 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning with Adjustments
Sep 28, 2021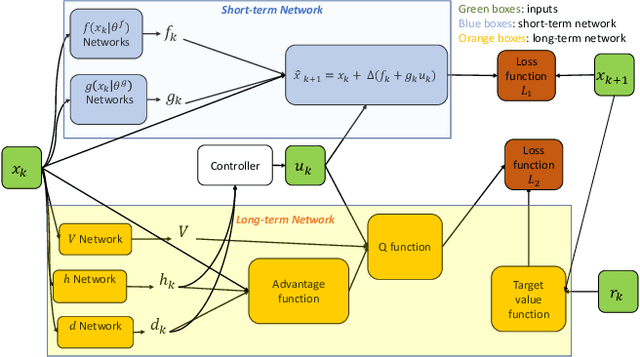
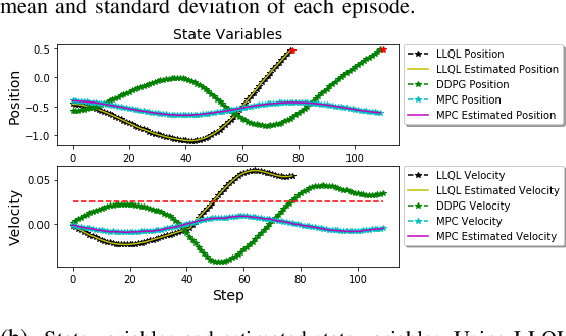
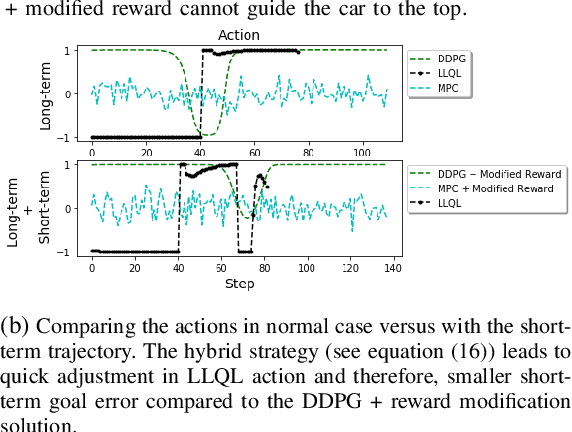
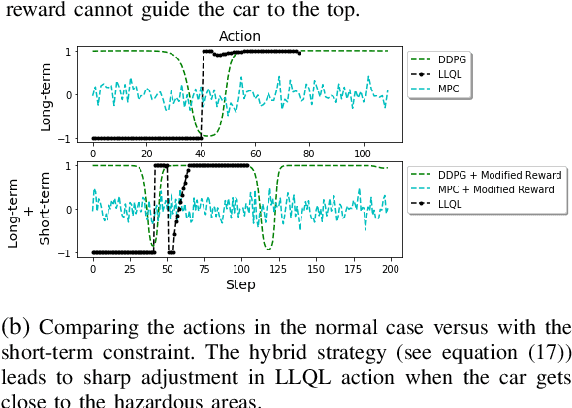
Deep reinforcement learning (RL) algorithms can learn complex policies to optimize agent operation over time. RL algorithms have shown promising results in solving complicated problems in recent years. However, their application on real-world physical systems remains limited. Despite the advancements in RL algorithms, the industries often prefer traditional control strategies. Traditional methods are simple, computationally efficient and easy to adjust. In this paper, we first propose a new Q-learning algorithm for continuous action space, which can bridge the control and RL algorithms and bring us the best of both worlds. Our method can learn complex policies to achieve long-term goals and at the same time it can be easily adjusted to address short-term requirements without retraining. Next, we present an approximation of our algorithm which can be applied to address short-term requirements of any pre-trained RL algorithm. The case studies demonstrate that both our proposed method as well as its practical approximation can achieve short-term and long-term goals without complex reward functions.
Dynamic Dispatching for Large-Scale Heterogeneous Fleet via Multi-agent Deep Reinforcement Learning
Aug 24, 2020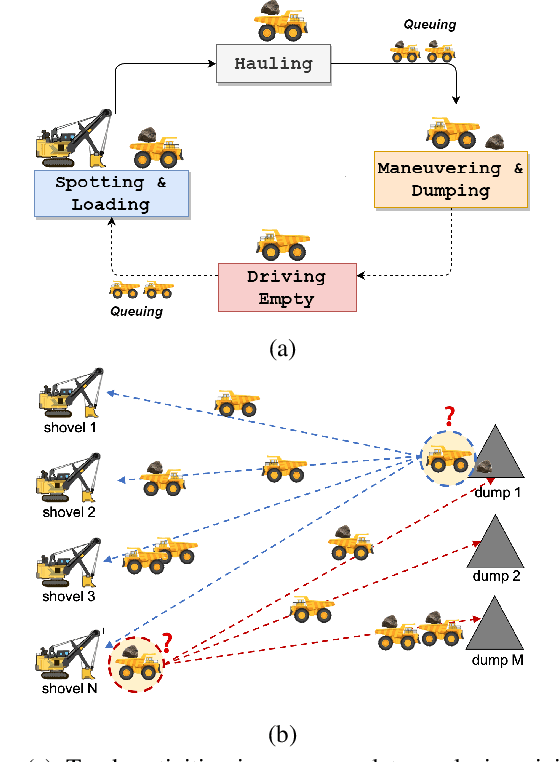
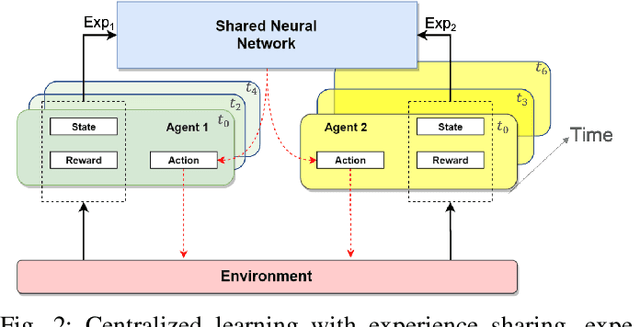
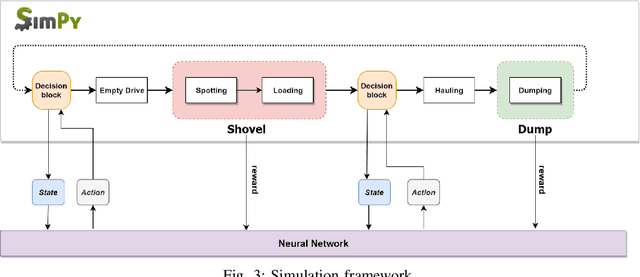
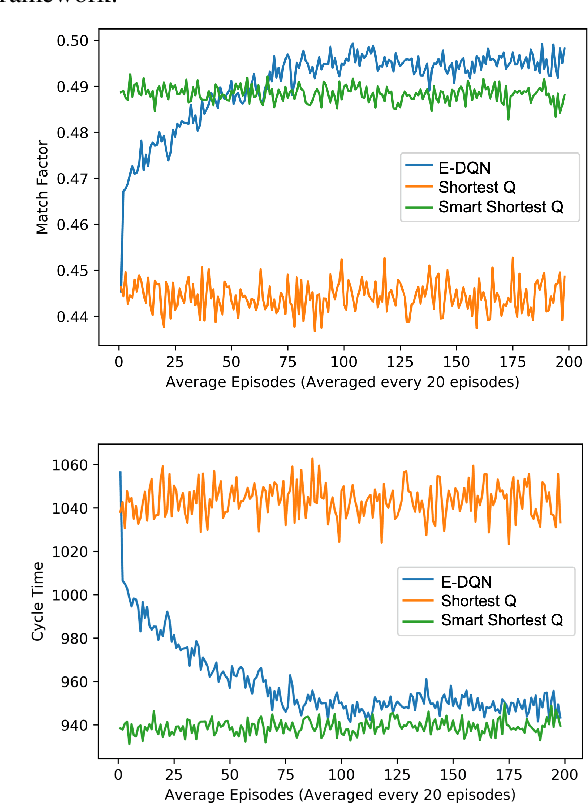
Dynamic dispatching is one of the core problems for operation optimization in traditional industries such as mining, as it is about how to smartly allocate the right resources to the right place at the right time. Conventionally, the industry relies on heuristics or even human intuitions which are often short-sighted and sub-optimal solutions. Leveraging the power of AI and Internet of Things (IoT), data-driven automation is reshaping this area. However, facing its own challenges such as large-scale and heterogenous trucks running in a highly dynamic environment, it can barely adopt methods developed in other domains (e.g., ride-sharing). In this paper, we propose a novel Deep Reinforcement Learning approach to solve the dynamic dispatching problem in mining. We first develop an event-based mining simulator with parameters calibrated in real mines. Then we propose an experience-sharing Deep Q Network with a novel abstract state/action representation to learn memories from heterogeneous agents altogether and realizes learning in a centralized way. We demonstrate that the proposed methods significantly outperform the most widely adopted approaches in the industry by $5.56\%$ in terms of productivity. The proposed approach has great potential in a broader range of industries (e.g., manufacturing, logistics) which have a large-scale of heterogenous equipment working in a highly dynamic environment, as a general framework for dynamic resource allocation.
Regularized Operating Envelope with Interpretability and Implementability Constraints
Dec 21, 2019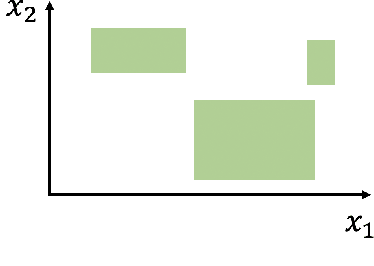
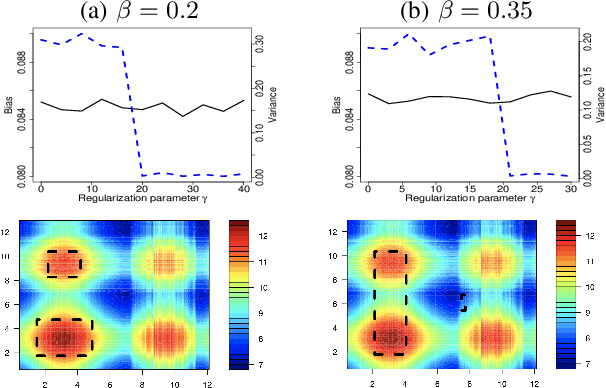
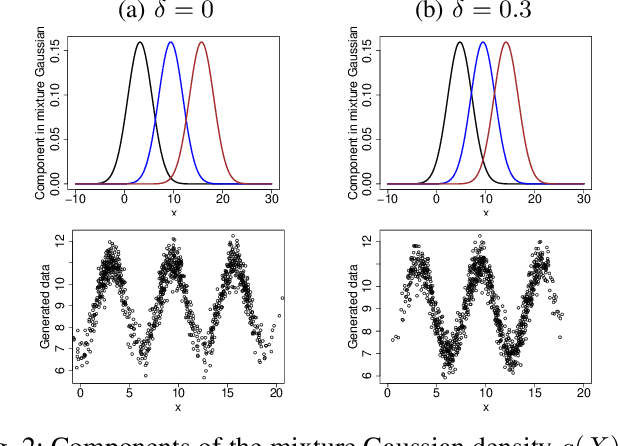
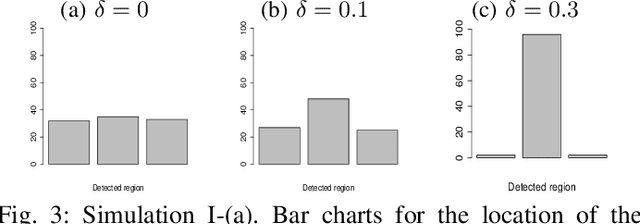
Operating envelope is an important concept in industrial operations. Accurate identification for operating envelope can be extremely beneficial to stakeholders as it provides a set of operational parameters that optimizes some key performance indicators (KPI) such as product quality, operational safety, equipment efficiency, environmental impact, etc. Given the importance, data-driven approaches for computing the operating envelope are gaining popularity. These approaches typically use classifiers such as support vector machines, to set the operating envelope by learning the boundary in the operational parameter spaces between the manually assigned `large KPI' and `small KPI' groups. One challenge to these approaches is that the assignment to these groups is often ad-hoc and hence arbitrary. However, a bigger challenge with these approaches is that they don't take into account two key features that are needed to operationalize operating envelopes: (i) interpretability of the envelope by the operator and (ii) implementability of the envelope from a practical standpoint. In this work, we propose a new definition for operating envelope which directly targets the expected magnitude of KPI (i.e., no need to arbitrarily bin the data instances into groups) and accounts for the interpretability and the implementability. We then propose a regularized `GA + penalty' algorithm that outputs an envelope where the user can tradeoff between bias and variance. The validity of our proposed algorithm is demonstrated by two sets of simulation studies and an application to a real-world challenge in the mining processes of a flotation plant.
Manufacturing Dispatching using Reinforcement and Transfer Learning
Oct 04, 2019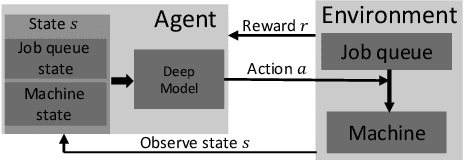
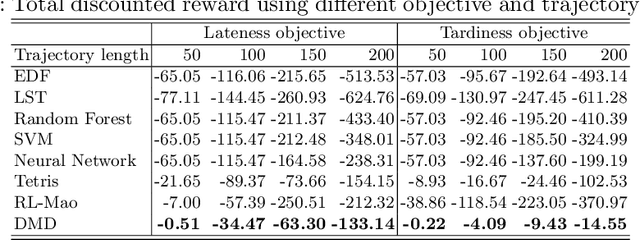
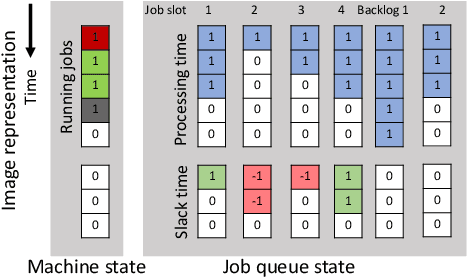
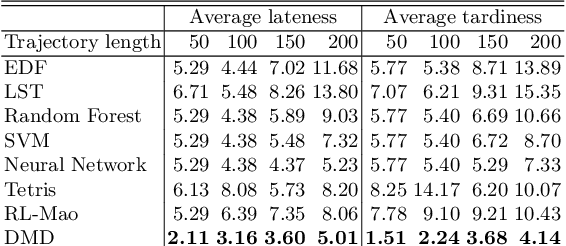
Efficient dispatching rule in manufacturing industry is key to ensure product on-time delivery and minimum past-due and inventory cost. Manufacturing, especially in the developed world, is moving towards on-demand manufacturing meaning a high mix, low volume product mix. This requires efficient dispatching that can work in dynamic and stochastic environments, meaning it allows for quick response to new orders received and can work over a disparate set of shop floor settings. In this paper we address this problem of dispatching in manufacturing. Using reinforcement learning (RL), we propose a new design to formulate the shop floor state as a 2-D matrix, incorporate job slack time into state representation, and design lateness and tardiness rewards function for dispatching purpose. However, maintaining a separate RL model for each production line on a manufacturing shop floor is costly and often infeasible. To address this, we enhance our deep RL model with an approach for dispatching policy transfer. This increases policy generalization and saves time and cost for model training and data collection. Experiments show that: (1) our approach performs the best in terms of total discounted reward and average lateness, tardiness, (2) the proposed policy transfer approach reduces training time and increases policy generalization.
Remaining Useful Life Estimation Using Functional Data Analysis
Apr 12, 2019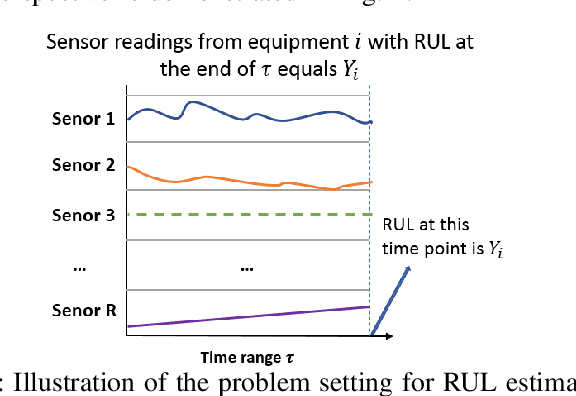
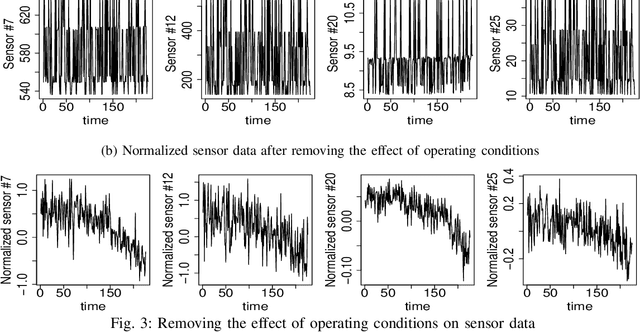
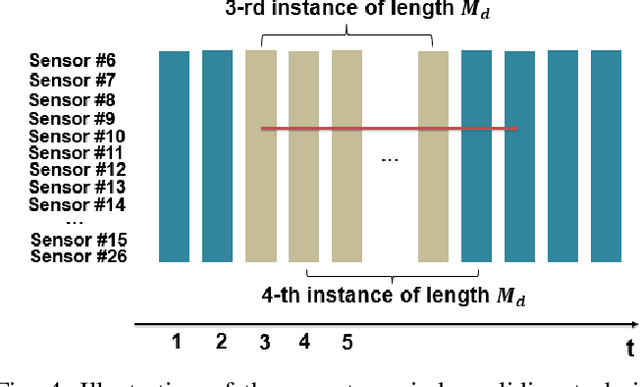
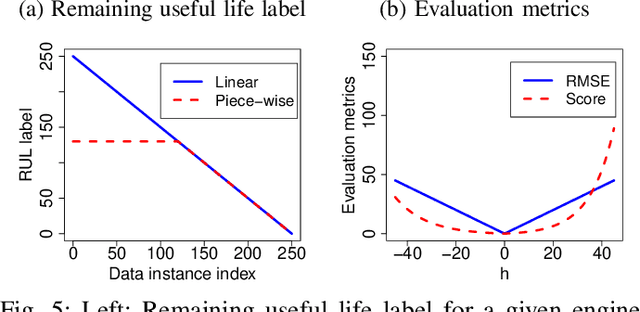
Remaining Useful Life (RUL) of an equipment or one of its components is defined as the time left until the equipment or component reaches its end of useful life. Accurate RUL estimation is exceptionally beneficial to Predictive Maintenance, and Prognostics and Health Management (PHM). Data driven approaches which leverage the power of algorithms for RUL estimation using sensor and operational time series data are gaining popularity. Existing algorithms, such as linear regression, Convolutional Neural Network (CNN), Hidden Markov Models (HMMs), and Long Short-Term Memory (LSTM), have their own limitations for the RUL estimation task. In this work, we propose a novel Functional Data Analysis (FDA) method called functional Multilayer Perceptron (functional MLP) for RUL estimation. Functional MLP treats time series data from multiple equipment as a sample of random continuous processes over time. FDA explicitly incorporates both the correlations within the same equipment and the random variations across different equipment's sensor time series into the model. FDA also has the benefit of allowing the relationship between RUL and sensor variables to vary over time. We implement functional MLP on the benchmark NASA C-MAPSS data and evaluate the performance using two popularly-used metrics. Results show the superiority of our algorithm over all the other state-of-the-art methods.