 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use of Bagging for Local Intrinsic Dimensionality Estimation
Mar 25, 2026The theory of Local Intrinsic Dimensionality (LID) has become a valuable tool for characterizing local complexity within and across data manifolds, supporting a range of data mining and machine learning tasks. Accurate LID estimation requires samples drawn from small neighborhoods around each query to avoid biases from nonlocal effects and potential manifold mixing, yet limited data within such neighborhoods tends to cause high estimation variance. As a variance reduction strategy, we propose an ensemble approach that uses subbagging to preserve the local distribution of nearest neighbor (NN) distances. The main challenge is that the uniform reduction in total sample size within each subsample increases the proximity threshold for finding a fixed number k of NNs around the query. As a result, in the specific context of LID estimation, the sampling rate has an additional, complex interplay with the neighborhood size, where both combined determine the sample size as well as the locality and resolution considered for estimation. We analyze both theoretically and experimentally how the choice of the sampling rate and the k-NN size used for LID estimation, alongside the ensemble size, affects performance, enabling informed prior selection of these hyper-parameters depending on application-based preferences. Our results indicate that within broad and well-characterized regions of the hyper-parameters space, using a bagged estimator will most often significantly reduce variance as well as the mean squared error when compared to the corresponding non-bagged baseline, with controllable impact on bias. We additionally propose and evaluate different ways of combining bagging with neighborhood smoothing for substantial further improvements on LID estimation performance.
Attention in Space: Functional Roles of VLM Heads for Spatial Reasoning
Mar 21, 2026Despite remarkable advances in large Vision-Language Models (VLMs), spatial reasoning remains a persistent challenge. In this work, we investigate how attention heads within VLMs contribute to spatial reasoning by analyzing their functional roles through a mechanistic interpretability lens. We introduce CogVSR, a dataset that decomposes complex spatial reasoning questions into step-by-step subquestions designed to simulate human-like reasoning via a chain-of-thought paradigm, with each subquestion linked to specific cognitive functions such as spatial perception or relational reasoning. Building on CogVSR, we develop a probing framework to identify and characterize attention heads specialized for these functions. Our analysis across diverse VLM families reveals that these functional heads are universally sparse, vary in number and distribution across functions. Notably, spatially specialized heads are fewer than those for other cognitive functions, highlighting their scarcity. We propose methods to activate latent spatial heads, improving spatial understanding. Intervention experiments further demonstrate their critical role in spatial reasoning: removing functional heads leads to performance degradation, while emphasizing them enhances accuracy. This study provides new interpretability driven insights into how VLMs attend to space and paves the way for enhancing complex spatial reasoning in multimodal models.
CoCoEmo: Composable and Controllable Human-Like Emotional TTS via Activation Steering
Feb 03, 2026Emotional expression in human speech is nuanced and compositional, often involving multiple, sometimes conflicting, affective cues that may diverge from linguistic content. In contrast, most expressive text-to-speech systems enforce a single utterance-level emotion, collapsing affective diversity and suppressing mixed or text-emotion-misaligned expression. While activation steering via latent direction vectors offers a promising solution, it remains unclear whether emotion representations are linearly steerable in TTS, where steering should be applied within hybrid TTS architectures, and how such complex emotion behaviors should be evaluated. This paper presents the first systematic analysis of activation steering for emotional control in hybrid TTS models, introducing a quantitative, controllable steering framework, and multi-rater evaluation protocols that enable composable mixed-emotion synthesis and reliable text-emotion mismatch synthesis. Our results demonstrate, for the first time, that emotional prosody and expressive variability are primarily synthesized by the TTS language module instead of the flow-matching module, and also provide a lightweight steering approach for generating natural, human-like emotional speech.
Local Intrinsic Dimensionality of Ground Motion Data for Early Detection of Complex Catastrophic Slope Failure
Jan 07, 2026Local Intrinsic Dimensionality (LID) has shown strong potential for identifying anomalies and outliers in high-dimensional data across a wide range of real-world applications, including landslide failure detection in granular media. Early and accurate identification of failure zones in landslide-prone areas is crucial for effective geohazard mitigation. While existing approaches typically rely on surface displacement data analyzed through statistical or machine learning techniques, they often fall short in capturing both the spatial correlations and temporal dynamics that are inherent in such data. To address this gap, we focus on ground-monitored landslides and introduce a novel approach that jointly incorporates spatial and temporal information, enabling the detection of complex landslides and including multiple successive failures occurring in distinct areas of the same slope. To be specific, our method builds upon an existing LID-based technique, known as sLID. We extend its capabilities in three key ways. (1) Kinematic enhancement: we incorporate velocity into the sLID computation to better capture short-term temporal dependencies and deformation rate relationships. (2) Spatial fusion: we apply Bayesian estimation to aggregate sLID values across spatial neighborhoods, effectively embedding spatial correlations into the LID scores. (3) Temporal modeling: we introduce a temporal variant, tLID, that learns long-term dynamics from time series data, providing a robust temporal representation of displacement behavior. Finally, we integrate both components into a unified framework, referred to as spatiotemporal LID (stLID), to identify samples that are anomalous in either or both dimensions. Extensive experiments show that stLID consistently outperforms existing methods in failure detection precision and lead-time.
Coarse-to-Fine Open-Set Graph Node Classification with Large Language Models
Dec 21, 2025
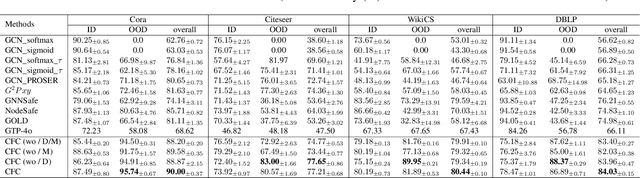

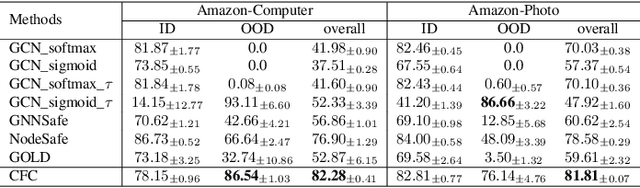
Developing open-set classification methods capable of classifying in-distribution (ID) data while detecting out-of-distribution (OOD) samples is essential for deploying graph neural networks (GNNs) in open-world scenarios. Existing methods typically treat all OOD samples as a single class, despite real-world applications, especially high-stake settings such as fraud detection and medical diagnosis, demanding deeper insights into OOD samples, including their probable labels. This raises a critical question: can OOD detection be extended to OOD classification without true label information? To address this question, we propose a Coarse-to-Fine open-set Classification (CFC) framework that leverages large language models (LLMs) for graph datasets. CFC consists of three key components: a coarse classifier that uses LLM prompts for OOD detection and outlier label generation, a GNN-based fine classifier trained with OOD samples identified by the coarse classifier for enhanced OOD detection and ID classification, and refined OOD classification achieved through LLM prompts and post-processed OOD labels. Unlike methods that rely on synthetic or auxiliary OOD samples, CFC employs semantic OOD instances that are genuinely out-of-distribution based on their inherent meaning, improving interpretability and practical utility. Experimental results show that CFC improves OOD detection by ten percent over state-of-the-art methods on graph and text domains and achieves up to seventy percent accuracy in OOD classification on graph datasets.
DynaPURLS: Dynamic Refinement of Part-aware Representations for Skeleton-based Zero-Shot Action Recognition
Dec 12, 2025Zero-shot skeleton-based action recognition (ZS-SAR) is fundamentally constrained by prevailing approaches that rely on aligning skeleton features with static, class-level semantics. This coarse-grained alignment fails to bridge the domain shift between seen and unseen classes, thereby impeding the effective transfer of fine-grained visual knowledge. To address these limitations, we introduce \textbf{DynaPURLS}, a unified framework that establishes robust, multi-scale visual-semantic correspondences and dynamically refines them at inference time to enhance generalization. Our framework leverages a large language model to generate hierarchical textual descriptions that encompass both global movements and local body-part dynamics. Concurrently, an adaptive partitioning module produces fine-grained visual representations by semantically grouping skeleton joints. To fortify this fine-grained alignment against the train-test domain shift, DynaPURLS incorporates a dynamic refinement module. During inference, this module adapts textual features to the incoming visual stream via a lightweight learnable projection. This refinement process is stabilized by a confidence-aware, class-balanced memory bank, which mitigates error propagation from noisy pseudo-labels. Extensive experiments on three large-scale benchmark datasets, including NTU RGB+D 60/120 and PKU-MMD, demonstrate that DynaPURLS significantly outperforms prior art, setting new state-of-the-art records. The source code is made publicly available at https://github.com/Alchemist0754/DynaPURLS
Investigating The Functional Roles of Attention Heads in Vision Language Models: Evidence for Reasoning Modules
Dec 11, 2025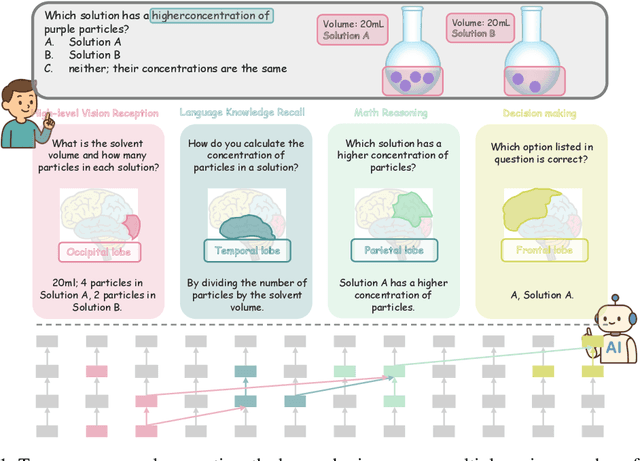
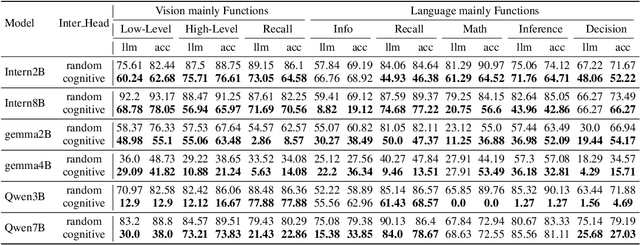
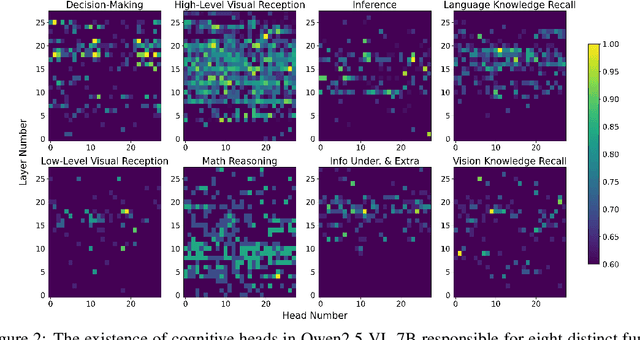

Despite excelling on multimodal benchmarks, vision-language models (VLMs) largely remain a black box. In this paper, we propose a novel interpretability framework to systematically analyze the internal mechanisms of VLMs, focusing on the functional roles of attention heads in multimodal reasoning. To this end, we introduce CogVision, a dataset that decomposes complex multimodal questions into step-by-step subquestions designed to simulate human reasoning through a chain-of-thought paradigm, with each subquestion associated with specific receptive or cognitive functions such as high-level visual reception and inference. Using a probing-based methodology, we identify attention heads that specialize in these functions and characterize them as functional heads. Our analysis across diverse VLM families reveals that these functional heads are universally sparse, vary in number and distribution across functions, and mediate interactions and hierarchical organization. Furthermore, intervention experiments demonstrate their critical role in multimodal reasoning: removing functional heads leads to performance degradation, while emphasizing them enhances accuracy. These findings provide new insights into the cognitive organization of VLMs and suggest promising directions for designing models with more human-aligned perceptual and reasoning abilities.
E-BATS: Efficient Backpropagation-Free Test-Time Adaptation for Speech Foundation Models
Jun 08, 2025



Speech Foundation Models encounter significant performance degradation when deployed in real-world scenarios involving acoustic domain shifts, such as background noise and speaker accents. Test-time adaptation (TTA) has recently emerged as a viable strategy to address such domain shifts at inference time without requiring access to source data or labels. However, existing TTA approaches, particularly those relying on backpropagation, are memory-intensive, limiting their applicability in speech tasks and resource-constrained settings. Although backpropagation-free methods offer improved efficiency, existing ones exhibit poor accuracy. This is because they are predominantly developed for vision tasks, which fundamentally differ from speech task formulations, noise characteristics, and model architecture, posing unique transferability challenges. In this paper, we introduce E-BATS, the first Efficient BAckpropagation-free TTA framework designed explicitly for speech foundation models. E-BATS achieves a balance between adaptation effectiveness and memory efficiency through three key components: (i) lightweight prompt adaptation for a forward-pass-based feature alignment, (ii) a multi-scale loss to capture both global (utterance-level) and local distribution shifts (token-level) and (iii) a test-time exponential moving average mechanism for stable adaptation across utterances. Experiments conducted on four noisy speech datasets spanning sixteen acoustic conditions demonstrate consistent improvements, with 4.1%-13.5% accuracy gains over backpropagation-free baselines and 2.0-6.4 times GPU memory savings compared to backpropagation-based methods. By enabling scalable and robust adaptation under acoustic variability, this work paves the way for developing more efficient adaptation approaches for practical speech processing systems in real-world environments.
X-Transfer Attacks: Towards Super Transferable Adversarial Attacks on CLIP
May 08, 2025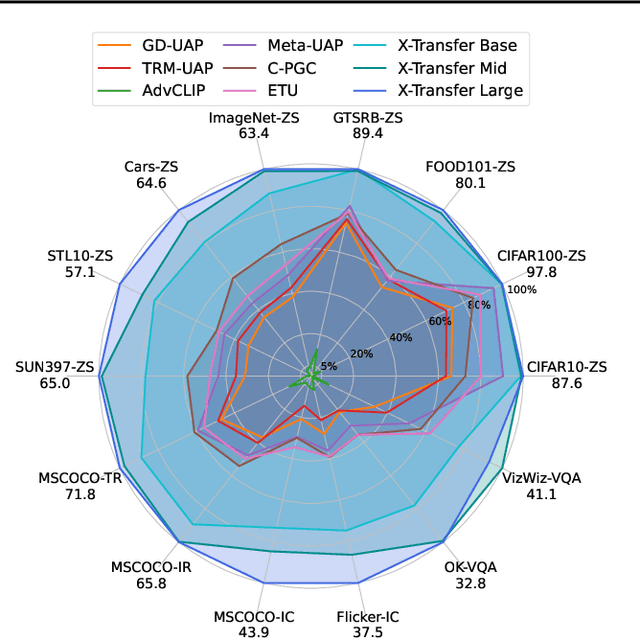
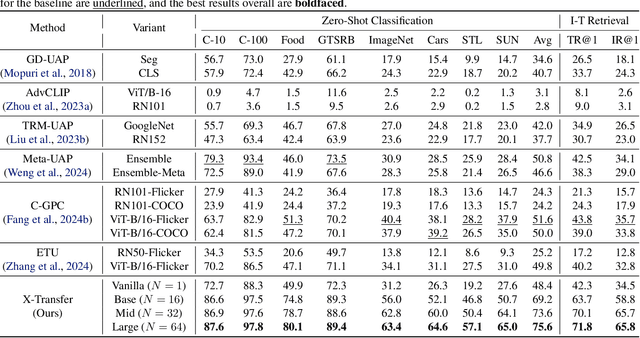
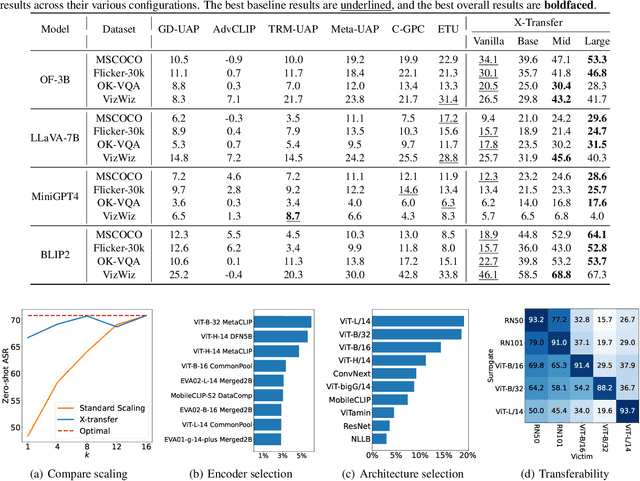

As Contrastive Language-Image Pre-training (CLIP) models are increasingly adopted for diverse downstream tasks and integrated into large vision-language models (VLMs), their susceptibility to adversarial perturbations has emerged as a critical concern. In this work, we introduce \textbf{X-Transfer}, a novel attack method that exposes a universal adversarial vulnerability in CLIP. X-Transfer generates a Universal Adversarial Perturbation (UAP) capable of deceiving various CLIP encoders and downstream VLMs across different samples, tasks, and domains. We refer to this property as \textbf{super transferability}--a single perturbation achieving cross-data, cross-domain, cross-model, and cross-task adversarial transferability simultaneously. This is achieved through \textbf{surrogate scaling}, a key innovation of our approach. Unlike existing methods that rely on fixed surrogate models, which are computationally intensive to scale, X-Transfer employs an efficient surrogate scaling strategy that dynamically selects a small subset of suitable surrogates from a large search space. Extensive evaluations demonstrate that X-Transfer significantly outperforms previous state-of-the-art UAP methods, establishing a new benchmark for adversarial transferability across CLIP models. The code is publicly available in our \href{https://github.com/HanxunH/XTransferBench}{GitHub repository}.
Parsimonious Dataset Construction for Laparoscopic Cholecystectomy Structure Segmentation
Apr 17, 2025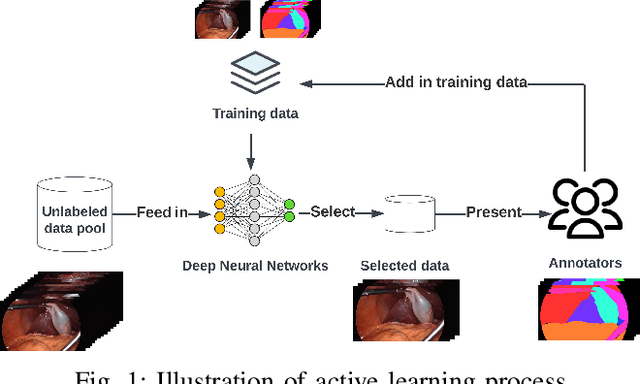
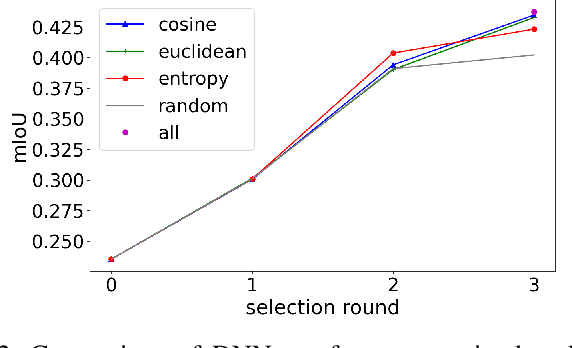
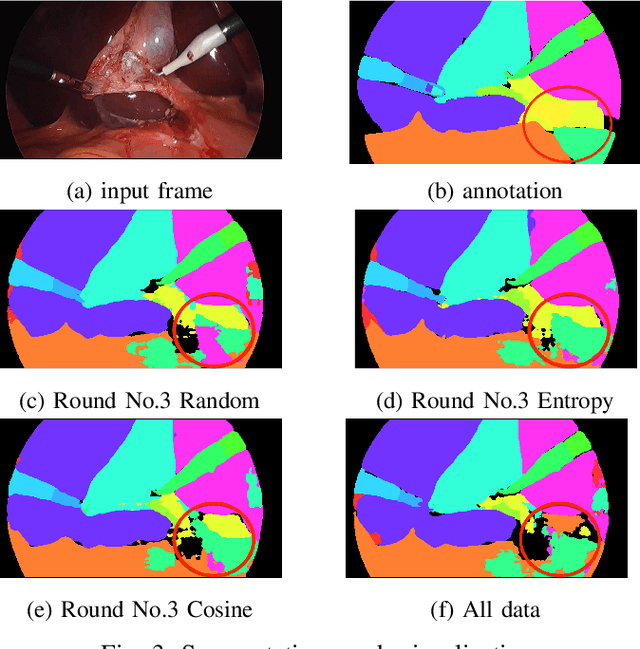
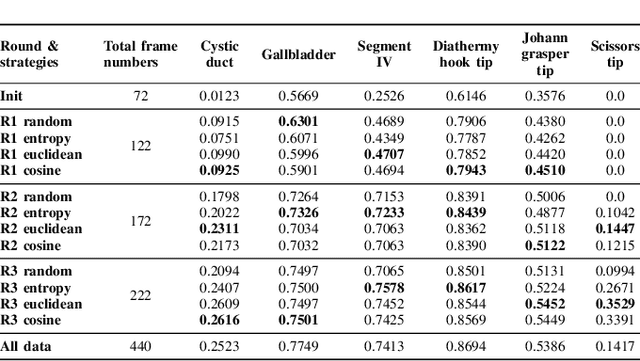
Labeling has always been expensive in the medical context, which has hindered related deep learning application. Our work introduces active learning in surgical video frame selection to construct a high-quality, affordable Laparoscopic Cholecystectomy dataset for semantic segmentation. Active learning allows the Deep Neural Networks (DNNs) learning pipeline to include the dataset construction workflow, which means DNNs trained by existing dataset will identify the most informative data from the newly collected data. At the same time, DNNs' performance and generalization ability improve over time when the newly selected and annotated data are included in the training data. We assessed different data informativeness measurements and found the deep features distances select the most informative data in this task. Our experiments show that with half of the data selected by active learning, the DNNs achieve almost the same performance with 0.4349 mean Intersection over Union (mIoU) compared to the same DNNs trained on the full dataset (0.4374 mIoU) on the critical anatomies and surgical instruments.