 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Anomaly-guided Ego-graph Diffusion Model for Inductive Graph Anomaly Detection
Feb 05, 2026Graph anomaly detection (GAD) is crucial in applications like fraud detection and cybersecurity. Despite recent advancements using graph neural networks (GNNs), two major challenges persist. At the model level, most methods adopt a transductive learning paradigm, which assumes static graph structures, making them unsuitable for dynamic, evolving networks. At the data level, the extreme class imbalance, where anomalous nodes are rare, leads to biased models that fail to generalize to unseen anomalies. These challenges are interdependent: static transductive frameworks limit effective data augmentation, while imbalance exacerbates model distortion in inductive learning settings. To address these challenges, we propose a novel data-centric framework that integrates dynamic graph modeling with balanced anomaly synthesis. Our framework features: (1) a discrete ego-graph diffusion model, which captures the local topology of anomalies to generate ego-graphs aligned with anomalous structural distribution, and (2) a curriculum anomaly augmentation mechanism, which dynamically adjusts synthetic data generation during training, focusing on underrepresented anomaly patterns to improve detection and generalization. Experiments on five datasets demonstrate that the effectiveness of our framework.
Rethinking Federated Learning Over the Air: The Blessing of Scaling Up
Aug 25, 2025Federated learning facilitates collaborative model training across multiple clients while preserving data privacy. However, its performance is often constrained by limited communication resources, particularly in systems supporting a large number of clients. To address this challenge, integrating over-the-air computations into the training process has emerged as a promising solution to alleviate communication bottlenecks. The system significantly increases the number of clients it can support in each communication round by transmitting intermediate parameters via analog signals rather than digital ones. This improvement, however, comes at the cost of channel-induced distortions, such as fading and noise, which affect the aggregated global parameters. To elucidate these effects, this paper develops a theoretical framework to analyze the performance of over-the-air federated learning in large-scale client scenarios. Our analysis reveals three key advantages of scaling up the number of participating clients: (1) Enhanced Privacy: The mutual information between a client's local gradient and the server's aggregated gradient diminishes, effectively reducing privacy leakage. (2) Mitigation of Channel Fading: The channel hardening effect eliminates the impact of small-scale fading in the noisy global gradient. (3) Improved Convergence: Reduced thermal noise and gradient estimation errors benefit the convergence rate. These findings solidify over-the-air model training as a viable approach for federated learning in networks with a large number of clients. The theoretical insights are further substantiated through extensive experimental evaluations.
ReCoM: Realistic Co-Speech Motion Generation with Recurrent Embedded Transformer
Mar 27, 2025We present ReCoM, an efficient framework for generating high-fidelity and generalizable human body motions synchronized with speech. The core innovation lies in the Recurrent Embedded Transformer (RET), which integrates Dynamic Embedding Regularization (DER) into a Vision Transformer (ViT) core architecture to explicitly model co-speech motion dynamics. This architecture enables joint spatial-temporal dependency modeling, thereby enhancing gesture naturalness and fidelity through coherent motion synthesis. To enhance model robustness, we incorporate the proposed DER strategy, which equips the model with dual capabilities of noise resistance and cross-domain generalization, thereby improving the naturalness and fluency of zero-shot motion generation for unseen speech inputs. To mitigate inherent limitations of autoregressive inference, including error accumulation and limited self-correction, we propose an iterative reconstruction inference (IRI) strategy. IRI refines motion sequences via cyclic pose reconstruction, driven by two key components: (1) classifier-free guidance improves distribution alignment between generated and real gestures without auxiliary supervision, and (2) a temporal smoothing process eliminates abrupt inter-frame transitions while ensuring kinematic continuity. Extensive experiments on benchmark datasets validate ReCoM's effectiveness, achieving state-of-the-art performance across metrics. Notably, it reduces the Fr\'echet Gesture Distance (FGD) from 18.70 to 2.48, demonstrating an 86.7% improvement in motion realism. Our project page is https://yong-xie-xy.github.io/ReCoM/.
Towards Million-Scale Adversarial Robustness Evaluation With Stronger Individual Attacks
Nov 20, 2024



As deep learning models are increasingly deployed in safety-critical applications, evaluating their vulnerabilities to adversarial perturbations is essential for ensuring their reliability and trustworthiness. Over the past decade, a large number of white-box adversarial robustness evaluation methods (i.e., attacks) have been proposed, ranging from single-step to multi-step methods and from individual to ensemble methods. Despite these advances, challenges remain in conducting meaningful and comprehensive robustness evaluations, particularly when it comes to large-scale testing and ensuring evaluations reflect real-world adversarial risks. In this work, we focus on image classification models and propose a novel individual attack method, Probability Margin Attack (PMA), which defines the adversarial margin in the probability space rather than the logits space. We analyze the relationship between PMA and existing cross-entropy or logits-margin-based attacks, and show that PMA can outperform the current state-of-the-art individual methods. Building on PMA, we propose two types of ensemble attacks that balance effectiveness and efficiency. Furthermore, we create a million-scale dataset, CC1M, derived from the existing CC3M dataset, and use it to conduct the first million-scale white-box adversarial robustness evaluation of adversarially-trained ImageNet models. Our findings provide valuable insights into the robustness gaps between individual versus ensemble attacks and small-scale versus million-scale evaluations.
Controlled Automatic Task-Specific Synthetic Data Generation for Hallucination Detection
Oct 16, 2024



We present a novel approach to automatically generate non-trivial task-specific synthetic datasets for hallucination detection. Our approach features a two-step generation-selection pipeline, using hallucination pattern guidance and a language style alignment during generation. Hallucination pattern guidance leverages the most important task-specific hallucination patterns while language style alignment aligns the style of the synthetic dataset with benchmark text. To obtain robust supervised detectors from synthetic datasets, we also adopt a data mixture strategy to improve performance robustness and generalization. Our results on three datasets show that our generated hallucination text is more closely aligned with non-hallucinated text versus baselines, to train hallucination detectors with better generalization. Our hallucination detectors trained on synthetic datasets outperform in-context-learning (ICL)-based detectors by a large margin of 32%. Our extensive experiments confirm the benefits of our approach with cross-task and cross-generator generalization. Our data-mixture-based training further improves the generalization and robustness of hallucination detection.
Mutual Information Guided Optimal Transport for Unsupervised Visible-Infrared Person Re-identification
Jul 17, 2024



Unsupervised visible infrared person re-identification (USVI-ReID) is a challenging retrieval task that aims to retrieve cross-modality pedestrian images without using any label information. In this task, the large cross-modality variance makes it difficult to generate reliable cross-modality labels, and the lack of annotations also provides additional difficulties for learning modality-invariant features. In this paper, we first deduce an optimization objective for unsupervised VI-ReID based on the mutual information between the model's cross-modality input and output. With equivalent derivation, three learning principles, i.e., "Sharpness" (entropy minimization), "Fairness" (uniform label distribution), and "Fitness" (reliable cross-modality matching) are obtained. Under their guidance, we design a loop iterative training strategy alternating between model training and cross-modality matching. In the matching stage, a uniform prior guided optimal transport assignment ("Fitness", "Fairness") is proposed to select matched visible and infrared prototypes. In the training stage, we utilize this matching information to introduce prototype-based contrastive learning for minimizing the intra- and cross-modality entropy ("Sharpness"). Extensive experimental results on benchmarks demonstrate the effectiveness of our method, e.g., 60.6% and 90.3% of Rank-1 accuracy on SYSU-MM01 and RegDB without any annotations.
Orangutan: A Multiscale Brain Emulation-Based Artificial Intelligence Framework for Dynamic Environments
Jun 18, 2024Achieving General Artificial Intelligence (AGI) has long been a grand challenge in the field of AI, and brain-inspired computing is widely acknowledged as one of the most promising approaches to realize this goal. This paper introduces a novel brain-inspired AI framework, Orangutan. It simulates the structure and computational mechanisms of biological brains on multiple scales, encompassing multi-compartment neuron architectures, diverse synaptic connection modalities, neural microcircuits, cortical columns, and brain regions, as well as biochemical processes including facilitation, feedforward inhibition, short-term potentiation, and short-term depression, all grounded in solid neuroscience. Building upon these highly integrated brain-like mechanisms, I have developed a sensorimotor model that simulates human saccadic eye movements during object observation. The model's algorithmic efficacy was validated through testing with the observation of handwritten digit images.
Efficient Continual Pre-training for Building Domain Specific Large Language Models
Nov 14, 2023



Large language models (LLMs) have demonstrated remarkable open-domain capabilities. Traditionally, LLMs tailored for a domain are trained from scratch to excel at handling domain-specific tasks. In this work, we explore an alternative strategy of continual pre-training as a means to develop domain-specific LLMs. We introduce FinPythia-6.9B, developed through domain-adaptive continual pre-training on the financial domain. Continual pre-trained FinPythia showcases consistent improvements on financial tasks over the original foundational model. We further explore simple but effective data selection strategies for continual pre-training. Our data selection strategies outperforms vanilla continual pre-training's performance with just 10% of corpus size and cost, without any degradation on open-domain standard tasks. Our work proposes an alternative solution to building domain-specific LLMs from scratch in a cost-effective manner.
A Word is Worth A Thousand Dollars: Adversarial Attack on Tweets Fools Stock Prediction
May 11, 2022
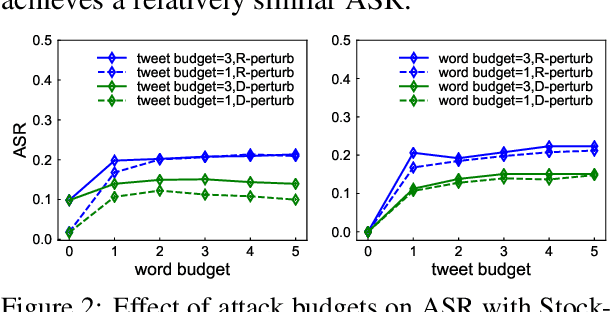

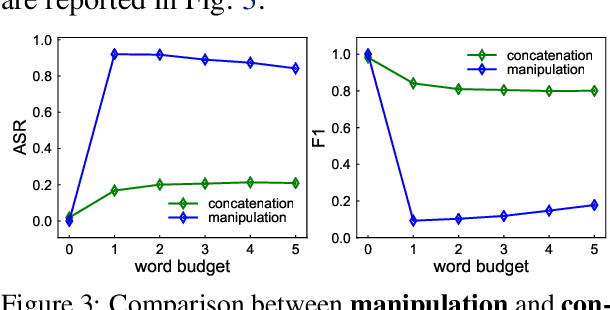
More and more investors and machine learning models rely on social media (e.g., Twitter and Reddit) to gather real-time information and sentiment to predict stock price movements. Although text-based models are known to be vulnerable to adversarial attacks, whether stock prediction models have similar vulnerability is underexplored. In this paper, we experiment with a variety of adversarial attack configurations to fool three stock prediction victim models. We address the task of adversarial generation by solving combinatorial optimization problems with semantics and budget constraints. Our results show that the proposed attack method can achieve consistent success rates and cause significant monetary loss in trading simulation by simply concatenating a perturbed but semantically similar tweet.