 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Imbalanced Dataset with Multiple Feature Representations for Studying Quality Control of Next-Generation Sequencing
Apr 04, 2026Next-generation sequencing (NGS) is a key technique for studying the DNA and RNA of organisms. However, identifying quality problems in NGS data across different experimental settings remains challenging. To develop automated quality-control tools, researchers require datasets with features that capture the characteristics of quality problems. Existing NGS repositories, however, offer only a limited number of quality-related features. To address this gap, we propose a dataset derived from 37.491 NGS samples with two types of quality-related feature representations. The first type consists of 34 features derived from quality control tools (QC-34 features). The second type has a variable number of features ranging from eight to 1.183. These features were derived from read counts in problematic genomic regions identified by the ENCODE blocklist (BL features). All features describe the same human and mouse samples from five genomic assays, allowing direct comparison of feature representations. The proposed dataset includes a binary quality label, derived from automated quality control and domain experts. Among all samples, $3.2\%$ are of low quality. Supervised machine learning algorithms accurately predicted quality labels from the features, confirming the relevance of the provided feature representations. The proposed feature representations enable researchers to study how different feature types (QC-34 vs. BL features) and granularities (varying number of BL features) affect the detection of quality problems.
Robust Statistical Scaling of Outlier Scores: Improving the Quality of Outlier Probabilities for Outliers (Extended Version)
Aug 30, 2024Outlier detection algorithms typically assign an outlier score to each observation in a dataset, indicating the degree to which an observation is an outlier. However, these scores are often not comparable across algorithms and can be difficult for humans to interpret. Statistical scaling addresses this problem by transforming outlier scores into outlier probabilities without using ground-truth labels, thereby improving interpretability and comparability across algorithms. However, the quality of this transformation can be different for outliers and inliers. Missing outliers in scenarios where they are of particular interest - such as healthcare, finance, or engineering - can be costly or dangerous. Thus, ensuring good probabilities for outliers is essential. This paper argues that statistical scaling, as commonly used in the literature, does not produce equally good probabilities for outliers as for inliers. Therefore, we propose robust statistical scaling, which uses robust estimators to improve the probabilities for outliers. We evaluate several variants of our method against other outlier score transformations for real-world datasets and outlier detection algorithms, where it can improve the probabilities for outliers.
MTGP: Combining Metamorphic Testing and Genetic Programming
Jan 20, 2023
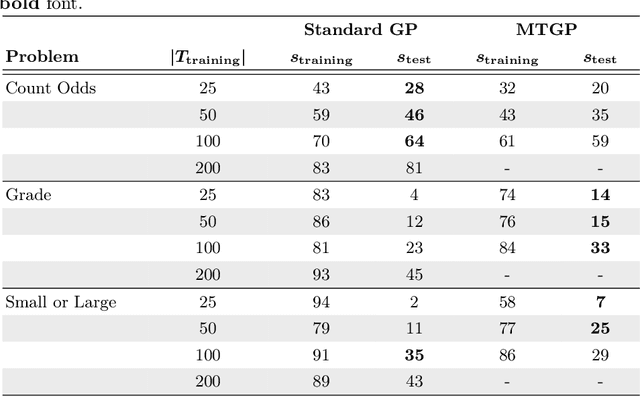
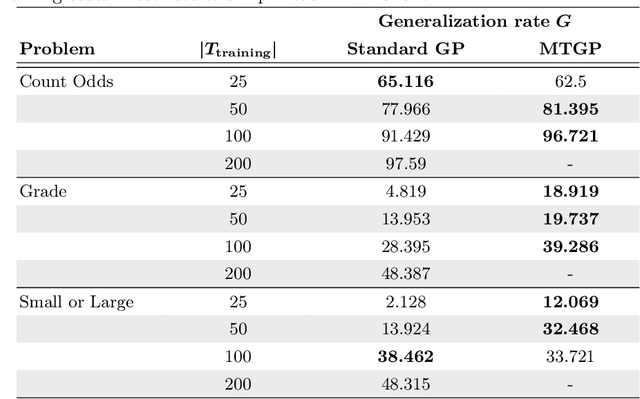
Genetic programming is an evolutionary approach known for its performance in program synthesis. However, it is not yet mature enough for a practical use in real-world software development, since usually many training cases are required to generate programs that generalize to unseen test cases. As in practice, the training cases have to be expensively hand-labeled by the user, we need an approach to check the program behavior with a lower number of training cases. Metamorphic testing needs no labeled input/output examples. Instead, the program is executed multiple times, first on a given (randomly generated) input, followed by related inputs to check whether certain user-defined relations between the observed outputs hold. In this work, we suggest MTGP, which combines metamorphic testing and genetic programming and study its performance and the generalizability of the generated programs. Further, we analyze how the generalizability depends on the number of given labeled training cases. We find that using metamorphic testing combined with labeled training cases leads to a higher generalization rate than the use of labeled training cases alone in almost all studied configurations. Consequently, we recommend researchers to use metamorphic testing in their systems if the labeling of the training data is expensive.