 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlled Automatic Task-Specific Synthetic Data Generation for Hallucination Detection
Oct 16, 2024



We present a novel approach to automatically generate non-trivial task-specific synthetic datasets for hallucination detection. Our approach features a two-step generation-selection pipeline, using hallucination pattern guidance and a language style alignment during generation. Hallucination pattern guidance leverages the most important task-specific hallucination patterns while language style alignment aligns the style of the synthetic dataset with benchmark text. To obtain robust supervised detectors from synthetic datasets, we also adopt a data mixture strategy to improve performance robustness and generalization. Our results on three datasets show that our generated hallucination text is more closely aligned with non-hallucinated text versus baselines, to train hallucination detectors with better generalization. Our hallucination detectors trained on synthetic datasets outperform in-context-learning (ICL)-based detectors by a large margin of 32%. Our extensive experiments confirm the benefits of our approach with cross-task and cross-generator generalization. Our data-mixture-based training further improves the generalization and robustness of hallucination detection.
Efficient Continual Pre-training for Building Domain Specific Large Language Models
Nov 14, 2023



Large language models (LLMs) have demonstrated remarkable open-domain capabilities. Traditionally, LLMs tailored for a domain are trained from scratch to excel at handling domain-specific tasks. In this work, we explore an alternative strategy of continual pre-training as a means to develop domain-specific LLMs. We introduce FinPythia-6.9B, developed through domain-adaptive continual pre-training on the financial domain. Continual pre-trained FinPythia showcases consistent improvements on financial tasks over the original foundational model. We further explore simple but effective data selection strategies for continual pre-training. Our data selection strategies outperforms vanilla continual pre-training's performance with just 10% of corpus size and cost, without any degradation on open-domain standard tasks. Our work proposes an alternative solution to building domain-specific LLMs from scratch in a cost-effective manner.
Filling out the missing gaps: Time Series Imputation with Semi-Supervised Learning
Apr 09, 2023



Missing data in time series is a challenging issue affecting time series analysis. Missing data occurs due to problems like data drops or sensor malfunctioning. Imputation methods are used to fill in these values, with quality of imputation having a significant impact on downstream tasks like classification. In this work, we propose a semi-supervised imputation method, ST-Impute, that uses both unlabeled data along with downstream task's labeled data. ST-Impute is based on sparse self-attention and trains on tasks that mimic the imputation process. Our results indicate that the proposed method outperforms the existing supervised and unsupervised time series imputation methods measured on the imputation quality as well as on the downstream tasks ingesting imputed time series.
Embarrassingly Simple MixUp for Time-series
Apr 09, 2023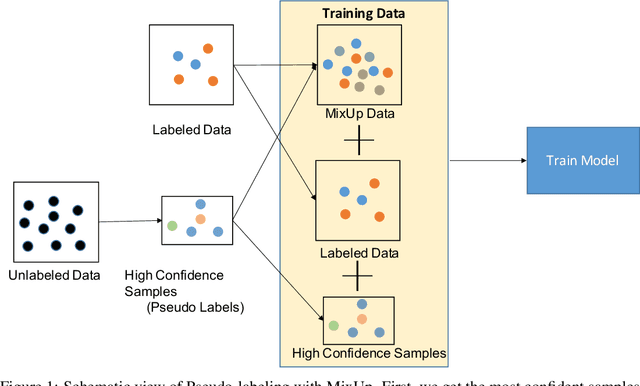
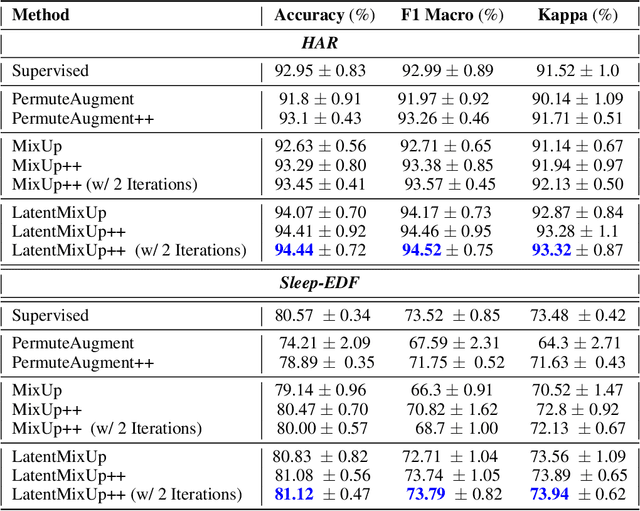
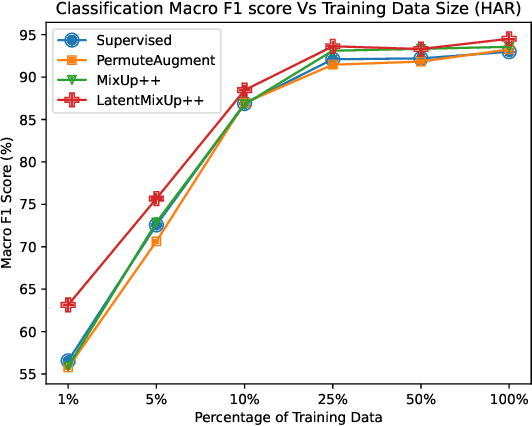
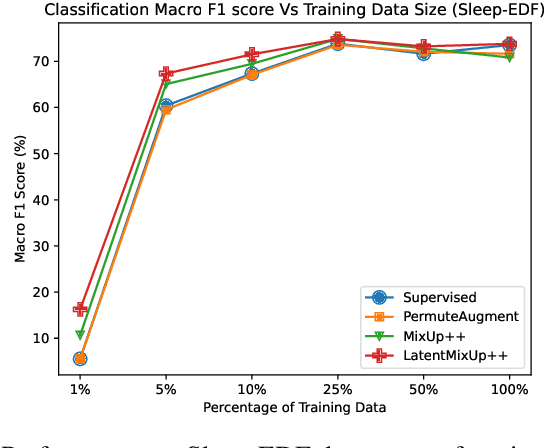
Labeling time series data is an expensive task because of domain expertise and dynamic nature of the data. Hence, we often have to deal with limited labeled data settings. Data augmentation techniques have been successfully deployed in domains like computer vision to exploit the use of existing labeled data. We adapt one of the most commonly used technique called MixUp, in the time series domain. Our proposed, MixUp++ and LatentMixUp++, use simple modifications to perform interpolation in raw time series and classification model's latent space, respectively. We also extend these methods with semi-supervised learning to exploit unlabeled data. We observe significant improvements of 1\% - 15\% on time series classification on two public datasets, for both low labeled data as well as high labeled data regimes, with LatentMixUp++.
Using Clinical Notes with Time Series Data for ICU Management
Sep 12, 2019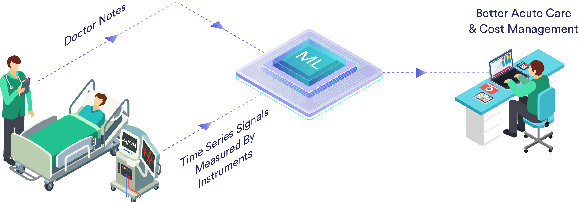
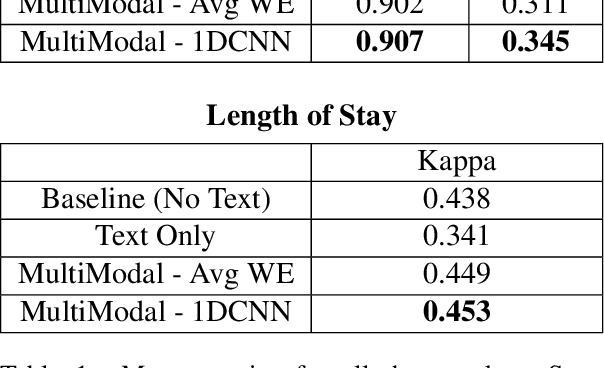
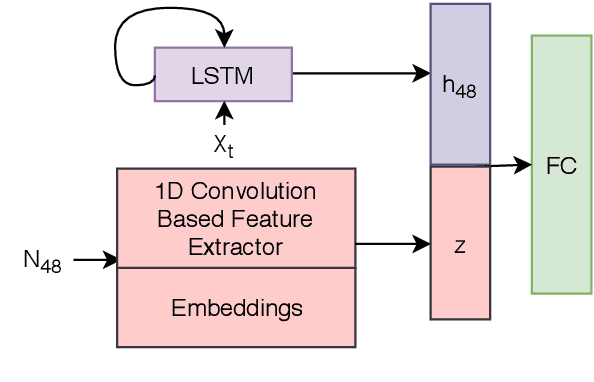
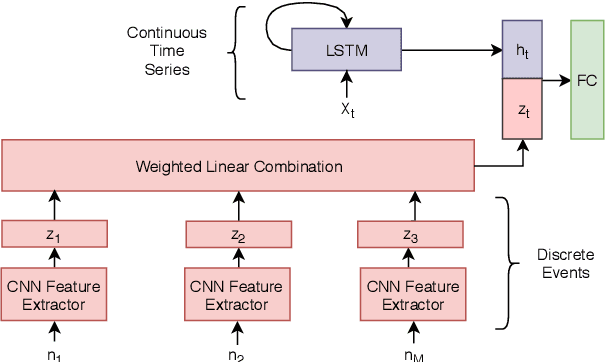
Monitoring patients in ICU is a challenging and high-cost task. Hence, predicting the condition of patients during their ICU stay can help provide better acute care and plan the hospital's resources. There has been continuous progress in machine learning research for ICU management, and most of this work has focused on using time series signals recorded by ICU instruments. In our work, we show that adding clinical notes as another modality improves the performance of the model for three benchmark tasks: in-hospital mortality prediction, modeling decompensation, and length of stay forecasting that play an important role in ICU management. While the time-series data is measured at regular intervals, doctor notes are charted at irregular times, making it challenging to model them together. We propose a method to model them jointly, achieving considerable improvement across benchmark tasks over baseline time-series model. Our implementation can be found at \url{https://github.com/kaggarwal/ClinicalNotesICU}.
Regression with Conditional GAN
Jun 01, 2019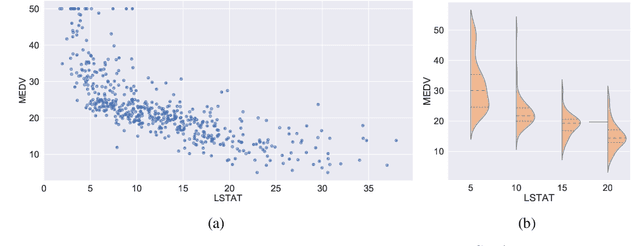
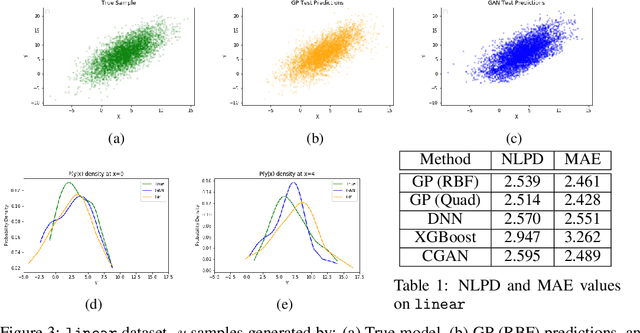
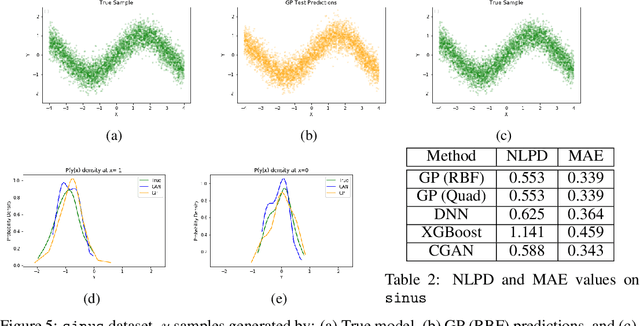
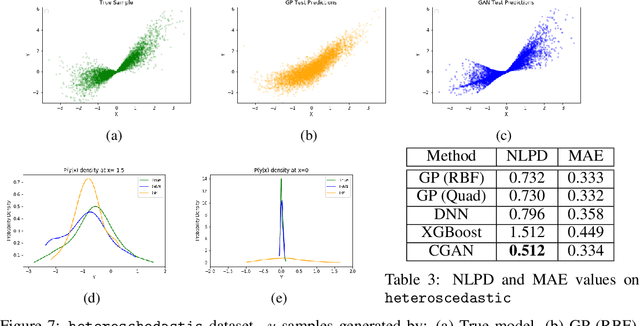
In recent years, impressive progress has been made in the design of implicit probabilistic models via Generative Adversarial Networks (GAN) and its extension, the Conditional GAN (CGAN). Excellent solutions have been demonstrated mostly in image processing applications which involve large, continuous output spaces. There is almost no application of these powerful tools to problems having small dimensional output spaces. Regression problems involving the inductive learning of a map, $y=f(x,z)$, $z$ denoting noise, $f:\mathbb{R}^n\times \mathbb{R}^k \rightarrow \mathbb{R}^m$, with $m$ small (e.g., $m=1$ or just a few) is one good case in point. The standard approach to solve regression problems is to probabilistically model the output $y$ as the sum of a mean function $m(x)$ and a noise term $z$; it is also usual to take the noise to be a Gaussian. These are done for convenience sake so that the likelihood of observed data is expressible in closed form. In the real world, on the other hand, stochasticity of the output is usually caused by missing or noisy input variables. Such a real world situation is best represented using an implicit model in which an extra noise vector, $z$ is included with $x$ as input. CGAN is naturally suited to design such implicit models. This paper makes the first step in this direction. Through several artificial and real world datasets, we demonstrate CGAN to be an effective approach for solving regression problems. We compare against Gaussian Processes and show that CGAN has excellent output likelihood properties and possesses the ability to model complex noise forms in a better way.
Optimizing the Linear Fascicle Evaluation Algorithm for Multi-Core and Many-Core Systems
May 14, 2019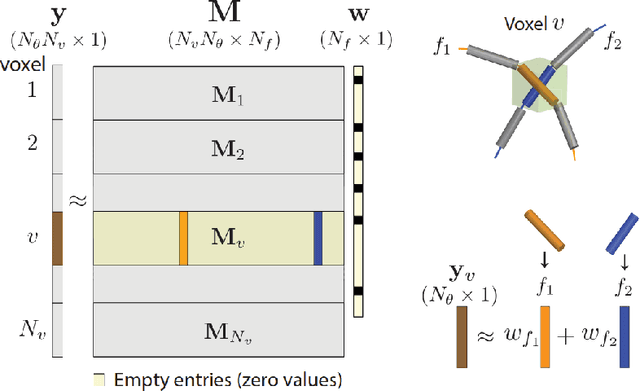
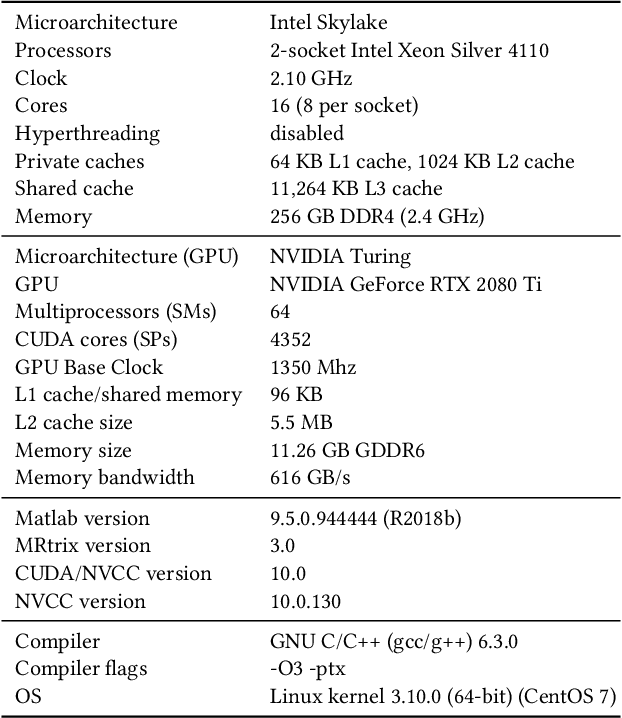
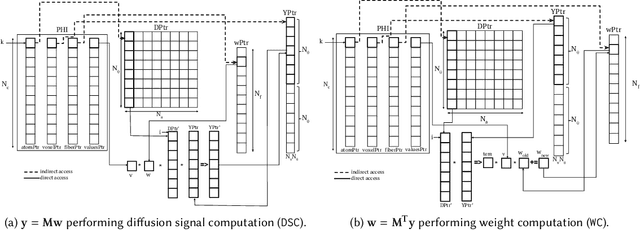
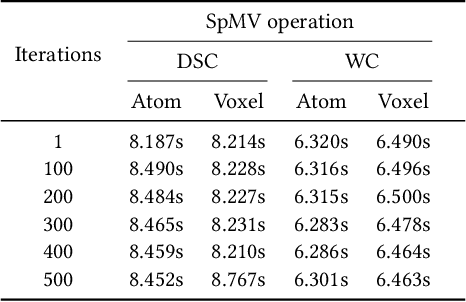
Sparse matrix-vector multiplication (SpMV) operations are commonly used in various scientific applications. The performance of the SpMV operation often depends on exploiting regularity patterns in the matrix. Various representations have been proposed to minimize the memory bandwidth bottleneck arising from the irregular memory access pattern involved. Among recent representation techniques, tensor decomposition is a popular one used for very large but sparse matrices. Post sparse-tensor decomposition, the new representation involves indirect accesses, making it challenging to optimize for multi-cores and GPUs. Computational neuroscience algorithms often involve sparse datasets while still performing long-running computations on them. The LiFE application is a popular neuroscience algorithm used for pruning brain connectivity graphs. The datasets employed herein involve the Sparse Tucker Decomposition (STD), a widely used tensor decomposition method. Using this decomposition leads to irregular array references, making it very difficult to optimize for both CPUs and GPUs. Recent codes of the LiFE algorithm show that its SpMV operations are the key bottleneck for performance and scaling. In this work, we first propose target-independent optimizations to optimize these SpMV operations, followed by target-dependent optimizations for CPU and GPU systems. The target-independent techniques include: (1) standard compiler optimizations, (2) data restructuring methods, and (3) methods to partition computations among threads. Then we present the optimizations for CPUs and GPUs to exploit platform-specific speed. Our highly optimized CPU code obtain a speedup of 27.12x over the original sequential CPU code running on 16-core Intel Xeon (Skylake-based) system, and our optimized GPU code achieves a speedup of 5.2x over a reference optimized GPU code version on NVIDIA's GeForce RTX 2080 Ti GPU.
Two Birds with One Network: Unifying Failure Event Prediction and Time-to-failure Modeling
Dec 18, 2018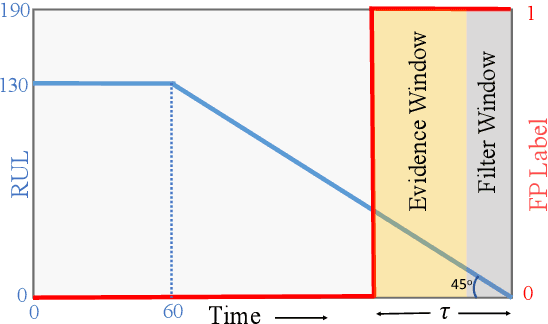
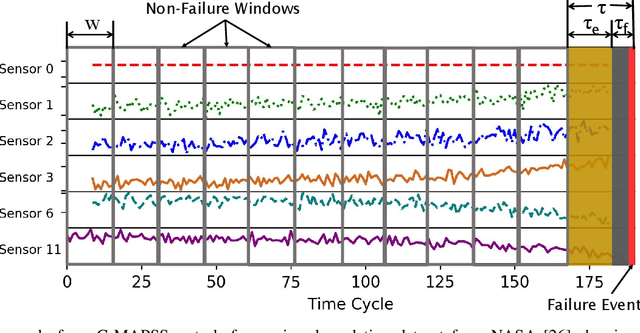
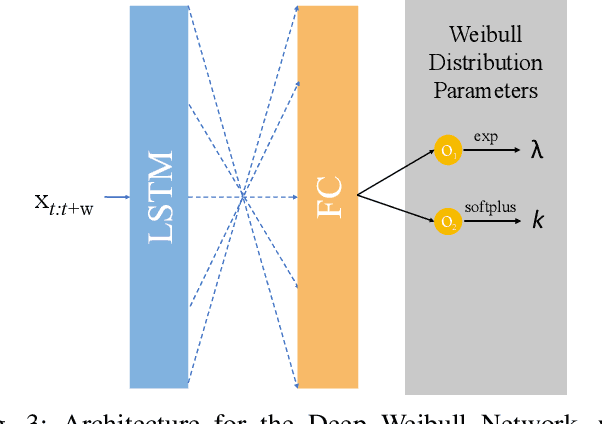
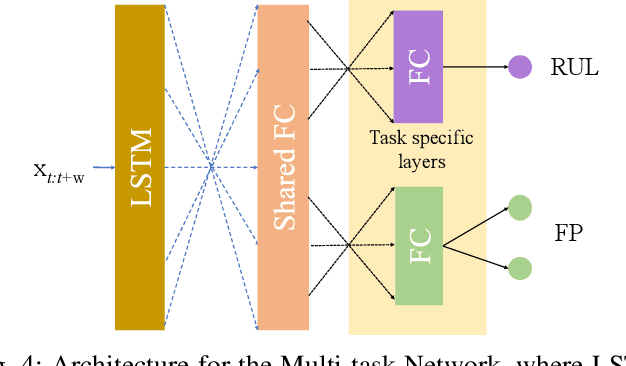
One of the key challenges in predictive maintenance is to predict the impending downtime of an equipment with a reasonable prediction horizon so that countermeasures can be put in place. Classically, this problem has been posed in two different ways which are typically solved independently: (1) Remaining useful life (RUL) estimation as a long-term prediction task to estimate how much time is left in the useful life of the equipment and (2) Failure prediction (FP) as a short-term prediction task to assess the probability of a failure within a pre-specified time window. As these two tasks are related, performing them separately is sub-optimal and might results in inconsistent predictions for the same equipment. In order to alleviate these issues, we propose two methods: Deep Weibull model (DW-RNN) and multi-task learning (MTL-RNN). DW-RNN is able to learn the underlying failure dynamics by fitting Weibull distribution parameters using a deep neural network, learned with a survival likelihood, without training directly on each task. While DW-RNN makes an explicit assumption on the data distribution, MTL-RNN exploits the implicit relationship between the long-term RUL and short-term FP tasks to learn the underlying distribution. Additionally, both our methods can leverage the non-failed equipment data for RUL estimation. We demonstrate that our methods consistently outperform baseline RUL methods that can be used for FP while producing consistent results for RUL and FP. We also show that our methods perform at par with baselines trained on the objectives optimized for either of the two tasks.
Adversarial Unsupervised Representation Learning for Activity Time-Series
Nov 14, 2018


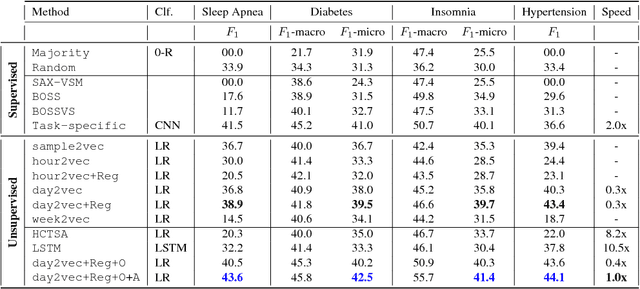
Sufficient physical activity and restful sleep play a major role in the prevention and cure of many chronic conditions. Being able to proactively screen and monitor such chronic conditions would be a big step forward for overall health. The rapid increase in the popularity of wearable devices provides a significant new source, making it possible to track the user's lifestyle real-time. In this paper, we propose a novel unsupervised representation learning technique called activity2vec that learns and "summarizes" the discrete-valued activity time-series. It learns the representations with three components: (i) the co-occurrence and magnitude of the activity levels in a time-segment, (ii) neighboring context of the time-segment, and (iii) promoting subject-invariance with adversarial training. We evaluate our method on four disorder prediction tasks using linear classifiers. Empirical evaluation demonstrates that our proposed method scales and performs better than many strong baselines. The adversarial regime helps improve the generalizability of our representations by promoting subject invariant features. We also show that using the representations at the level of a day works the best since human activity is structured in terms of daily routines
A Structured Learning Approach with Neural Conditional Random Fields for Sleep Staging
Oct 28, 2018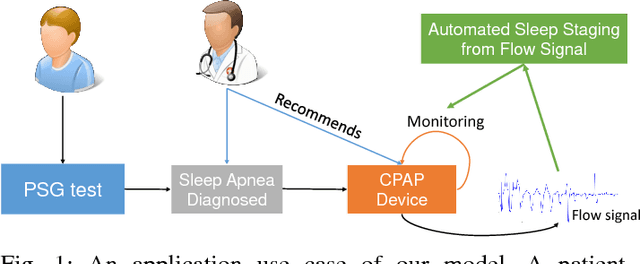
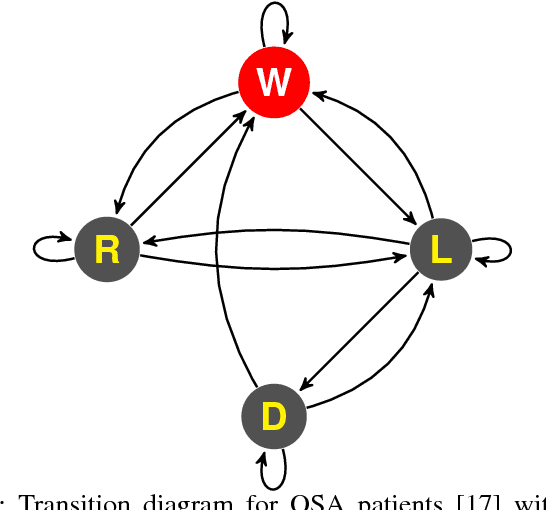
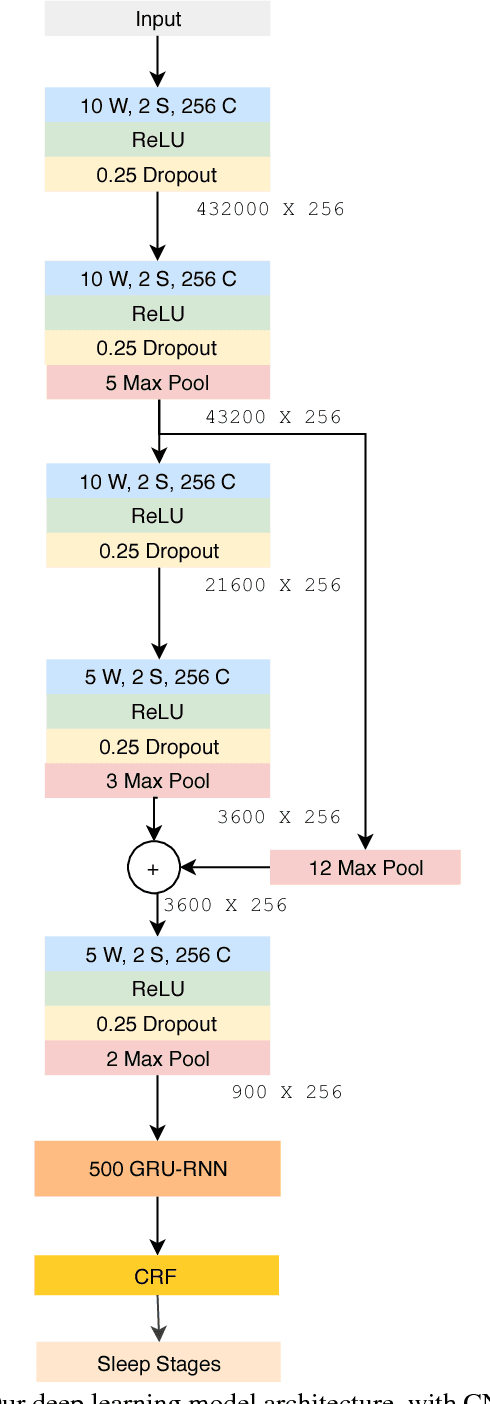
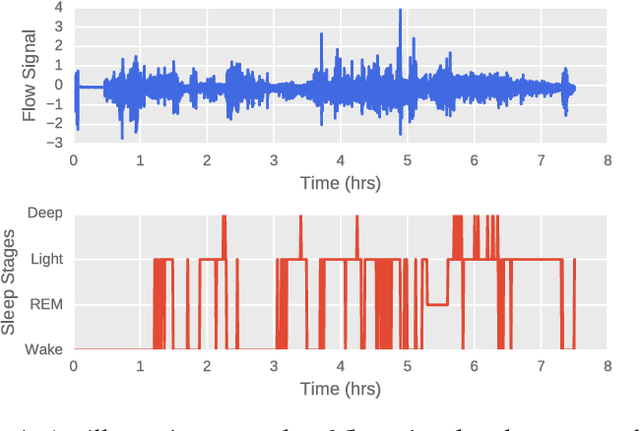
Sleep plays a vital role in human health, both mental and physical. Sleep disorders like sleep apnea are increasing in prevalence, with the rapid increase in factors like obesity. Sleep apnea is most commonly treated with Continuous Positive Air Pressure (CPAP) therapy. Presently, however, there is no mechanism to monitor a patient's progress with CPAP. Accurate detection of sleep stages from CPAP flow signal is crucial for such a mechanism. We propose, for the first time, an automated sleep staging model based only on the flow signal. Deep neural networks have recently shown high accuracy on sleep staging by eliminating handcrafted features. However, these methods focus exclusively on extracting informative features from the input signal, without paying much attention to the dynamics of sleep stages in the output sequence. We propose an end-to-end framework that uses a combination of deep convolution and recurrent neural networks to extract high-level features from raw flow signal with a structured output layer based on a conditional random field to model the temporal transition structure of the sleep stages. We improve upon the previous methods by 10% using our model, that can be augmented to the previous sleep staging deep learning methods. We also show that our method can be used to accurately track sleep metrics like sleep efficiency calculated from sleep stages that can be deployed for monitoring the response of CPAP therapy on sleep apnea patients. Apart from the technical contributions, we expect this study to motivate new research questions in sleep science.