 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS: Magnitude-Aware Rank Statistics
May 22, 2026Comprehensive evaluation of machine learning models is the key to make sure that they perform as robustly and consistently as desired. In order to summarize the experimental results and pick a winner, Critical Difference (CD) diagrams are used. Standard CD diagrams rely on discrete ranks, discarding the magnitude of performance gaps between models, raising an issue which we call magnitude-blindness. In order to address this issue, we propose Magnitude-Aware Rank Statistics (MARS) that incorporates a relative margin coefficient as a weight for the discrete ranks. This coefficient scales ranks based on the distance between the best and worst performers, with a dynamic projection to handle boundary cases. Followed by the calculation of a CD value, MARS results in a more realistic statistical representation of differences of model performances and more insights on how methods actually perform in vast and extensive experimental settings.
Worse than Random: The Importance of a Baseline for Unsupervised Feature Selection
May 21, 2026Many novel unsupervised feature selection methods are proposed each year, yet their empirical evaluation is limited to supervised and unsupervised evaluation metrics computed on selected datasets, along with comparisons to existing methods. However, in the absence of an established evaluation baseline, it is difficult to determine the value added to the existing literature by each of these methods, and how effective their underlying approaches are. We propose using random feature selection as a baseline for evaluating the unsupervised feature selection methods. We empirically show that many of the state-of-the-art methods in unsupervised feature selection are outperformed by random feature selection in both performance and efficiency. Accordingly, we emphasize on the strict requirement of considering random feature selection as a baseline in the development process of novel unsupervised feature selection methods to ensure a consistent improvement over random feature selection.
FSEVAL: Feature Selection Evaluation Toolbox and Dashboard
Apr 20, 2026Feature selection is a fundamental machine learning and data mining task, involved with discriminating redundant features from informative ones. It is an attempt to address the curse of dimensionality by removing the redundant features, while unlike dimensionality reduction methods, preserving explainability. Feature selection is conducted in both supervised and unsupervised settings, with different evaluation metrics employed to determine which feature selection algorithm is the best. In this paper, we propose FSEVAL, a feature selection evaluation toolbox accompanied with a visualization dashboard, with the goal to make it easy to comprehensively evaluate feature selection algorithms. FSEVAL aims to provide a standardized, unified, evaluation and visualization toolbox to help the researchers working in the field, conduct extensive and comprehensive evaluation of feature selection algorithms with ease.
DCFO: Density-Based Counterfactuals for Outliers - Additional Material
Dec 18, 2025Outlier detection identifies data points that significantly deviate from the majority of the data distribution. Explaining outliers is crucial for understanding the underlying factors that contribute to their detection, validating their significance, and identifying potential biases or errors. Effective explanations provide actionable insights, facilitating preventive measures to avoid similar outliers in the future. Counterfactual explanations clarify why specific data points are classified as outliers by identifying minimal changes required to alter their prediction. Although valuable, most existing counterfactual explanation methods overlook the unique challenges posed by outlier detection, and fail to target classical, widely adopted outlier detection algorithms. Local Outlier Factor (LOF) is one the most popular unsupervised outlier detection methods, quantifying outlierness through relative local density. Despite LOF's widespread use across diverse applications, it lacks interpretability. To address this limitation, we introduce Density-based Counterfactuals for Outliers (DCFO), a novel method specifically designed to generate counterfactual explanations for LOF. DCFO partitions the data space into regions where LOF behaves smoothly, enabling efficient gradient-based optimisation. Extensive experimental validation on 50 OpenML datasets demonstrates that DCFO consistently outperforms benchmarked competitors, offering superior proximity and validity of generated counterfactuals.
Achieving Hilbert-Schmidt Independence Under Rényi Differential Privacy for Fair and Private Data Generation
Aug 29, 2025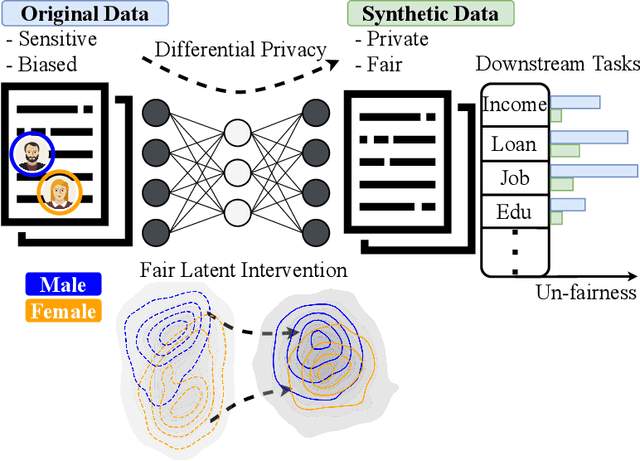
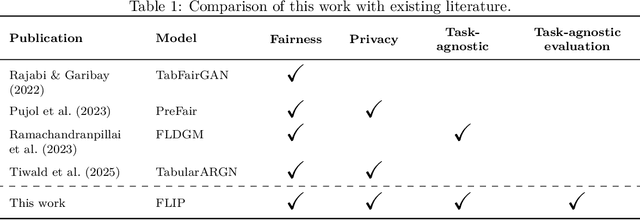
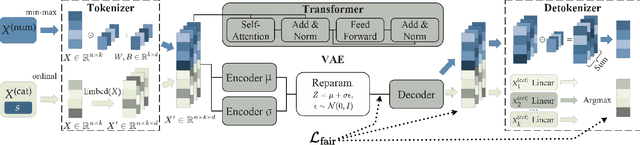

As privacy regulations such as the GDPR and HIPAA and responsibility frameworks for artificial intelligence such as the AI Act gain traction, the ethical and responsible use of real-world data faces increasing constraints. Synthetic data generation has emerged as a promising solution to risk-aware data sharing and model development, particularly for tabular datasets that are foundational to sensitive domains such as healthcare. To address both privacy and fairness concerns in this setting, we propose FLIP (Fair Latent Intervention under Privacy guarantees), a transformer-based variational autoencoder augmented with latent diffusion to generate heterogeneous tabular data. Unlike the typical setup in fairness-aware data generation, we assume a task-agnostic setup, not reliant on a fixed, defined downstream task, thus offering broader applicability. To ensure privacy, FLIP employs R\'enyi differential privacy (RDP) constraints during training and addresses fairness in the input space with RDP-compatible balanced sampling that accounts for group-specific noise levels across multiple sampling rates. In the latent space, we promote fairness by aligning neuron activation patterns across protected groups using Centered Kernel Alignment (CKA), a similarity measure extending the Hilbert-Schmidt Independence Criterion (HSIC). This alignment encourages statistical independence between latent representations and the protected feature. Empirical results demonstrate that FLIP effectively provides significant fairness improvements for task-agnostic fairness and across diverse downstream tasks under differential privacy constraints.
Metrics for Inter-Dataset Similarity with Example Applications in Synthetic Data and Feature Selection Evaluation -- Extended Version
Jan 16, 2025



Measuring inter-dataset similarity is an important task in machine learning and data mining with various use cases and applications. Existing methods for measuring inter-dataset similarity are computationally expensive, limited, or sensitive to different entities and non-trivial choices for parameters. They also lack a holistic perspective on the entire dataset. In this paper, we propose two novel metrics for measuring inter-dataset similarity. We discuss the mathematical foundation and the theoretical basis of our proposed metrics. We demonstrate the effectiveness of the proposed metrics by investigating two applications in the evaluation of synthetic data and in the evaluation of feature selection methods. The theoretical and empirical studies conducted in this paper illustrate the effectiveness of the proposed metrics.
Transparent Neighborhood Approximation for Text Classifier Explanation
Nov 25, 2024



Recent literature highlights the critical role of neighborhood construction in deriving model-agnostic explanations, with a growing trend toward deploying generative models to improve synthetic instance quality, especially for explaining text classifiers. These approaches overcome the challenges in neighborhood construction posed by the unstructured nature of texts, thereby improving the quality of explanations. However, the deployed generators are usually implemented via neural networks and lack inherent explainability, sparking arguments over the transparency of the explanation process itself. To address this limitation while preserving neighborhood quality, this paper introduces a probability-based editing method as an alternative to black-box text generators. This approach generates neighboring texts by implementing manipulations based on in-text contexts. Substituting the generator-based construction process with recursive probability-based editing, the resultant explanation method, XPROB (explainer with probability-based editing), exhibits competitive performance according to the evaluation conducted on two real-world datasets. Additionally, XPROB's fully transparent and more controllable construction process leads to superior stability compared to the generator-based explainers.
Robust Statistical Scaling of Outlier Scores: Improving the Quality of Outlier Probabilities for Outliers (Extended Version)
Aug 30, 2024Outlier detection algorithms typically assign an outlier score to each observation in a dataset, indicating the degree to which an observation is an outlier. However, these scores are often not comparable across algorithms and can be difficult for humans to interpret. Statistical scaling addresses this problem by transforming outlier scores into outlier probabilities without using ground-truth labels, thereby improving interpretability and comparability across algorithms. However, the quality of this transformation can be different for outliers and inliers. Missing outliers in scenarios where they are of particular interest - such as healthcare, finance, or engineering - can be costly or dangerous. Thus, ensuring good probabilities for outliers is essential. This paper argues that statistical scaling, as commonly used in the literature, does not produce equally good probabilities for outliers as for inliers. Therefore, we propose robust statistical scaling, which uses robust estimators to improve the probabilities for outliers. We evaluate several variants of our method against other outlier score transformations for real-world datasets and outlier detection algorithms, where it can improve the probabilities for outliers.
FSDEM: Feature Selection Dynamic Evaluation Metric
Aug 26, 2024Expressive evaluation metrics are indispensable for informative experiments in all areas, and while several metrics are established in some areas, in others, such as feature selection, only indirect or otherwise limited evaluation metrics are found. In this paper, we propose a novel evaluation metric to address several problems of its predecessors and allow for flexible and reliable evaluation of feature selection algorithms. The proposed metric is a dynamic metric with two properties that can be used to evaluate both the performance and the stability of a feature selection algorithm. We conduct several empirical experiments to illustrate the use of the proposed metric in the successful evaluation of feature selection algorithms. We also provide a comparison and analysis to show the different aspects involved in the evaluation of the feature selection algorithms. The results indicate that the proposed metric is successful in carrying out the evaluation task for feature selection algorithms. This paper is an extended version of a paper accepted at SISAP 2024.
SynthEval: A Framework for Detailed Utility and Privacy Evaluation of Tabular Synthetic Data
Apr 24, 2024With the growing demand for synthetic data to address contemporary issues in machine learning, such as data scarcity, data fairness, and data privacy, having robust tools for assessing the utility and potential privacy risks of such data becomes crucial. SynthEval, a novel open-source evaluation framework distinguishes itself from existing tools by treating categorical and numerical attributes with equal care, without assuming any special kind of preprocessing steps. This~makes it applicable to virtually any synthetic dataset of tabular records. Our tool leverages statistical and machine learning techniques to comprehensively evaluate synthetic data fidelity and privacy-preserving integrity. SynthEval integrates a wide selection of metrics that can be used independently or in highly customisable benchmark configurations, and can easily be extended with additional metrics. In this paper, we describe SynthEval and illustrate its versatility with examples. The framework facilitates better benchmarking and more consistent comparisons of model capabilities.