 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatRe: A Full-Stage Office Action and Rebuttal Generation Benchmark for Patent Examination
May 05, 2026Patent examination is a complex, multi-stage process requiring both technical expertise and legal reasoning, increasingly challenged by rising application volumes. Prior benchmarks predominantly view patent examination as discriminative classification or static extraction, failing to capture its inherently interactive and iterative nature, similar to the peer review and rebuttal process in academic publishing. In this paper, we introduce PatRe, the first benchmark that models the full patent examination lifecycle, including Office Action generation and applicant rebuttal. PatRe comprises 480 real-world cases and supports both oracle and retrieval-simulated evaluation settings. Our benchmark reframes patent examination as a dynamic, multi-turn process of justification and response. Extensive experiments across various LLMs reveal critical insights into model performance, including differences between proprietary and open-source models, as well as task asymmetries between examiner analysis and applicant-side rebuttal. These findings highlight both the potential and current limitations of LLMs in modeling complex, real-world legal reasoning and technical novelty judgment in patent examination. We release our code and dataset to facilitate future research on patent examination modeling.
FlowPIE: Test-Time Scientific Idea Evolution with Flow-Guided Literature Exploration
Mar 31, 2026Scientific idea generation (SIG) is critical to AI-driven autonomous research, yet existing approaches are often constrained by a static retrieval-then-generation paradigm, leading to homogeneous and insufficiently divergent ideas. In this work, we propose FlowPIE, a tightly coupled retrieval-generation framework that treats literature exploration and idea generation as a co-evolving process. FlowPIE expands literature trajectories via a flow-guided Monte Carlo Tree Search (MCTS) inspired by GFlowNets, using the quality of current ideas assessed by an LLM-based generative reward model (GRM) as a supervised signal to guide adaptive retrieval and construct a diverse, high-quality initial population. Based on this population, FlowPIE models idea generation as a test-time idea evolution process, applying selection, crossover, and mutation with the isolation island paradigm and GRM-based fitness computation to incorporate cross-domain knowledge. It effectively mitigates the information cocoons arising from over-reliance on parametric knowledge and static literature. Extensive evaluations demonstrate that FlowPIE consistently produces ideas with higher novelty, feasibility and diversity compared to strong LLM-based and agent-based frameworks, while enabling reward scaling during test time.
Recurrent Preference Memory for Efficient Long-Sequence Generative Recommendation
Feb 13, 2026Generative recommendation (GenRec) models typically model user behavior via full attention, but scaling to lifelong sequences is hindered by prohibitive computational costs and noise accumulation from stochastic interactions. To address these challenges, we introduce Rec2PM, a framework that compresses long user interaction histories into compact Preference Memory tokens. Unlike traditional recurrent methods that suffer from serial training, Rec2PM employs a novel self-referential teacher-forcing strategy: it leverages a global view of the history to generate reference memories, which serve as supervision targets for parallelized recurrent updates. This allows for fully parallel training while maintaining the capability for iterative updates during inference. Additionally, by representing memory as token embeddings rather than extensive KV caches, Rec2PM achieves extreme storage efficiency. Experiments on large-scale benchmarks show that Rec2PM significantly reduces inference latency and memory footprint while achieving superior accuracy compared to full-sequence models. Analysis reveals that the Preference Memory functions as a denoising Information Bottleneck, effectively filtering interaction noise to capture robust long-term interests.
Learning Ordinal Probabilistic Reward from Preferences
Feb 13, 2026Reward models are crucial for aligning large language models (LLMs) with human values and intentions. Existing approaches follow either Generative (GRMs) or Discriminative (DRMs) paradigms, yet both suffer from limitations: GRMs typically demand costly point-wise supervision, while DRMs produce uncalibrated relative scores that lack probabilistic interpretation. To address these challenges, we introduce a novel reward modeling paradigm: Probabilistic Reward Model (PRM). Instead of modeling reward as a deterministic scalar, our approach treats it as a random variable, learning a full probability distribution for the quality of each response. To make this paradigm practical, we present its closed-form, discrete realization: the Ordinal Probabilistic Reward Model (OPRM), which discretizes the quality score into a finite set of ordinal ratings. Building on OPRM, we propose a data-efficient training strategy called Region Flooding Tuning (RgFT). It enables rewards to better reflect absolute text quality by incorporating quality-level annotations, which guide the model to concentrate the probability mass within corresponding rating sub-regions. Experiments on various reward model benchmarks show that our method improves accuracy by $\textbf{2.9%}\sim\textbf{7.4%}$ compared to prior reward models, demonstrating strong performance and data efficiency. Analysis of the score distribution provides evidence that our method captures not only relative rankings but also absolute quality.
Beyond Quantity: Trajectory Diversity Scaling for Code Agents
Feb 03, 2026As code large language models (LLMs) evolve into tool-interactive agents via the Model Context Protocol (MCP), their generalization is increasingly limited by low-quality synthetic data and the diminishing returns of quantity scaling. Moreover, quantity-centric scaling exhibits an early bottleneck that underutilizes trajectory data. We propose TDScaling, a Trajectory Diversity Scaling-based data synthesis framework for code agents that scales performance through diversity rather than raw volume. Under a fixed training budget, increasing trajectory diversity yields larger gains than adding more trajectories, improving the performance-cost trade-off for agent training. TDScaling integrates four innovations: (1) a Business Cluster mechanism that captures real-service logical dependencies; (2) a blueprint-driven multi-agent paradigm that enforces trajectory coherence; (3) an adaptive evolution mechanism that steers synthesis toward long-tail scenarios using Domain Entropy, Reasoning Mode Entropy, and Cumulative Action Complexity to prevent mode collapse; and (4) a sandboxed code tool that mitigates catastrophic forgetting of intrinsic coding capabilities. Experiments on general tool-use benchmarks (BFCL, tau^2-Bench) and code agent tasks (RebenchT, CodeCI, BIRD) demonstrate a win-win outcome: TDScaling improves both tool-use generalization and inherent coding proficiency. We plan to release the full codebase and the synthesized dataset (including 30,000+ tool clusters) upon publication.
EquiMus: Energy-Equivalent Dynamic Modeling and Simulation of Musculoskeletal Robots Driven by Linear Elastic Actuators
Nov 11, 2025Dynamic modeling and control are critical for unleashing soft robots' potential, yet remain challenging due to their complex constitutive behaviors and real-world operating conditions. Bio-inspired musculoskeletal robots, which integrate rigid skeletons with soft actuators, combine high load-bearing capacity with inherent flexibility. Although actuation dynamics have been studied through experimental methods and surrogate models, accurate and effective modeling and simulation remain a significant challenge, especially for large-scale hybrid rigid--soft robots with continuously distributed mass, kinematic loops, and diverse motion modes. To address these challenges, we propose EquiMus, an energy-equivalent dynamic modeling framework and MuJoCo-based simulation for musculoskeletal rigid--soft hybrid robots with linear elastic actuators. The equivalence and effectiveness of the proposed approach are validated and examined through both simulations and real-world experiments on a bionic robotic leg. EquiMus further demonstrates its utility for downstream tasks, including controller design and learning-based control strategies.
IPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
Apr 22, 2025

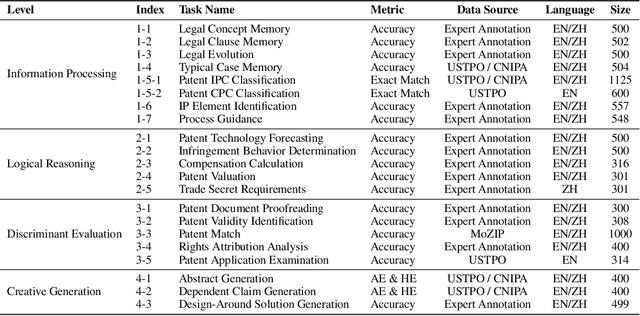
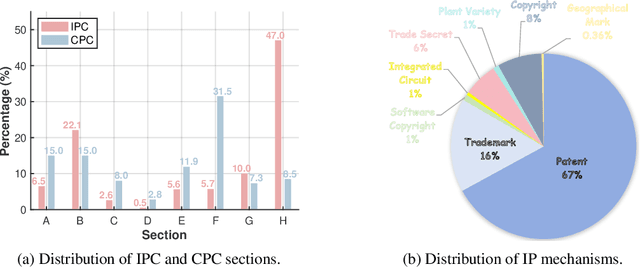
Intellectual Property (IP) is a unique domain that integrates technical and legal knowledge, making it inherently complex and knowledge-intensive. As large language models (LLMs) continue to advance, they show great potential for processing IP tasks, enabling more efficient analysis, understanding, and generation of IP-related content. However, existing datasets and benchmarks either focus narrowly on patents or cover limited aspects of the IP field, lacking alignment with real-world scenarios. To bridge this gap, we introduce the first comprehensive IP task taxonomy and a large, diverse bilingual benchmark, IPBench, covering 8 IP mechanisms and 20 tasks. This benchmark is designed to evaluate LLMs in real-world intellectual property applications, encompassing both understanding and generation. We benchmark 16 LLMs, ranging from general-purpose to domain-specific models, and find that even the best-performing model achieves only 75.8% accuracy, revealing substantial room for improvement. Notably, open-source IP and law-oriented models lag behind closed-source general-purpose models. We publicly release all data and code of IPBench and will continue to update it with additional IP-related tasks to better reflect real-world challenges in the intellectual property domain.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
AutoPatent: A Multi-Agent Framework for Automatic Patent Generation
Dec 13, 2024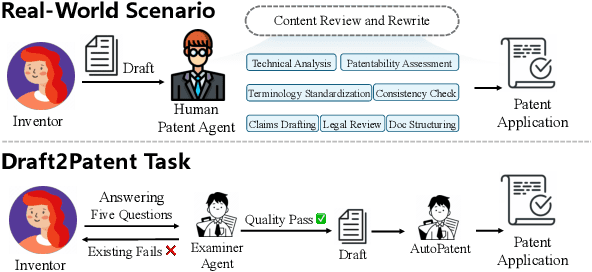
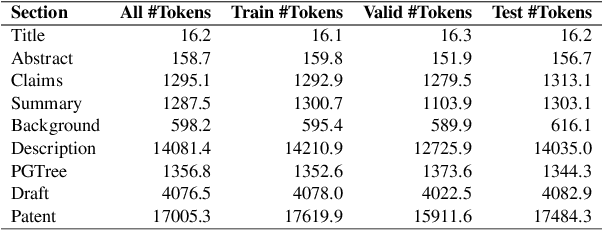
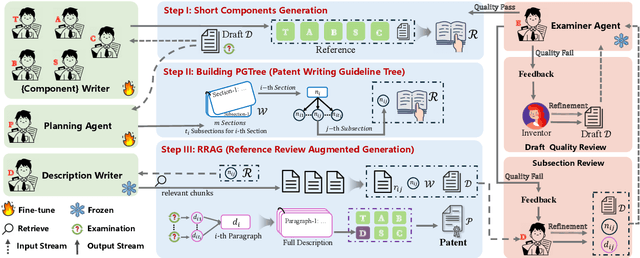
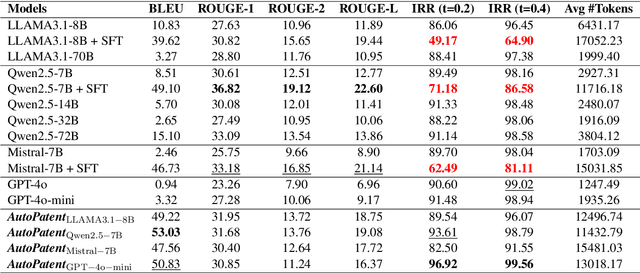
As the capabilities of Large Language Models (LLMs) continue to advance, the field of patent processing has garnered increased attention within the natural language processing community. However, the majority of research has been concentrated on classification tasks, such as patent categorization and examination, or on short text generation tasks like patent summarization and patent quizzes. In this paper, we introduce a novel and practical task known as Draft2Patent, along with its corresponding D2P benchmark, which challenges LLMs to generate full-length patents averaging 17K tokens based on initial drafts. Patents present a significant challenge to LLMs due to their specialized nature, standardized terminology, and extensive length. We propose a multi-agent framework called AutoPatent which leverages the LLM-based planner agent, writer agents, and examiner agent with PGTree and RRAG to generate lengthy, intricate, and high-quality complete patent documents. The experimental results demonstrate that our AutoPatent framework significantly enhances the ability to generate comprehensive patents across various LLMs. Furthermore, we have discovered that patents generated solely with the AutoPatent framework based on the Qwen2.5-7B model outperform those produced by larger and more powerful LLMs, such as GPT-4o, Qwen2.5-72B, and LLAMA3.1-70B, in both objective metrics and human evaluations. We will make the data and code available upon acceptance at \url{https://github.com/QiYao-Wang/AutoPatent}.
IPEval: A Bilingual Intellectual Property Agency Consultation Evaluation Benchmark for Large Language Models
Jun 18, 2024
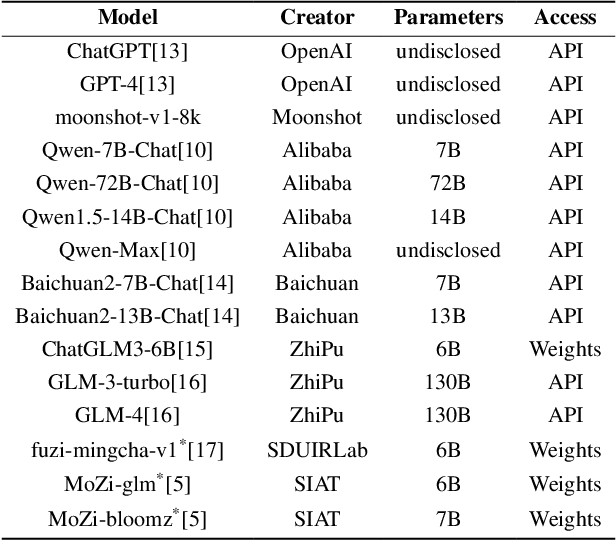
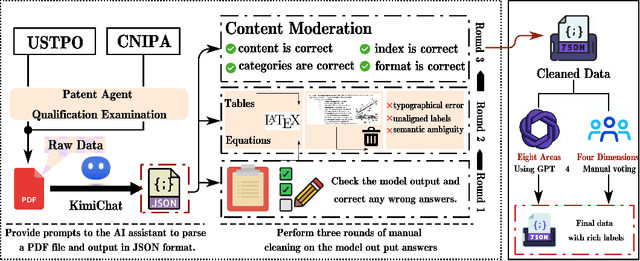
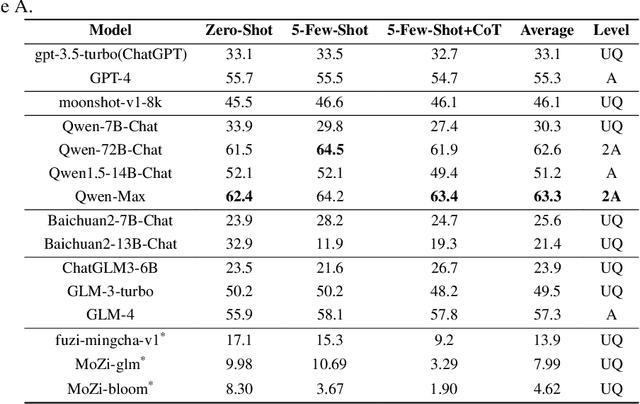
The rapid development of Large Language Models (LLMs) in vertical domains, including intellectual property (IP), lacks a specific evaluation benchmark for assessing their understanding, application, and reasoning abilities. To fill this gap, we introduce IPEval, the first evaluation benchmark tailored for IP agency and consulting tasks. IPEval comprises 2657 multiple-choice questions across four major dimensions: creation, application, protection, and management of IP. These questions span patent rights (inventions, utility models, designs), trademarks, copyrights, trade secrets, and other related laws. Evaluation methods include zero-shot, 5-few-shot, and Chain of Thought (CoT) for seven LLM types, predominantly in English or Chinese. Results show superior English performance by models like GPT series and Qwen series, while Chinese-centric LLMs excel in Chinese tests, albeit specialized IP LLMs lag behind general-purpose ones. Regional and temporal aspects of IP underscore the need for LLMs to grasp legal nuances and evolving laws. IPEval aims to accurately gauge LLM capabilities in IP and spur development of specialized models. Website: \url{https://ipeval.github.io/}