 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn ensemble of convolution-based methods for fault detection using vibration signals
May 05, 2023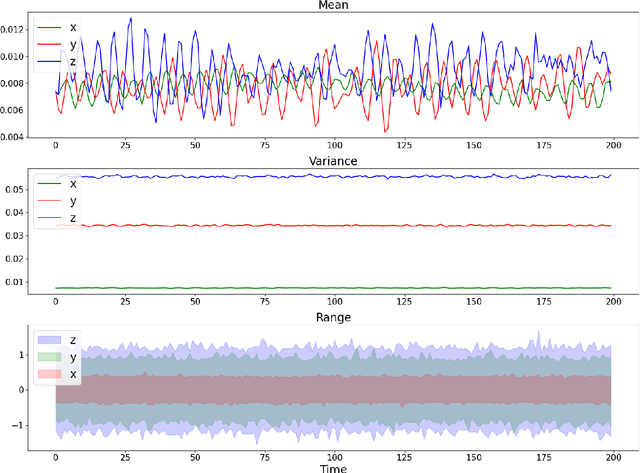
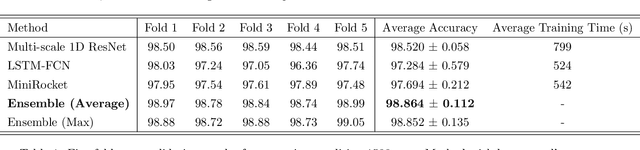
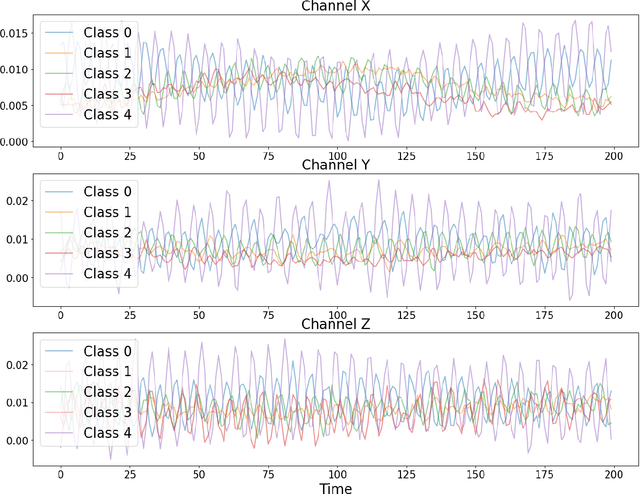
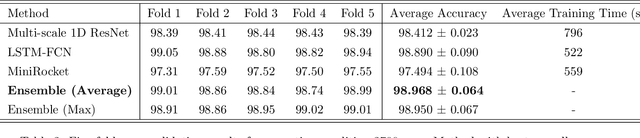
This paper focuses on solving a fault detection problem using multivariate time series of vibration signals collected from planetary gearboxes in a test rig. Various traditional machine learning and deep learning methods have been proposed for multivariate time-series classification, including distance-based, functional data-oriented, feature-driven, and convolution kernel-based methods. Recent studies have shown using convolution kernel-based methods like ROCKET, and 1D convolutional neural networks with ResNet and FCN, have robust performance for multivariate time-series data classification. We propose an ensemble of three convolution kernel-based methods and show its efficacy on this fault detection problem by outperforming other approaches and achieving an accuracy of more than 98.8\%.
CDA: Contrastive-adversarial Domain Adaptation
Jan 10, 2023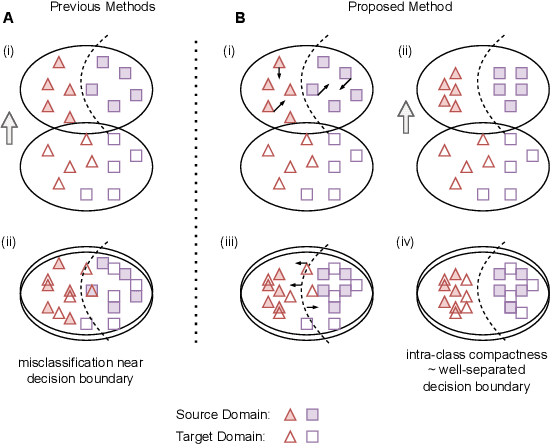
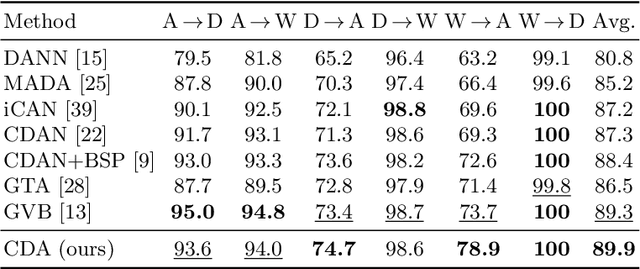
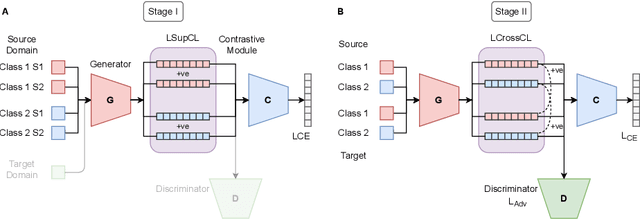
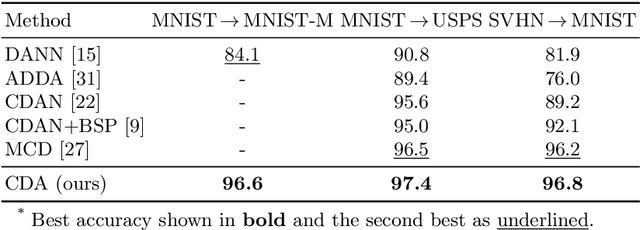
Recent advances in domain adaptation reveal that adversarial learning on deep neural networks can learn domain invariant features to reduce the shift between source and target domains. While such adversarial approaches achieve domain-level alignment, they ignore the class (label) shift. When class-conditional data distributions are significantly different between the source and target domain, it can generate ambiguous features near class boundaries that are more likely to be misclassified. In this work, we propose a two-stage model for domain adaptation called \textbf{C}ontrastive-adversarial \textbf{D}omain \textbf{A}daptation \textbf{(CDA)}. While the adversarial component facilitates domain-level alignment, two-stage contrastive learning exploits class information to achieve higher intra-class compactness across domains resulting in well-separated decision boundaries. Furthermore, the proposed contrastive framework is designed as a plug-and-play module that can be easily embedded with existing adversarial methods for domain adaptation. We conduct experiments on two widely used benchmark datasets for domain adaptation, namely, \textit{Office-31} and \textit{Digits-5}, and demonstrate that CDA achieves state-of-the-art results on both datasets.
An Offline Deep Reinforcement Learning for Maintenance Decision-Making
Sep 28, 2021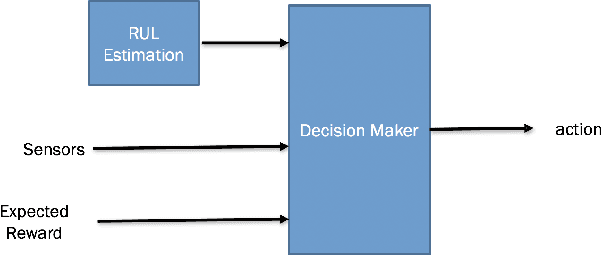
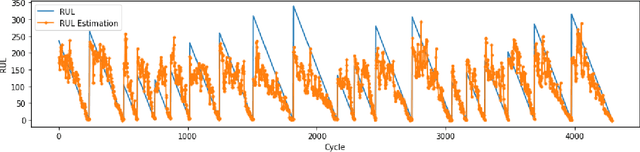
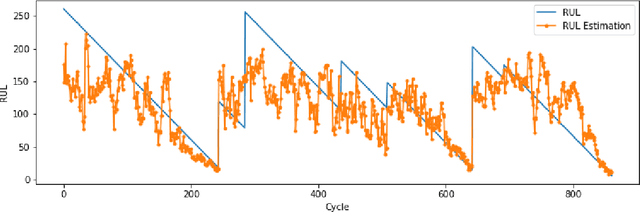
Several machine learning and deep learning frameworks have been proposed to solve remaining useful life estimation and failure prediction problems in recent years. Having access to the remaining useful life estimation or likelihood of failure in near future helps operators to assess the operating conditions and, therefore, provides better opportunities for sound repair and maintenance decisions. However, many operators believe remaining useful life estimation and failure prediction solutions are incomplete answers to the maintenance challenge. They argue that knowing the likelihood of failure in the future is not enough to make maintenance decisions that minimize costs and keep the operators safe. In this paper, we present a maintenance framework based on offline supervised deep reinforcement learning that instead of providing information such as likelihood of failure, suggests actions such as "continuation of the operation" or "the visitation of the repair shop" to the operators in order to maximize the overall profit. Using offline reinforcement learning makes it possible to learn the optimum maintenance policy from historical data without relying on expensive simulators. We demonstrate the application of our solution in a case study using the NASA C-MAPSS dataset.
Deep Time Series Models for Scarce Data
Mar 16, 2021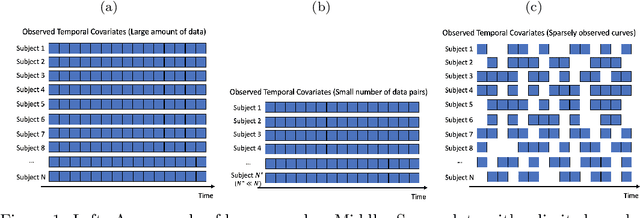
Time series data have grown at an explosive rate in numerous domains and have stimulated a surge of time series modeling research. A comprehensive comparison of different time series models, for a considered data analytics task, provides useful guidance on model selection for data analytics practitioners. Data scarcity is a universal issue that occurs in a vast range of data analytics problems, due to the high costs associated with collecting, generating, and labeling data as well as some data quality issues such as missing data. In this paper, we focus on the temporal classification/regression problem that attempts to build a mathematical mapping from multivariate time series inputs to a discrete class label or a real-valued response variable. For this specific problem, we identify two types of scarce data: scarce data with small samples and scarce data with sparsely and irregularly observed time series covariates. Observing that all existing works are incapable of utilizing the sparse time series inputs for proper modeling building, we propose a model called sparse functional multilayer perceptron (SFMLP) for handling the sparsity in the time series covariates. The effectiveness of the proposed SFMLP under each of the two types of data scarcity, in comparison with the conventional deep sequential learning models (e.g., Recurrent Neural Network, and Long Short-Term Memory), is investigated through mathematical arguments and numerical experiments.
Wisdom of the Ensemble: Improving Consistency of Deep Learning Models
Nov 13, 2020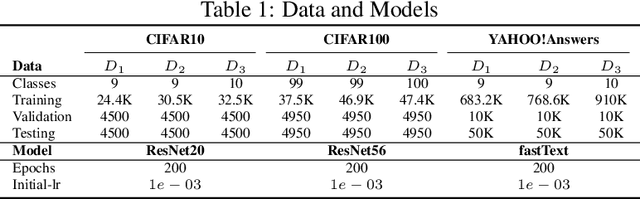

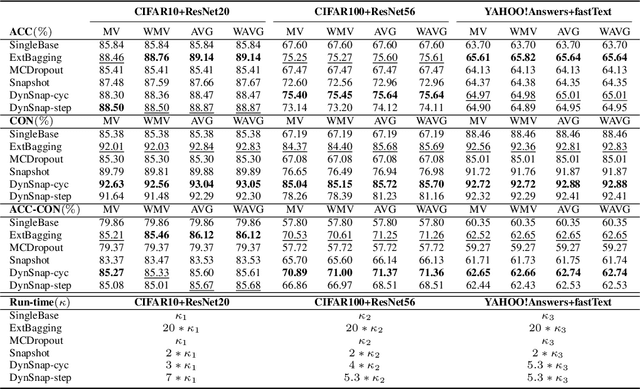
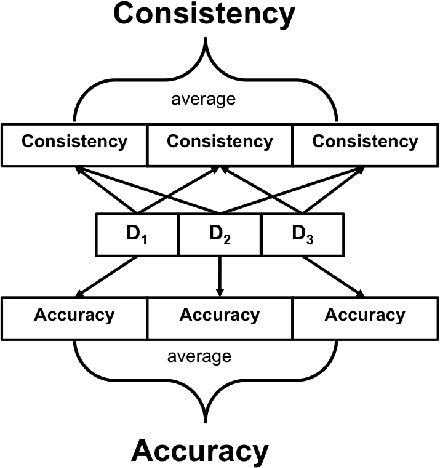
Deep learning classifiers are assisting humans in making decisions and hence the user's trust in these models is of paramount importance. Trust is often a function of constant behavior. From an AI model perspective it means given the same input the user would expect the same output, especially for correct outputs, or in other words consistently correct outputs. This paper studies a model behavior in the context of periodic retraining of deployed models where the outputs from successive generations of the models might not agree on the correct labels assigned to the same input. We formally define consistency and correct-consistency of a learning model. We prove that consistency and correct-consistency of an ensemble learner is not less than the average consistency and correct-consistency of individual learners and correct-consistency can be improved with a probability by combining learners with accuracy not less than the average accuracy of ensemble component learners. To validate the theory using three datasets and two state-of-the-art deep learning classifiers we also propose an efficient dynamic snapshot ensemble method and demonstrate its value.
Health Indicator Forecasting for Improving Remaining Useful Life Estimation
Jun 05, 2020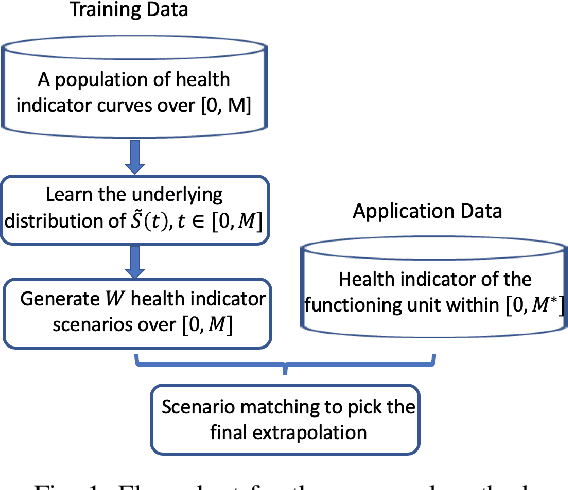
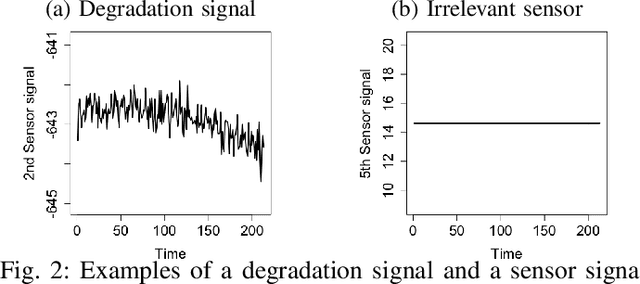
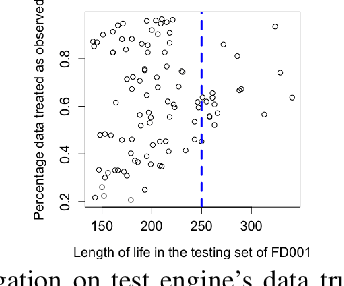
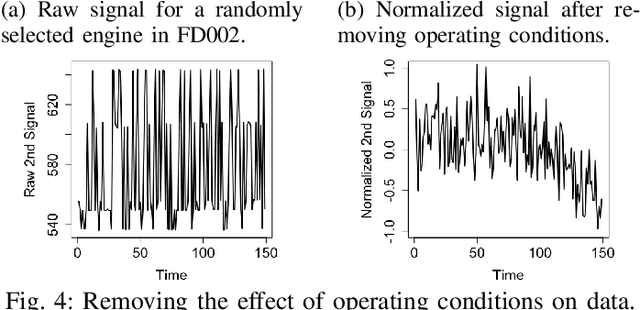
Prognostics is concerned with predicting the future health of the equipment and any potential failures. With the advances in the Internet of Things (IoT), data-driven approaches for prognostics that leverage the power of machine learning models are gaining popularity. One of the most important categories of data-driven approaches relies on a predefined or learned health indicator to characterize the equipment condition up to the present time and make inference on how it is likely to evolve in the future. In these approaches, health indicator forecasting that constructs the health indicator curve over the lifespan using partially observed measurements (i.e., health indicator values within an initial period) plays a key role. Existing health indicator forecasting algorithms, such as the functional Empirical Bayesian approach, the regression-based formulation, a naive scenario matching based on the nearest neighbor, have certain limitations. In this paper, we propose a new `generative + scenario matching' algorithm for health indicator forecasting. The key idea behind the proposed approach is to first non-parametrically fit the underlying health indicator curve with a continuous Gaussian Process using a sample of run-to-failure health indicator curves. The proposed approach then generates a rich set of random curves from the learned distribution, attempting to obtain all possible variations of the target health condition evolution process over the system's lifespan. The health indicator extrapolation for a piece of functioning equipment is inferred as the generated curve that has the highest matching level within the observed period. Our experimental results show the superiority of our algorithm over the other state-of-the-art methods.
Generative Adversarial Networks for Failure Prediction
Oct 04, 2019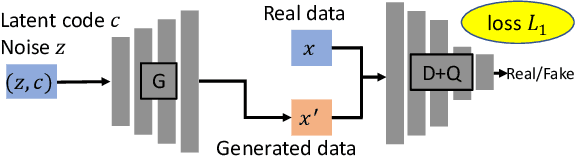
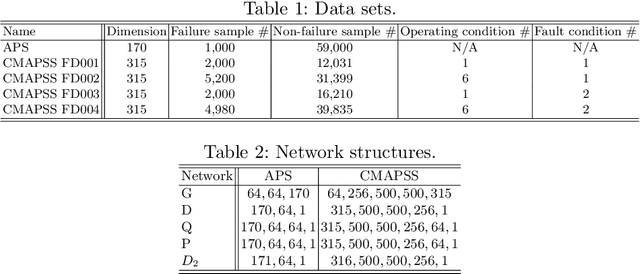
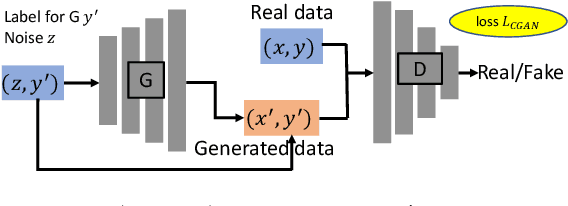
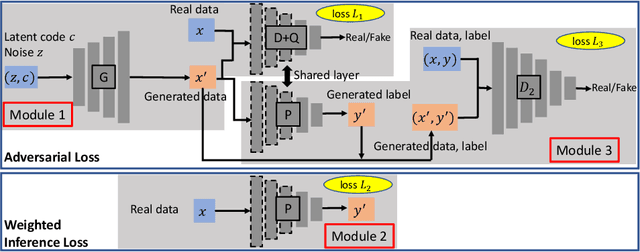
Prognostics and Health Management (PHM) is an emerging engineering discipline which is concerned with the analysis and prediction of equipment health and performance. One of the key challenges in PHM is to accurately predict impending failures in the equipment. In recent years, solutions for failure prediction have evolved from building complex physical models to the use of machine learning algorithms that leverage the data generated by the equipment. However, failure prediction problems pose a set of unique challenges that make direct application of traditional classification and prediction algorithms impractical. These challenges include the highly imbalanced training data, the extremely high cost of collecting more failure samples, and the complexity of the failure patterns. Traditional oversampling techniques will not be able to capture such complexity and accordingly result in overfitting the training data. This paper addresses these challenges by proposing a novel algorithm for failure prediction using Generative Adversarial Networks (GAN-FP). GAN-FP first utilizes two GAN networks to simultaneously generate training samples and build an inference network that can be used to predict failures for new samples. GAN-FP first adopts an infoGAN to generate realistic failure and non-failure samples, and initialize the weights of the first few layers of the inference network. The inference network is then tuned by optimizing a weighted loss objective using only real failure and non-failure samples. The inference network is further tuned using a second GAN whose purpose is to guarantee the consistency between the generated samples and corresponding labels. GAN-FP can be used for other imbalanced classification problems as well.
Remaining Useful Life Estimation Using Functional Data Analysis
Apr 12, 2019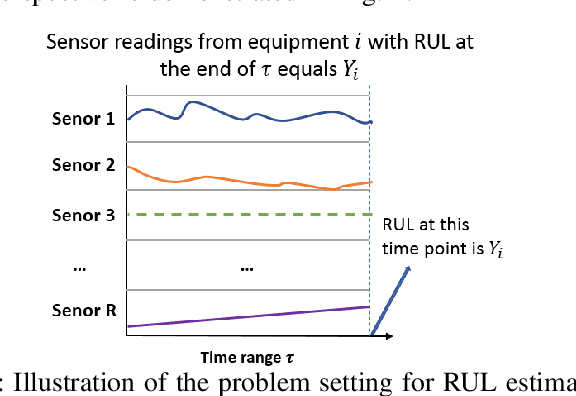
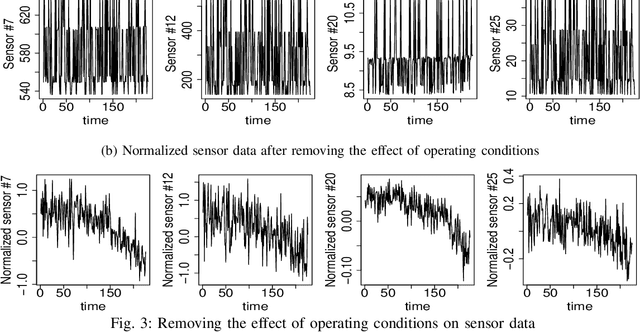
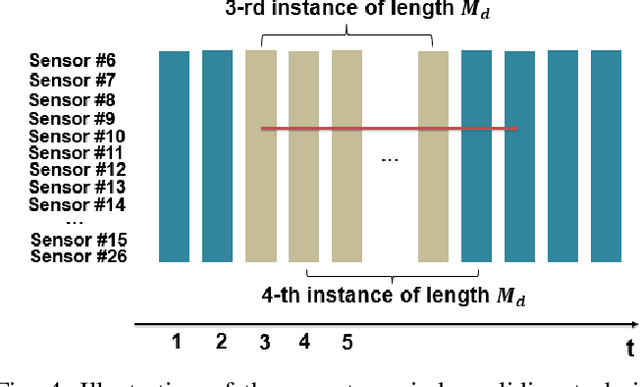
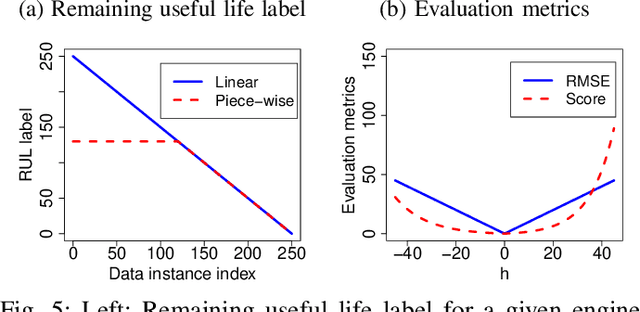
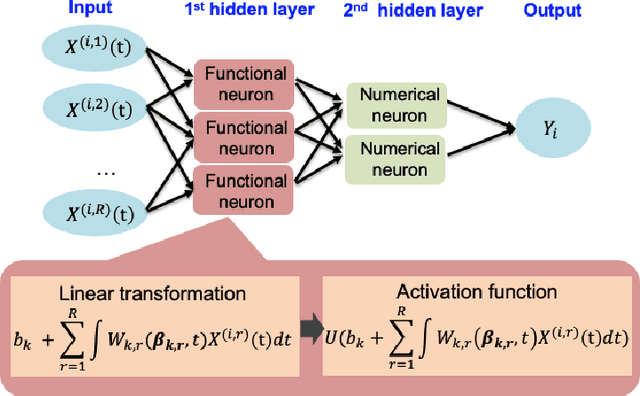
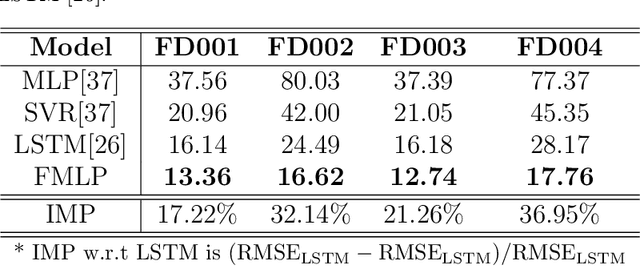
Remaining Useful Life (RUL) of an equipment or one of its components is defined as the time left until the equipment or component reaches its end of useful life. Accurate RUL estimation is exceptionally beneficial to Predictive Maintenance, and Prognostics and Health Management (PHM). Data driven approaches which leverage the power of algorithms for RUL estimation using sensor and operational time series data are gaining popularity. Existing algorithms, such as linear regression, Convolutional Neural Network (CNN), Hidden Markov Models (HMMs), and Long Short-Term Memory (LSTM), have their own limitations for the RUL estimation task. In this work, we propose a novel Functional Data Analysis (FDA) method called functional Multilayer Perceptron (functional MLP) for RUL estimation. Functional MLP treats time series data from multiple equipment as a sample of random continuous processes over time. FDA explicitly incorporates both the correlations within the same equipment and the random variations across different equipment's sensor time series into the model. FDA also has the benefit of allowing the relationship between RUL and sensor variables to vary over time. We implement functional MLP on the benchmark NASA C-MAPSS data and evaluate the performance using two popularly-used metrics. Results show the superiority of our algorithm over all the other state-of-the-art methods.
Two Birds with One Network: Unifying Failure Event Prediction and Time-to-failure Modeling
Dec 18, 2018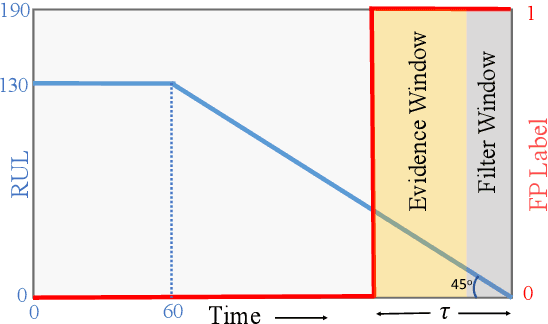
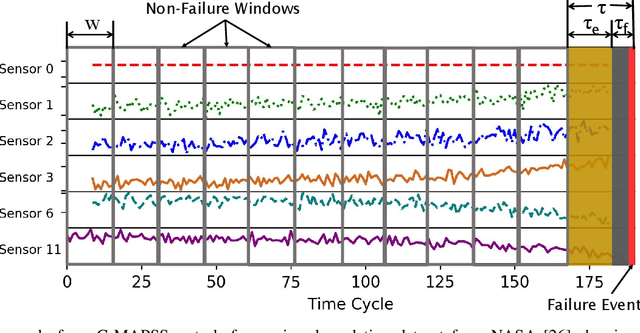
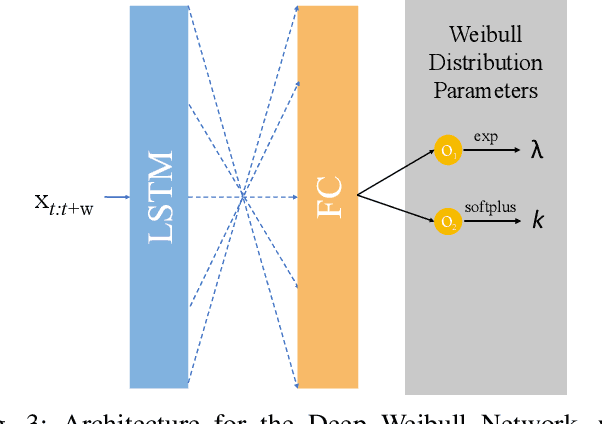
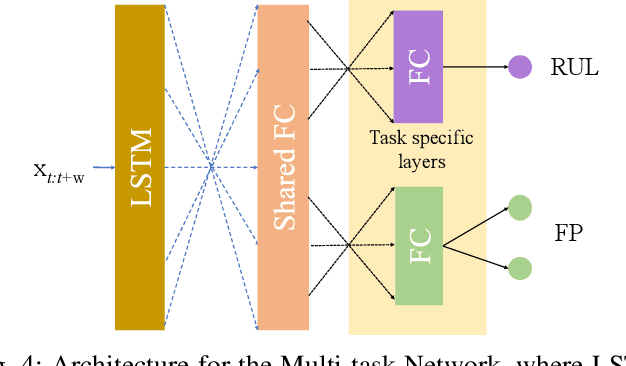
One of the key challenges in predictive maintenance is to predict the impending downtime of an equipment with a reasonable prediction horizon so that countermeasures can be put in place. Classically, this problem has been posed in two different ways which are typically solved independently: (1) Remaining useful life (RUL) estimation as a long-term prediction task to estimate how much time is left in the useful life of the equipment and (2) Failure prediction (FP) as a short-term prediction task to assess the probability of a failure within a pre-specified time window. As these two tasks are related, performing them separately is sub-optimal and might results in inconsistent predictions for the same equipment. In order to alleviate these issues, we propose two methods: Deep Weibull model (DW-RNN) and multi-task learning (MTL-RNN). DW-RNN is able to learn the underlying failure dynamics by fitting Weibull distribution parameters using a deep neural network, learned with a survival likelihood, without training directly on each task. While DW-RNN makes an explicit assumption on the data distribution, MTL-RNN exploits the implicit relationship between the long-term RUL and short-term FP tasks to learn the underlying distribution. Additionally, both our methods can leverage the non-failed equipment data for RUL estimation. We demonstrate that our methods consistently outperform baseline RUL methods that can be used for FP while producing consistent results for RUL and FP. We also show that our methods perform at par with baselines trained on the objectives optimized for either of the two tasks.