 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity-Aware Translation of Spurious Correlations in Zero-Shot VLMs
Jun 01, 2026Vision-Language models (VLMs), such as CLIP, achieve powerful zero-shot classification. However, their predictions remain sensitive to spurious correlations, where contextual cues dominate over semantic content. Earlier solutions typically rely on fine-tuning or prompt engineering, which either undermine the advantages of pre-trained models or are prone to hallucination. In this work, we propose Density-Aware Translation (DAT) that refines image-text similarity scores using a local geometric density term derived from group reference sets. Our approach is motivated by the phenomenon that CLIP embeddings exhibit a modality gap and lie on an anisotropic shell in the feature space: common patterns cluster near the mean, while rare patterns are pushed outward. This geometry creates uneven alignment, where spurious correlations are amplified while semantically meaningful but rare cues are marginalised. To address this, we employ a relative measure to rescale similarities based on embedding density, suppressing overconfident scores in diffuse regions while preserving dense, semantically consistent matches. Experimental results on benchmark datasets demonstrate consistent improvements in worst-group and average accuracy, highlighting density-aware translation as a simple and effective calibration mechanism for reliable zero-shot classification using multimodal models.
AudioMosaic: Contrastive Masked Audio Representation Learning
May 14, 2026Audio self-supervised learning (SSL) aims to learn general-purpose representations from large-scale unlabeled audio data. While recent advances have been driven mainly by generative reconstruction objectives, contrastive approaches remain less explored, partly due to the difficulty of designing effective audio augmentations and the large batch sizes required for contrastive pre-training. We introduce \textbf{AudioMosaic}, a contrastive learning-based audio encoder for general audio understanding. During pre-training, AudioMosaic constructs positive pairs by applying structured time-frequency masking to spectrogram patches, which reduces memory usage and enables efficient large-batch training. Compared with generative approaches, the AudioMosaic encoder learns more discriminative utterance-level representations that demonstrate strong transferability across datasets, domains, and acoustic conditions. Extensive experiments show that AudioMosaic achieves state-of-the-art performance on several standard audio benchmarks under both linear probing and fine-tuning. We further show that integrating the pretrained AudioMosaic encoder into audio-language models improves performance on audio-language tasks. The code is publicly available in our \href{https://github.com/HanxunH/AudioMosaic}{GitHub repository}.
Semantic-aware Adversarial Fine-tuning for CLIP
Feb 12, 2026Recent studies have shown that CLIP model's adversarial robustness in zero-shot classification tasks can be enhanced by adversarially fine-tuning its image encoder with adversarial examples (AEs), which are generated by minimizing the cosine similarity between images and a hand-crafted template (e.g., ''A photo of a {label}''). However, it has been shown that the cosine similarity between a single image and a single hand-crafted template is insufficient to measure the similarity for image-text pairs. Building on this, in this paper, we find that the AEs generated using cosine similarity may fail to fool CLIP when the similarity metric is replaced with semantically enriched alternatives, making the image encoder fine-tuned with these AEs less robust. To overcome this issue, we first propose a semantic-ensemble attack to generate semantic-aware AEs by minimizing the average similarity between the original image and an ensemble of refined textual descriptions. These descriptions are initially generated by a foundation model to capture core semantic features beyond hand-crafted templates and are then refined to reduce hallucinations. To this end, we propose Semantic-aware Adversarial Fine-Tuning (SAFT), which fine-tunes CLIP's image encoder with semantic-aware AEs. Extensive experiments show that SAFT outperforms current methods, achieving substantial improvements in zero-shot adversarial robustness across 16 datasets. Our code is available at: https://github.com/tmlr-group/SAFT.
Toward Universal and Transferable Jailbreak Attacks on Vision-Language Models
Feb 01, 2026Vision-language models (VLMs) extend large language models (LLMs) with vision encoders, enabling text generation conditioned on both images and text. However, this multimodal integration expands the attack surface by exposing the model to image-based jailbreaks crafted to induce harmful responses. Existing gradient-based jailbreak methods transfer poorly, as adversarial patterns overfit to a single white-box surrogate and fail to generalise to black-box models. In this work, we propose Universal and transferable jailbreak (UltraBreak), a framework that constrains adversarial patterns through transformations and regularisation in the vision space, while relaxing textual targets through semantic-based objectives. By defining its loss in the textual embedding space of the target LLM, UltraBreak discovers universal adversarial patterns that generalise across diverse jailbreak objectives. This combination of vision-level regularisation and semantically guided textual supervision mitigates surrogate overfitting and enables strong transferability across both models and attack targets. Extensive experiments show that UltraBreak consistently outperforms prior jailbreak methods. Further analysis reveals why earlier approaches fail to transfer, highlighting that smoothing the loss landscape via semantic objectives is crucial for enabling universal and transferable jailbreaks. The code is publicly available in our \href{https://github.com/kaiyuanCui/UltraBreak}{GitHub repository}.
Just Ask: Curious Code Agents Reveal System Prompts in Frontier LLMs
Jan 29, 2026Autonomous code agents built on large language models are reshaping software and AI development through tool use, long-horizon reasoning, and self-directed interaction. However, this autonomy introduces a previously unrecognized security risk: agentic interaction fundamentally expands the LLM attack surface, enabling systematic probing and recovery of hidden system prompts that guide model behavior. We identify system prompt extraction as an emergent vulnerability intrinsic to code agents and present \textbf{\textsc{JustAsk}}, a self-evolving framework that autonomously discovers effective extraction strategies through interaction alone. Unlike prior prompt-engineering or dataset-based attacks, \textsc{JustAsk} requires no handcrafted prompts, labeled supervision, or privileged access beyond standard user interaction. It formulates extraction as an online exploration problem, using Upper Confidence Bound-based strategy selection and a hierarchical skill space spanning atomic probes and high-level orchestration. These skills exploit imperfect system-instruction generalization and inherent tensions between helpfulness and safety. Evaluated on \textbf{41} black-box commercial models across multiple providers, \textsc{JustAsk} consistently achieves full or near-complete system prompt recovery, revealing recurring design- and architecture-level vulnerabilities. Our results expose system prompts as a critical yet largely unprotected attack surface in modern agent systems.
AUDETER: A Large-scale Dataset for Deepfake Audio Detection in Open Worlds
Sep 04, 2025



Speech generation systems can produce remarkably realistic vocalisations that are often indistinguishable from human speech, posing significant authenticity challenges. Although numerous deepfake detection methods have been developed, their effectiveness in real-world environments remains unrealiable due to the domain shift between training and test samples arising from diverse human speech and fast evolving speech synthesis systems. This is not adequately addressed by current datasets, which lack real-world application challenges with diverse and up-to-date audios in both real and deep-fake categories. To fill this gap, we introduce AUDETER (AUdio DEepfake TEst Range), a large-scale, highly diverse deepfake audio dataset for comprehensive evaluation and robust development of generalised models for deepfake audio detection. It consists of over 4,500 hours of synthetic audio generated by 11 recent TTS models and 10 vocoders with a broad range of TTS/vocoder patterns, totalling 3 million audio clips, making it the largest deepfake audio dataset by scale. Through extensive experiments with AUDETER, we reveal that i) state-of-the-art (SOTA) methods trained on existing datasets struggle to generalise to novel deepfake audio samples and suffer from high false positive rates on unseen human voice, underscoring the need for a comprehensive dataset; and ii) these methods trained on AUDETER achieve highly generalised detection performance and significantly reduce detection error rate by 44.1% to 51.6%, achieving an error rate of only 4.17% on diverse cross-domain samples in the popular In-the-Wild dataset, paving the way for training generalist deepfake audio detectors. AUDETER is available on GitHub.
X-Transfer Attacks: Towards Super Transferable Adversarial Attacks on CLIP
May 08, 2025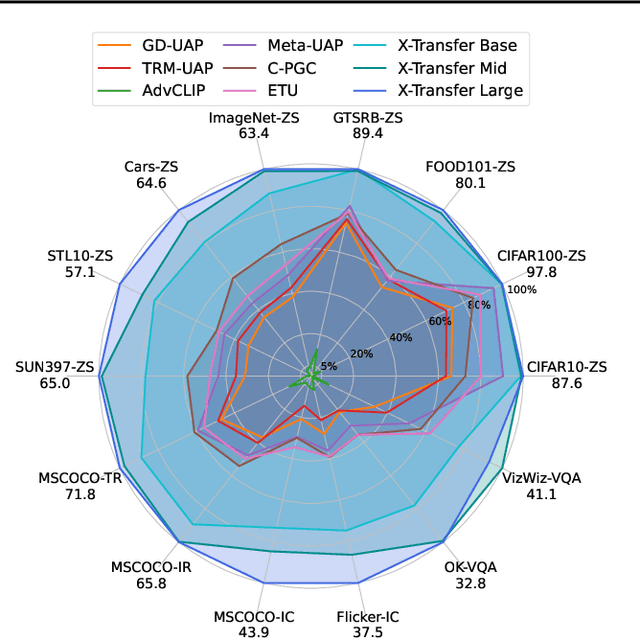
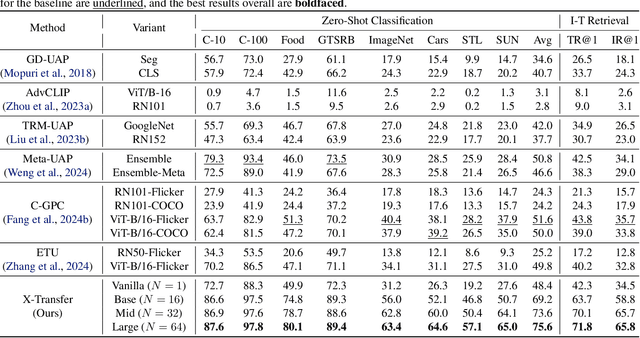
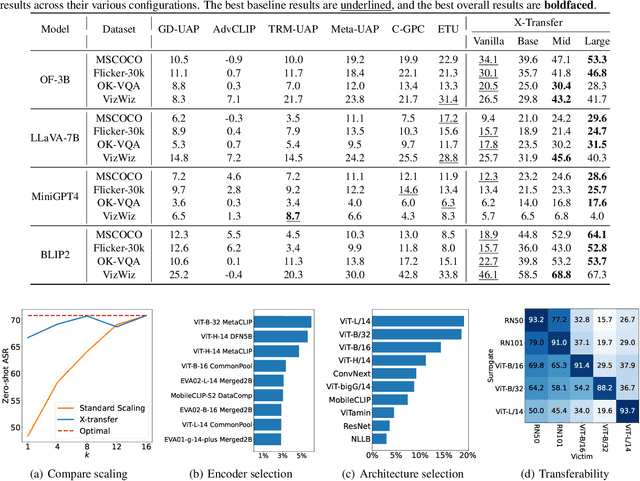

As Contrastive Language-Image Pre-training (CLIP) models are increasingly adopted for diverse downstream tasks and integrated into large vision-language models (VLMs), their susceptibility to adversarial perturbations has emerged as a critical concern. In this work, we introduce \textbf{X-Transfer}, a novel attack method that exposes a universal adversarial vulnerability in CLIP. X-Transfer generates a Universal Adversarial Perturbation (UAP) capable of deceiving various CLIP encoders and downstream VLMs across different samples, tasks, and domains. We refer to this property as \textbf{super transferability}--a single perturbation achieving cross-data, cross-domain, cross-model, and cross-task adversarial transferability simultaneously. This is achieved through \textbf{surrogate scaling}, a key innovation of our approach. Unlike existing methods that rely on fixed surrogate models, which are computationally intensive to scale, X-Transfer employs an efficient surrogate scaling strategy that dynamically selects a small subset of suitable surrogates from a large search space. Extensive evaluations demonstrate that X-Transfer significantly outperforms previous state-of-the-art UAP methods, establishing a new benchmark for adversarial transferability across CLIP models. The code is publicly available in our \href{https://github.com/HanxunH/XTransferBench}{GitHub repository}.
CURVALID: Geometrically-guided Adversarial Prompt Detection
Mar 05, 2025Adversarial prompts capable of jailbreaking large language models (LLMs) and inducing undesirable behaviours pose a significant obstacle to their safe deployment. Current mitigation strategies rely on activating built-in defence mechanisms or fine-tuning the LLMs, but the fundamental distinctions between adversarial and benign prompts are yet to be understood. In this work, we introduce CurvaLID, a novel defense framework that efficiently detects adversarial prompts by leveraging their geometric properties. It is agnostic to the type of LLM, offering a unified detection framework across diverse adversarial prompts and LLM architectures. CurvaLID builds on the geometric analysis of text prompts to uncover their underlying differences. We theoretically extend the concept of curvature via the Whewell equation into an $n$-dimensional word embedding space, enabling us to quantify local geometric properties, including semantic shifts and curvature in the underlying manifolds. Additionally, we employ Local Intrinsic Dimensionality (LID) to capture geometric features of text prompts within adversarial subspaces. Our findings reveal that adversarial prompts differ fundamentally from benign prompts in terms of their geometric characteristics. Our results demonstrate that CurvaLID delivers superior detection and rejection of adversarial queries, paving the way for safer LLM deployment. The source code can be found at https://github.com/Cancanxxx/CurvaLID
Detecting Backdoor Samples in Contrastive Language Image Pretraining
Feb 03, 2025Contrastive language-image pretraining (CLIP) has been found to be vulnerable to poisoning backdoor attacks where the adversary can achieve an almost perfect attack success rate on CLIP models by poisoning only 0.01\% of the training dataset. This raises security concerns on the current practice of pretraining large-scale models on unscrutinized web data using CLIP. In this work, we analyze the representations of backdoor-poisoned samples learned by CLIP models and find that they exhibit unique characteristics in their local subspace, i.e., their local neighborhoods are far more sparse than that of clean samples. Based on this finding, we conduct a systematic study on detecting CLIP backdoor attacks and show that these attacks can be easily and efficiently detected by traditional density ratio-based local outlier detectors, whereas existing backdoor sample detection methods fail. Our experiments also reveal that an unintentional backdoor already exists in the original CC3M dataset and has been trained into a popular open-source model released by OpenCLIP. Based on our detector, one can clean up a million-scale web dataset (e.g., CC3M) efficiently within 15 minutes using 4 Nvidia A100 GPUs. The code is publicly available in our \href{https://github.com/HanxunH/Detect-CLIP-Backdoor-Samples}{GitHub repository}.
Towards Million-Scale Adversarial Robustness Evaluation With Stronger Individual Attacks
Nov 20, 2024



As deep learning models are increasingly deployed in safety-critical applications, evaluating their vulnerabilities to adversarial perturbations is essential for ensuring their reliability and trustworthiness. Over the past decade, a large number of white-box adversarial robustness evaluation methods (i.e., attacks) have been proposed, ranging from single-step to multi-step methods and from individual to ensemble methods. Despite these advances, challenges remain in conducting meaningful and comprehensive robustness evaluations, particularly when it comes to large-scale testing and ensuring evaluations reflect real-world adversarial risks. In this work, we focus on image classification models and propose a novel individual attack method, Probability Margin Attack (PMA), which defines the adversarial margin in the probability space rather than the logits space. We analyze the relationship between PMA and existing cross-entropy or logits-margin-based attacks, and show that PMA can outperform the current state-of-the-art individual methods. Building on PMA, we propose two types of ensemble attacks that balance effectiveness and efficiency. Furthermore, we create a million-scale dataset, CC1M, derived from the existing CC3M dataset, and use it to conduct the first million-scale white-box adversarial robustness evaluation of adversarially-trained ImageNet models. Our findings provide valuable insights into the robustness gaps between individual versus ensemble attacks and small-scale versus million-scale evaluations.