 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Diffusion: A Diffusion Probabilistic Model for Stochastic Time Series Forecasting
Jun 05, 2024Recent innovations in diffusion probabilistic models have paved the way for significant progress in image, text and audio generation, leading to their applications in generative time series forecasting. However, leveraging such abilities to model highly stochastic time series data remains a challenge. In this paper, we propose a novel Stochastic Diffusion (StochDiff) model which learns data-driven prior knowledge at each time step by utilizing the representational power of the stochastic latent spaces to model the variability of the multivariate time series data. The learnt prior knowledge helps the model to capture complex temporal dynamics and the inherent uncertainty of the data. This improves its ability to model highly stochastic time series data. Through extensive experiments on real-world datasets, we demonstrate the effectiveness of our proposed model on stochastic time series forecasting. Additionally, we showcase an application of our model for real-world surgical guidance, highlighting its potential to benefit the medical community.
Time Series Representation Learning with Supervised Contrastive Temporal Transformer
Mar 16, 2024Finding effective representations for time series data is a useful but challenging task. Several works utilize self-supervised or unsupervised learning methods to address this. However, there still remains the open question of how to leverage available label information for better representations. To answer this question, we exploit pre-existing techniques in time series and representation learning domains and develop a simple, yet novel fusion model, called: \textbf{S}upervised \textbf{CO}ntrastive \textbf{T}emporal \textbf{T}ransformer (SCOTT). We first investigate suitable augmentation methods for various types of time series data to assist with learning change-invariant representations. Secondly, we combine Transformer and Temporal Convolutional Networks in a simple way to efficiently learn both global and local features. Finally, we simplify Supervised Contrastive Loss for representation learning of labelled time series data. We preliminarily evaluate SCOTT on a downstream task, Time Series Classification, using 45 datasets from the UCR archive. The results show that with the representations learnt by SCOTT, even a weak classifier can perform similar to or better than existing state-of-the-art models (best performance on 23/45 datasets and highest rank against 9 baseline models). Afterwards, we investigate SCOTT's ability to address a real-world task, online Change Point Detection (CPD), on two datasets: a human activity dataset and a surgical patient dataset. We show that the model performs with high reliability and efficiency on the online CPD problem ($\sim$98\% and $\sim$97\% area under precision-recall curve respectively). Furthermore, we demonstrate the model's potential in tackling early detection and show it performs best compared to other candidates.
Time-Transformer: Integrating Local and Global Features for Better Time Series Generation
Dec 18, 2023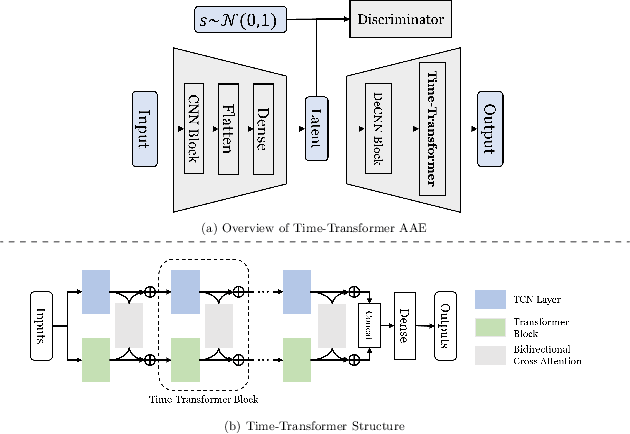

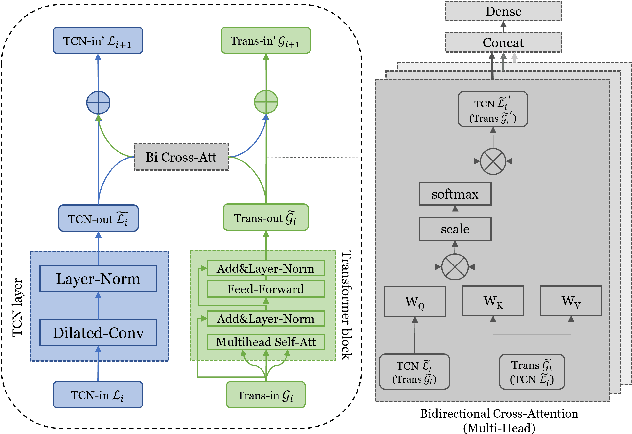

Generating time series data is a promising approach to address data deficiency problems. However, it is also challenging due to the complex temporal properties of time series data, including local correlations as well as global dependencies. Most existing generative models have failed to effectively learn both the local and global properties of time series data. To address this open problem, we propose a novel time series generative model named 'Time-Transformer AAE', which consists of an adversarial autoencoder (AAE) and a newly designed architecture named 'Time-Transformer' within the decoder. The Time-Transformer first simultaneously learns local and global features in a layer-wise parallel design, combining the abilities of Temporal Convolutional Networks and Transformer in extracting local features and global dependencies respectively. Second, a bidirectional cross attention is proposed to provide complementary guidance across the two branches and achieve proper fusion between local and global features. Experimental results demonstrate that our model can outperform existing state-of-the-art models in 5 out of 6 datasets, specifically on those with data containing both global and local properties. Furthermore, we highlight our model's advantage on handling this kind of data via an artificial dataset. Finally, we show our model's ability to address a real-world problem: data augmentation to support learning with small datasets and imbalanced datasets.
Learning Non-Unique Segmentation with Reward-Penalty Dice Loss
Sep 23, 2020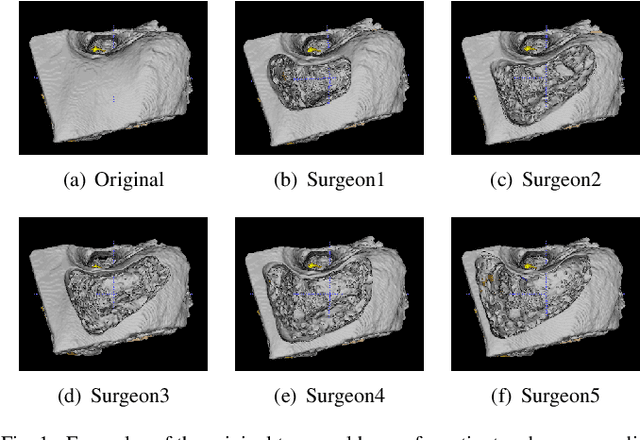
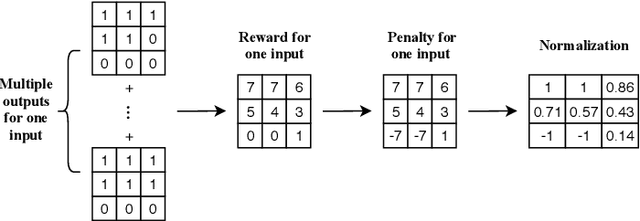
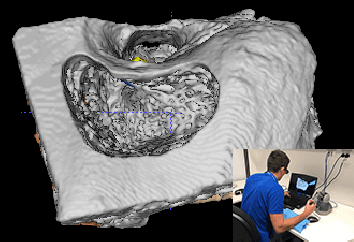

Semantic segmentation is one of the key problems in the field of computer vision, as it enables computer image understanding. However, most research and applications of semantic segmentation focus on addressing unique segmentation problems, where there is only one gold standard segmentation result for every input image. This may not be true in some problems, e.g., medical applications. We may have non-unique segmentation annotations as different surgeons may perform successful surgeries for the same patient in slightly different ways. To comprehensively learn non-unique segmentation tasks, we propose the reward-penalty Dice loss (RPDL) function as the optimization objective for deep convolutional neural networks (DCNN). RPDL is capable of helping DCNN learn non-unique segmentation by enhancing common regions and penalizing outside ones. Experimental results show that RPDL improves the performance of DCNN models by up to 18.4% compared with other loss functions on our collected surgical dataset.
Dimensionality-Driven Learning with Noisy Labels
Jul 31, 2018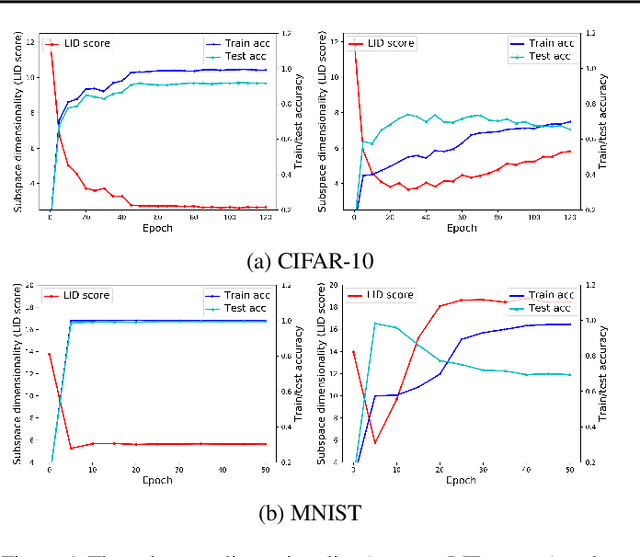
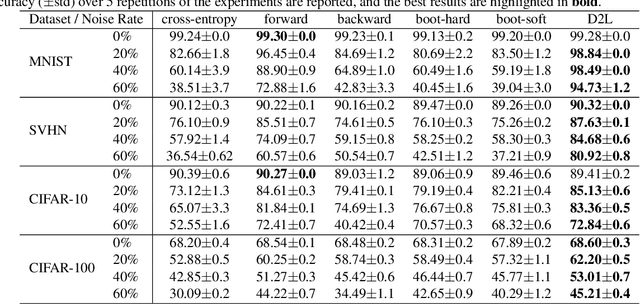
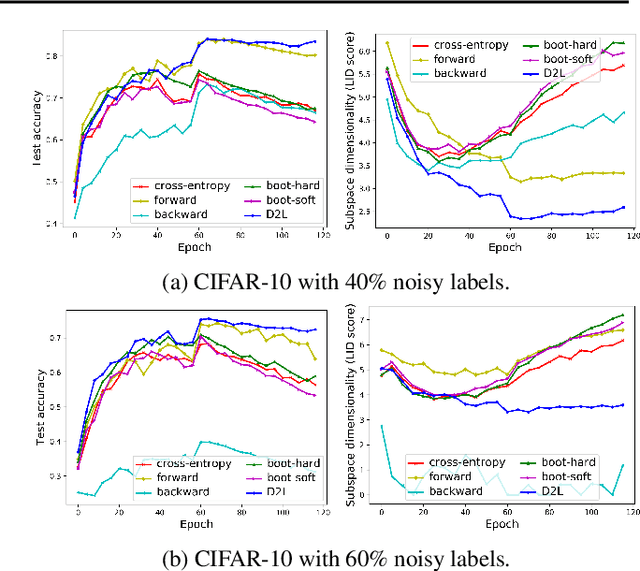
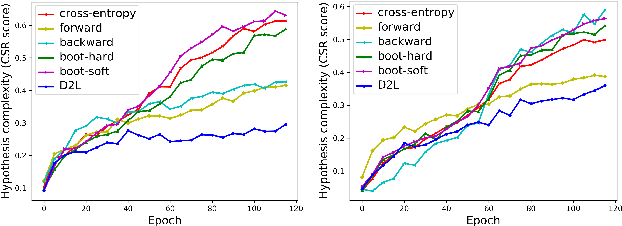
Datasets with significant proportions of noisy (incorrect) class labels present challenges for training accurate Deep Neural Networks (DNNs). We propose a new perspective for understanding DNN generalization for such datasets, by investigating the dimensionality of the deep representation subspace of training samples. We show that from a dimensionality perspective, DNNs exhibit quite distinctive learning styles when trained with clean labels versus when trained with a proportion of noisy labels. Based on this finding, we develop a new dimensionality-driven learning strategy, which monitors the dimensionality of subspaces during training and adapts the loss function accordingly. We empirically demonstrate that our approach is highly tolerant to significant proportions of noisy labels, and can effectively learn low-dimensional local subspaces that capture the data distribution.
Characterizing Adversarial Subspaces Using Local Intrinsic Dimensionality
Mar 14, 2018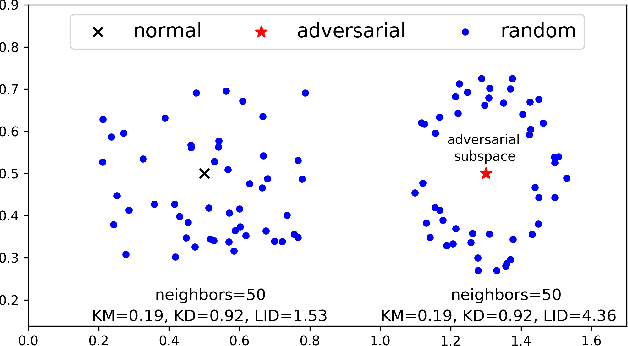
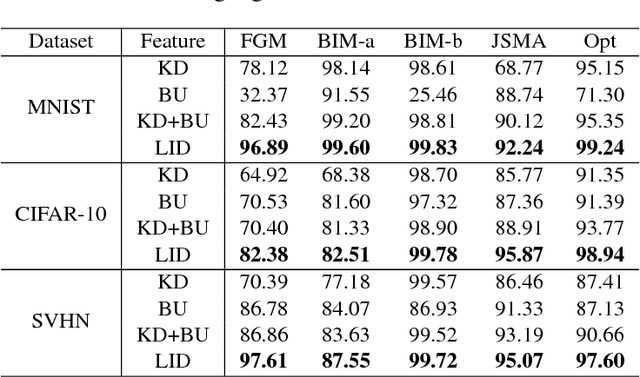

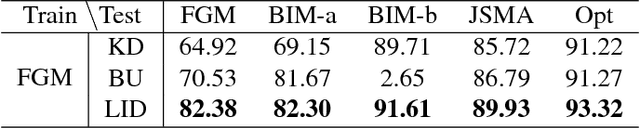
Deep Neural Networks (DNNs) have recently been shown to be vulnerable against adversarial examples, which are carefully crafted instances that can mislead DNNs to make errors during prediction. To better understand such attacks, a characterization is needed of the properties of regions (the so-called 'adversarial subspaces') in which adversarial examples lie. We tackle this challenge by characterizing the dimensional properties of adversarial regions, via the use of Local Intrinsic Dimensionality (LID). LID assesses the space-filling capability of the region surrounding a reference example, based on the distance distribution of the example to its neighbors. We first provide explanations about how adversarial perturbation can affect the LID characteristic of adversarial regions, and then show empirically that LID characteristics can facilitate the distinction of adversarial examples generated using state-of-the-art attacks. As a proof-of-concept, we show that a potential application of LID is to distinguish adversarial examples, and the preliminary results show that it can outperform several state-of-the-art detection measures by large margins for five attack strategies considered in this paper across three benchmark datasets. Our analysis of the LID characteristic for adversarial regions not only motivates new directions of effective adversarial defense, but also opens up more challenges for developing new attacks to better understand the vulnerabilities of DNNs.
Providing Effective Real-time Feedback in Simulation-based Surgical Training
Jun 30, 2017
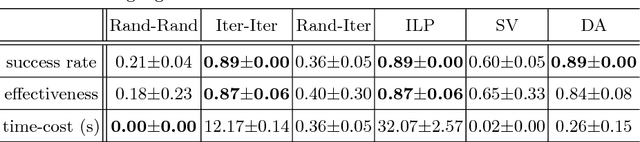
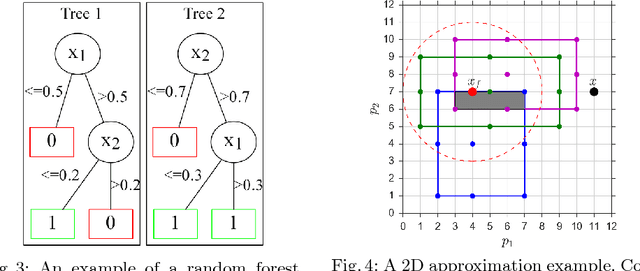

Virtual reality simulation is becoming popular as a training platform in surgical education. However, one important aspect of simulation-based surgical training that has not received much attention is the provision of automated real-time performance feedback to support the learning process. Performance feedback is actionable advice that improves novice behaviour. In simulation, automated feedback is typically extracted from prediction models trained using data mining techniques. Existing techniques suffer from either low effectiveness or low efficiency resulting in their inability to be used in real-time. In this paper, we propose a random forest based method that finds a balance between effectiveness and efficiency. Experimental results in a temporal bone surgery simulation show that the proposed method is able to extract highly effective feedback at a high level of efficiency.
Adversarial Generation of Real-time Feedback with Neural Networks for Simulation-based Training
May 23, 2017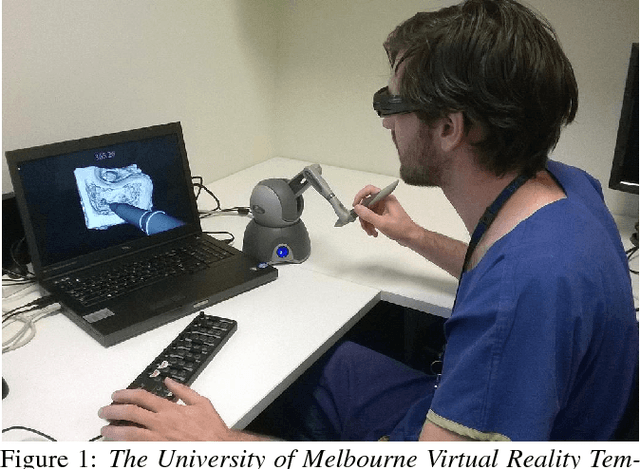
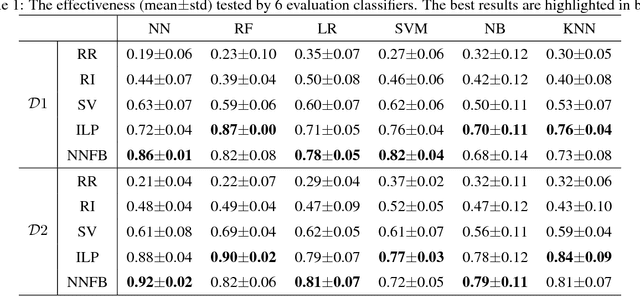
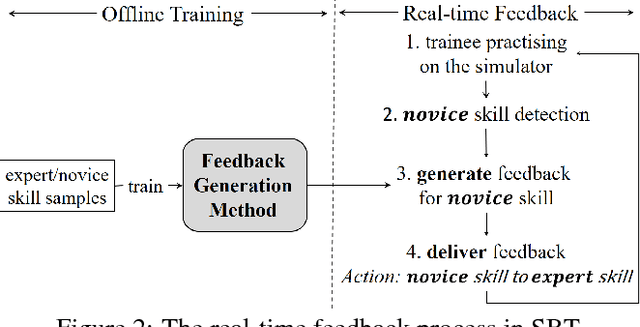
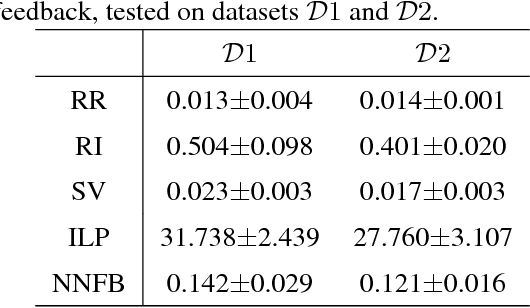
Simulation-based training (SBT) is gaining popularity as a low-cost and convenient training technique in a vast range of applications. However, for a SBT platform to be fully utilized as an effective training tool, it is essential that feedback on performance is provided automatically in real-time during training. It is the aim of this paper to develop an efficient and effective feedback generation method for the provision of real-time feedback in SBT. Existing methods either have low effectiveness in improving novice skills or suffer from low efficiency, resulting in their inability to be used in real-time. In this paper, we propose a neural network based method to generate feedback using the adversarial technique. The proposed method utilizes a bounded adversarial update to minimize a L1 regularized loss via back-propagation. We empirically show that the proposed method can be used to generate simple, yet effective feedback. Also, it was observed to have high effectiveness and efficiency when compared to existing methods, thus making it a promising option for real-time feedback generation in SBT.