 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCROCS: A Two-Stage Clustering Framework for Behaviour-Centric Consumer Segmentation with Smart Meter Data
Jan 15, 2026With grid operators confronting rising uncertainty from renewable integration and a broader push toward electrification, Demand-Side Management (DSM) -- particularly Demand Response (DR) -- has attracted significant attention as a cost-effective mechanism for balancing modern electricity systems. Unprecedented volumes of consumption data from a continuing global deployment of smart meters enable consumer segmentation based on real usage behaviours, promising to inform the design of more effective DSM and DR programs. However, existing clustering-based segmentation methods insufficiently reflect the behavioural diversity of consumers, often relying on rigid temporal alignment, and faltering in the presence of anomalies, missing data, or large-scale deployments. To address these challenges, we propose a novel two-stage clustering framework -- Clustered Representations Optimising Consumer Segmentation (CROCS). In the first stage, each consumer's daily load profiles are clustered independently to form a Representative Load Set (RLS), providing a compact summary of their typical diurnal consumption behaviours. In the second stage, consumers are clustered using the Weighted Sum of Minimum Distances (WSMD), a novel set-to-set measure that compares RLSs by accounting for both the prevalence and similarity of those behaviours. Finally, community detection on the WSMD-induced graph reveals higher-order prototypes that embody the shared diurnal behaviours defining consumer groups, enhancing the interpretability of the resulting clusters. Extensive experiments on both synthetic and real Australian smart meter datasets demonstrate that CROCS captures intra-consumer variability, uncovers both synchronous and asynchronous behavioural similarities, and remains robust to anomalies and missing data, while scaling efficiently through natural parallelisation. These results...
Benchmarking of Clustering Validity Measures Revisited
Nov 08, 2025

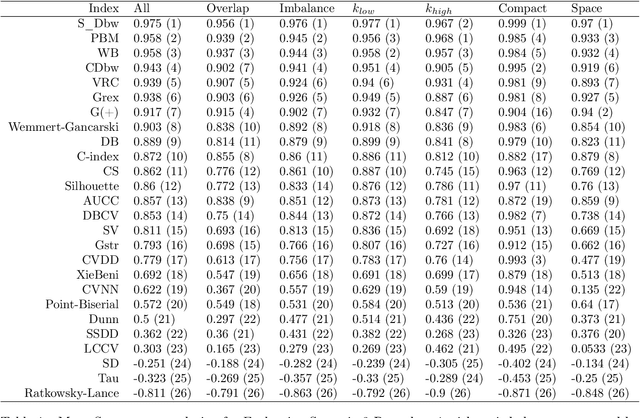

Validation plays a crucial role in the clustering process. Many different internal validity indexes exist for the purpose of determining the best clustering solution(s) from a given collection of candidates, e.g., as produced by different algorithms or different algorithm hyper-parameters. In this study, we present a comprehensive benchmark study of 26 internal validity indexes, which includes highly popular classic indexes as well as more recently developed ones. We adopted an enhanced revision of the methodology presented in Vendramin et al. (2010), developed here to address several shortcomings of this previous work. This overall new approach consists of three complementary custom-tailored evaluation sub-methodologies, each of which has been designed to assess specific aspects of an index's behaviour while preventing potential biases of the other sub-methodologies. Each sub-methodology features two complementary measures of performance, alongside mechanisms that allow for an in-depth investigation of more complex behaviours of the internal validity indexes under study. Additionally, a new collection of 16177 datasets has been produced, paired with eight widely-used clustering algorithms, for a wider applicability scope and representation of more diverse clustering scenarios.
Robust Statistical Scaling of Outlier Scores: Improving the Quality of Outlier Probabilities for Outliers (Extended Version)
Aug 30, 2024Outlier detection algorithms typically assign an outlier score to each observation in a dataset, indicating the degree to which an observation is an outlier. However, these scores are often not comparable across algorithms and can be difficult for humans to interpret. Statistical scaling addresses this problem by transforming outlier scores into outlier probabilities without using ground-truth labels, thereby improving interpretability and comparability across algorithms. However, the quality of this transformation can be different for outliers and inliers. Missing outliers in scenarios where they are of particular interest - such as healthcare, finance, or engineering - can be costly or dangerous. Thus, ensuring good probabilities for outliers is essential. This paper argues that statistical scaling, as commonly used in the literature, does not produce equally good probabilities for outliers as for inliers. Therefore, we propose robust statistical scaling, which uses robust estimators to improve the probabilities for outliers. We evaluate several variants of our method against other outlier score transformations for real-world datasets and outlier detection algorithms, where it can improve the probabilities for outliers.
On the Use of Relative Validity Indices for Comparing Clustering Approaches
Apr 16, 2024



Relative Validity Indices (RVIs) such as the Silhouette Width Criterion, Calinski-Harabasz and Davie's Bouldin indices are the most popular tools for evaluating and optimising applications of clustering. Their ability to rank collections of candidate partitions has been used to guide the selection of the number of clusters, and to compare partitions from different clustering algorithms. Beyond these more conventional tasks, many examples can be found in the literature where RVIs have been used to compare and select other aspects of clustering approaches such as data normalisation procedures, data representation methods, and distance measures. The authors are not aware of any studies that have attempted to establish the suitability of RVIs for such comparisons. Moreover, given the impact of these aspects on pairwise similarities, it is not even immediately obvious how RVIs should be implemented when comparing these aspects. In this study, we conducted experiments with seven common RVIs on over 2.7 million clustering partitions for both synthetic and real-world datasets, encompassing feature-vector and time-series data. Our findings suggest that RVIs are not well-suited to these unconventional tasks, and that conclusions drawn from such applications may be misleading. It is recommended that normalisation procedures, representation methods, and distance measures instead be selected using external validation on high quality labelled datasets or carefully designed outcome-oriented objective criteria, both of which should be informed by relevant domain knowledge and clustering aims.
LDReg: Local Dimensionality Regularized Self-Supervised Learning
Jan 19, 2024



Representations learned via self-supervised learning (SSL) can be susceptible to dimensional collapse, where the learned representation subspace is of extremely low dimensionality and thus fails to represent the full data distribution and modalities. Dimensional collapse also known as the "underfilling" phenomenon is one of the major causes of degraded performance on downstream tasks. Previous work has investigated the dimensional collapse problem of SSL at a global level. In this paper, we demonstrate that representations can span over high dimensional space globally, but collapse locally. To address this, we propose a method called $\textit{local dimensionality regularization (LDReg)}$. Our formulation is based on the derivation of the Fisher-Rao metric to compare and optimize local distance distributions at an asymptotically small radius for each data point. By increasing the local intrinsic dimensionality, we demonstrate through a range of experiments that LDReg improves the representation quality of SSL. The results also show that LDReg can regularize dimensionality at both local and global levels.
Dimensionality-Aware Outlier Detection: Theoretical and Experimental Analysis
Jan 10, 2024



We present a nonparametric method for outlier detection that takes full account of local variations in intrinsic dimensionality within the dataset. Using the theory of Local Intrinsic Dimensionality (LID), our 'dimensionality-aware' outlier detection method, DAO, is derived as an estimator of an asymptotic local expected density ratio involving the query point and a close neighbor drawn at random. The dimensionality-aware behavior of DAO is due to its use of local estimation of LID values in a theoretically-justified way. Through comprehensive experimentation on more than 800 synthetic and real datasets, we show that DAO significantly outperforms three popular and important benchmark outlier detection methods: Local Outlier Factor (LOF), Simplified LOF, and kNN.