 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALIGN-FL: Architecture-independent Learning through Invariant Generative component sharing in Federated Learning
Dec 15, 2025



We present ALIGN-FL, a novel approach to distributed learning that addresses the challenge of learning from highly disjoint data distributions through selective sharing of generative components. Instead of exchanging full model parameters, our framework enables privacy-preserving learning by transferring only generative capabilities across clients, while the server performs global training using synthetic samples. Through complementary privacy mechanisms: DP-SGD with adaptive clipping and Lipschitz regularized VAE decoders and a stateful architecture supporting heterogeneous clients, we experimentally validate our approach on MNIST and Fashion-MNIST datasets with cross-domain outliers. Our analysis demonstrates that both privacy mechanisms effectively map sensitive outliers to typical data points while maintaining utility in extreme Non-IID scenarios typical of cross-silo collaborations. Index Terms: Client-invariant Learning, Federated Learning (FL), Privacy-preserving Generative Models, Non-Independent and Identically Distributed (Non-IID), Heterogeneous Architectures
Rethinking Explanation Evaluation under the Retraining Scheme
Nov 11, 2025



Feature attribution has gained prominence as a tool for explaining model decisions, yet evaluating explanation quality remains challenging due to the absence of ground-truth explanations. To circumvent this, explanation-guided input manipulation has emerged as an indirect evaluation strategy, measuring explanation effectiveness through the impact of input modifications on model outcomes during inference. Despite the widespread use, a major concern with inference-based schemes is the distribution shift caused by such manipulations, which undermines the reliability of their assessments. The retraining-based scheme ROAR overcomes this issue by adapting the model to the altered data distribution. However, its evaluation results often contradict the theoretical foundations of widely accepted explainers. This work investigates this misalignment between empirical observations and theoretical expectations. In particular, we identify the sign issue as a key factor responsible for residual information that ultimately distorts retraining-based evaluation. Based on the analysis, we show that a straightforward reframing of the evaluation process can effectively resolve the identified issue. Building on the existing framework, we further propose novel variants that jointly structure a comprehensive perspective on explanation evaluation. These variants largely improve evaluation efficiency over the standard retraining protocol, thereby enhancing practical applicability for explainer selection and benchmarking. Following our proposed schemes, empirical results across various data scales provide deeper insights into the performance of carefully selected explainers, revealing open challenges and future directions in explainability research.
Tracking UWB Devices Through Radio Frequency Fingerprinting Is Possible
Jan 08, 2025Ultra-wideband (UWB) is a state-of-the-art technology designed for applications requiring centimeter-level localization. Its widespread adoption by smartphone manufacturer naturally raises security and privacy concerns. Successfully implementing Radio Frequency Fingerprinting (RFF) to UWB could enable physical layer security, but might also allow undesired tracking of the devices. The scope of this paper is to explore the feasibility of applying RFF to UWB and investigates how well this technique generalizes across different environments. We collected a realistic dataset using off-the-shelf UWB devices with controlled variation in device positioning. Moreover, we developed an improved deep learning pipeline to extract the hardware signature from the signal data. In stable conditions, the extracted RFF achieves over 99% accuracy. While the accuracy decreases in more changing environments, we still obtain up to 76% accuracy in untrained locations.
Transparent Neighborhood Approximation for Text Classifier Explanation
Nov 25, 2024



Recent literature highlights the critical role of neighborhood construction in deriving model-agnostic explanations, with a growing trend toward deploying generative models to improve synthetic instance quality, especially for explaining text classifiers. These approaches overcome the challenges in neighborhood construction posed by the unstructured nature of texts, thereby improving the quality of explanations. However, the deployed generators are usually implemented via neural networks and lack inherent explainability, sparking arguments over the transparency of the explanation process itself. To address this limitation while preserving neighborhood quality, this paper introduces a probability-based editing method as an alternative to black-box text generators. This approach generates neighboring texts by implementing manipulations based on in-text contexts. Substituting the generator-based construction process with recursive probability-based editing, the resultant explanation method, XPROB (explainer with probability-based editing), exhibits competitive performance according to the evaluation conducted on two real-world datasets. Additionally, XPROB's fully transparent and more controllable construction process leads to superior stability compared to the generator-based explainers.
On Gradient-like Explanation under a Black-box Setting: When Black-box Explanations Become as Good as White-box
Aug 18, 2023Attribution methods shed light on the explainability of data-driven approaches such as deep learning models by revealing the most contributing features to decisions that have been made. A widely accepted way of deriving feature attributions is to analyze the gradients of the target function with respect to input features. Analysis of gradients requires full access to the target system, meaning that solutions of this kind treat the target system as a white-box. However, the white-box assumption may be untenable due to security and safety concerns, thus limiting their practical applications. As an answer to the limited flexibility, this paper presents GEEX (gradient-estimation-based explanation), an explanation method that delivers gradient-like explanations under a black-box setting. Furthermore, we integrate the proposed method with a path method. The resulting approach iGEEX (integrated GEEX) satisfies the four fundamental axioms of attribution methods: sensitivity, insensitivity, implementation invariance, and linearity. With a focus on image data, the exhaustive experiments empirically show that the proposed methods outperform state-of-the-art black-box methods and achieve competitive performance compared to the ones with full access.
Differentially Private Synthetic Data Generation via Lipschitz-Regularised Variational Autoencoders
Apr 22, 2023


Synthetic data has been hailed as the silver bullet for privacy preserving data analysis. If a record is not real, then how could it violate a person's privacy? In addition, deep-learning based generative models are employed successfully to approximate complex high-dimensional distributions from data and draw realistic samples from this learned distribution. It is often overlooked though that generative models are prone to memorising many details of individual training records and often generate synthetic data that too closely resembles the underlying sensitive training data, hence violating strong privacy regulations as, e.g., encountered in health care. Differential privacy is the well-known state-of-the-art framework for guaranteeing protection of sensitive individuals' data, allowing aggregate statistics and even machine learning models to be released publicly without compromising privacy. The training mechanisms however often add too much noise during the training process, and thus severely compromise the utility of these private models. Even worse, the tight privacy budgets do not allow for many training epochs so that model quality cannot be properly controlled in practice. In this paper we explore an alternative approach for privately generating data that makes direct use of the inherent stochasticity in generative models, e.g., variational autoencoders. The main idea is to appropriately constrain the continuity modulus of the deep models instead of adding another noise mechanism on top. For this approach, we derive mathematically rigorous privacy guarantees and illustrate its effectiveness with practical experiments.
Explaining text classifiers through progressive neighborhood approximation with realistic samples
Feb 11, 2023The importance of neighborhood construction in local explanation methods has been already highlighted in the literature. And several attempts have been made to improve neighborhood quality for high-dimensional data, for example, texts, by adopting generative models. Although the generators produce more realistic samples, the intuitive sampling approaches in the existing solutions leave the latent space underexplored. To overcome this problem, our work, focusing on local model-agnostic explanations for text classifiers, proposes a progressive approximation approach that refines the neighborhood of a to-be-explained decision with a careful two-stage interpolation using counterfactuals as landmarks. We explicitly specify the two properties that should be satisfied by generative models, the reconstruction ability and the locality-preserving property, to guide the selection of generators for local explanation methods. Moreover, noticing the opacity of generative models during the study, we propose another method that implements progressive neighborhood approximation with probability-based editions as an alternative to the generator-based solution. The explanation results from both methods consist of word-level and instance-level explanations benefiting from the realistic neighborhood. Through exhaustive experiments, we qualitatively and quantitatively demonstrate the effectiveness of the two proposed methods.
One-Shot Messaging at Any Load Through Random Sub-Channeling in OFDM
Sep 22, 2022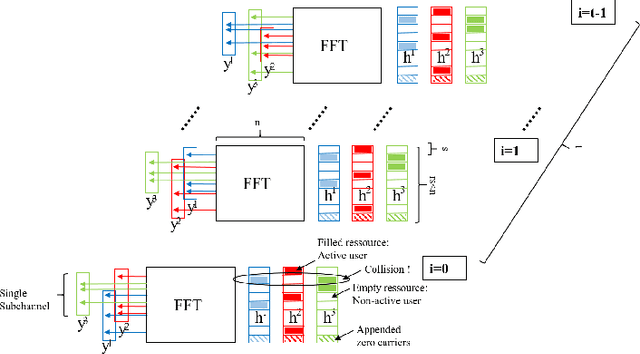
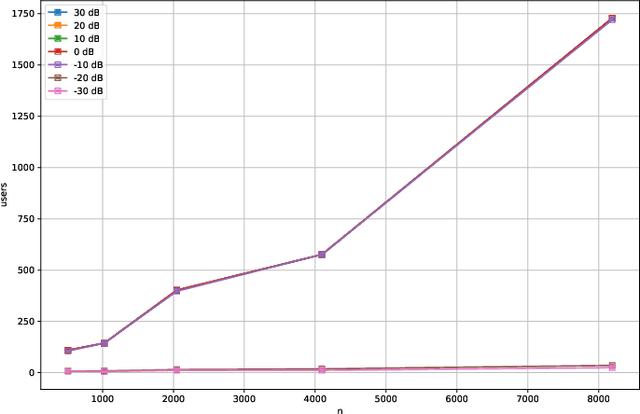
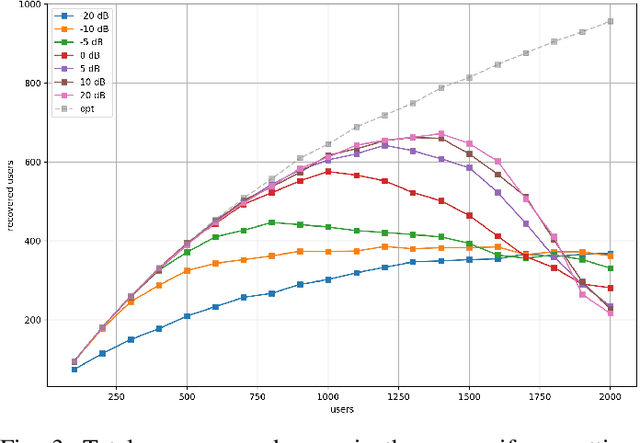
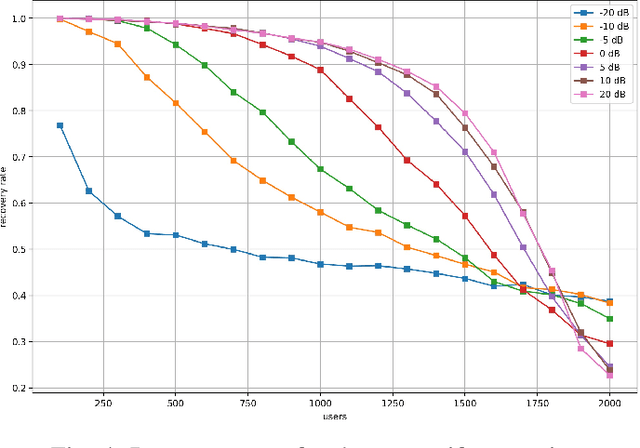
Compressive Sensing has well boosted massive random access protocols over the last decade. In this paper we apply an orthogonal FFT basis as it is used in OFDM, but subdivide its image into so-called sub-channels and let each sub-channel take only a fraction of the load. In a random fashion the subdivision is consecutively applied over a suitable number of time-slots. Within the time-slots the users will not change their sub-channel assignment and send in parallel the data. Activity detection is carried out jointly across time-slots in each of the sub-channels. For such system design we derive three rather fundamental results: i) First, we prove that the subdivision can be driven to the extent that the activity in each sub-channel is sparse by design. An effect that we call sparsity capture effect. ii) Second, we prove that effectively the system can sustain any overload situation relative to the FFT dimension, i.e. detection failure of active and non-active users can be kept below any desired threshold regardless of the number of users. The only price to pay is delay, i.e. the number of time-slots over which cross-detection is performed. We achieve this by jointly exploring the effect of measure concentration in time and frequency and careful system parameter scaling. iii) Third, we prove that parallel to activity detection active users can carry one symbol per pilot resource and time-slot so it supports so-called one-shot messaging. The key to proving these results are new concentration results for sequences of randomly sub-sampled FFTs detecting the sparse vectors "en bloc". Eventually, we show by simulations that the system is scalable resulting in a coarsely 30-fold capacity increase compared to standard OFDM.
Power of Explanations: Towards automatic debiasing in hate speech detection
Sep 07, 2022



Hate speech detection is a common downstream application of natural language processing (NLP) in the real world. In spite of the increasing accuracy, current data-driven approaches could easily learn biases from the imbalanced data distributions originating from humans. The deployment of biased models could further enhance the existing social biases. But unlike handling tabular data, defining and mitigating biases in text classifiers, which deal with unstructured data, are more challenging. A popular solution for improving machine learning fairness in NLP is to conduct the debiasing process with a list of potentially discriminated words given by human annotators. In addition to suffering from the risks of overlooking the biased terms, exhaustively identifying bias with human annotators are unsustainable since discrimination is variable among different datasets and may evolve over time. To this end, we propose an automatic misuse detector (MiD) relying on an explanation method for detecting potential bias. And built upon that, an end-to-end debiasing framework with the proposed staged correction is designed for text classifiers without any external resources required.
A Reverse Jensen Inequality Result with Application to Mutual Information Estimation
Nov 12, 2021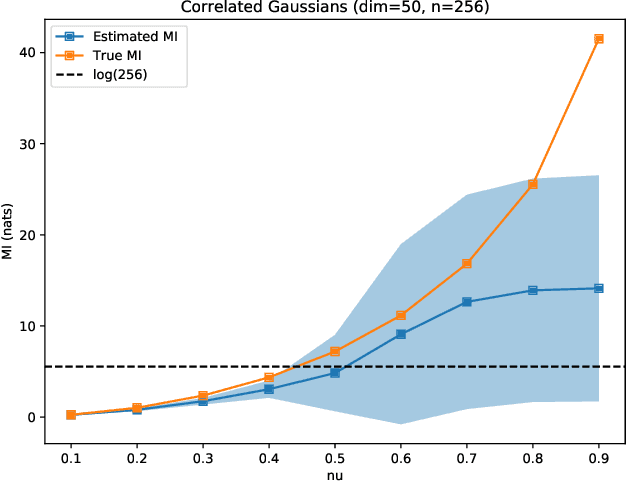
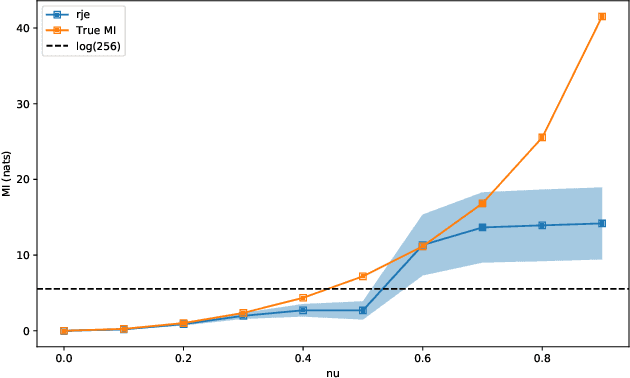
The Jensen inequality is a widely used tool in a multitude of fields, such as for example information theory and machine learning. It can be also used to derive other standard inequalities such as the inequality of arithmetic and geometric means or the H\"older inequality. In a probabilistic setting, the Jensen inequality describes the relationship between a convex function and the expected value. In this work, we want to look at the probabilistic setting from the reverse direction of the inequality. We show that under minimal constraints and with a proper scaling, the Jensen inequality can be reversed. We believe that the resulting tool can be helpful for many applications and provide a variational estimation of mutual information, where the reverse inequality leads to a new estimator with superior training behavior compared to current estimators.