observations challenge the conventional wisdom of RoI-Pooling based pipeline and encourage researchers rethink the importance of resolution in actor-centric action recognition. Our approach can serve as a strong baseline for video action detection and is expected to inspire new ideas for this filed. The code is available at \url{https://github.com/MCG-NJU/CRCNN-Action}.
Learning Actor Relation Graphs for Group Activity Recognition
Apr 23, 2019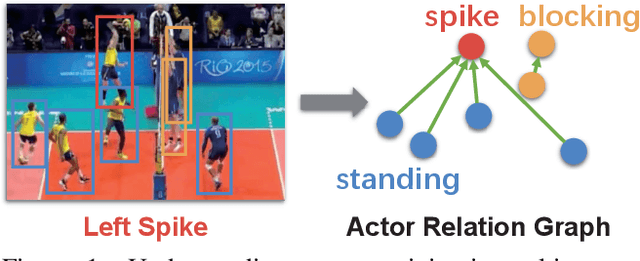

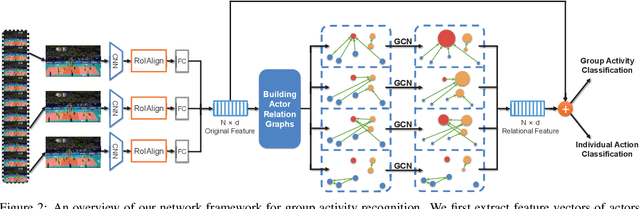
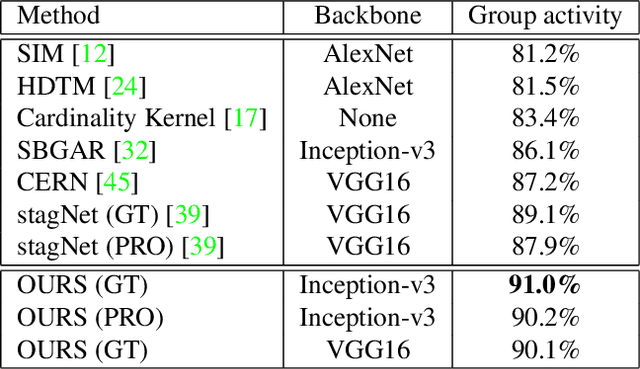
Modeling relation between actors is important for recognizing group activity in a multi-person scene. This paper aims at learning discriminative relation between actors efficiently using deep models. To this end, we propose to build a flexible and efficient Actor Relation Graph (ARG) to simultaneously capture the appearance and position relation between actors. Thanks to the Graph Convolutional Network, the connections in ARG could be automatically learned from group activity videos in an end-to-end manner, and the inference on ARG could be efficiently performed with standard matrix operations. Furthermore, in practice, we come up with two variants to sparsify ARG for more effective modeling in videos: spatially localized ARG and temporal randomized ARG. We perform extensive experiments on two standard group activity recognition datasets: the Volleyball dataset and the Collective Activity dataset, where state-of-the-art performance is achieved on both datasets. We also visualize the learned actor graphs and relation features, which demonstrate that the proposed ARG is able to capture the discriminative relation information for group activity recognition.