 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware RCNN: A Baseline for Action Detection in Videos
Paper and Code

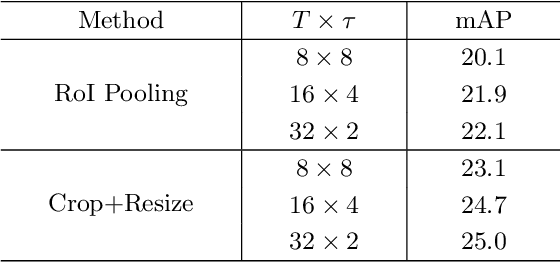
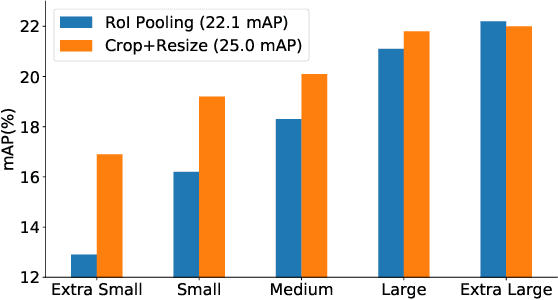

Video action detection approaches usually conduct actor-centric action recognition over RoI-pooled features following the standard pipeline of Faster-RCNN. In this work, we first empirically find the recognition accuracy is highly correlated with the bounding box size of an actor, and thus higher resolution of actors contributes to better performance. However, video models require dense sampling in time to achieve accurate recognition. To fit in GPU memory, the frames to backbone network must be kept low-resolution, resulting in a coarse feature map in RoI-Pooling layer. Thus, we revisit RCNN for actor-centric action recognition via cropping and resizing image patches around actors before feature extraction with I3D deep network. Moreover, we found that expanding actor bounding boxes slightly and fusing the context features can further boost the performance. Consequently, we develop a surpringly effective baseline (Context-Aware RCNN) and it achieves new state-of-the-art results on two challenging action detection benchmarks of AVA and JHMDB. Our observations challenge the conventional wisdom of RoI-Pooling based pipeline and encourage researchers rethink the importance of resolution in actor-centric action recognition. Our approach can serve as a strong baseline for video action detection and is expected to inspire new ideas for this filed. The code is available at \url{https://github.com/MCG-NJU/CRCNN-Action}.