 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThermal Prediction for Efficient Energy Management of Clouds using Machine Learning
Nov 10, 2020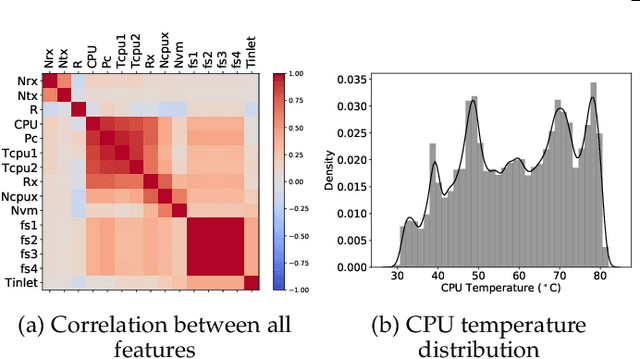
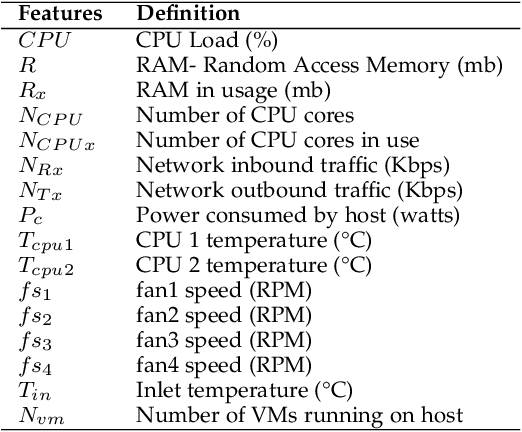
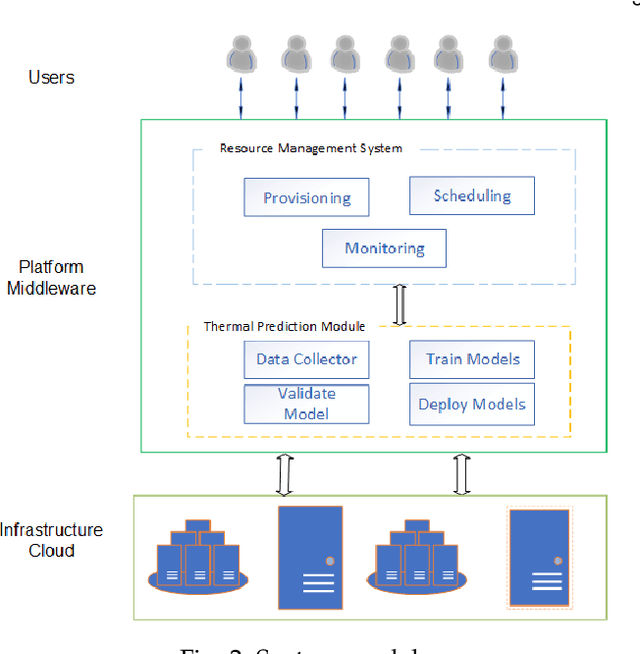

Thermal management in the hyper-scale cloud data centers is a critical problem. Increased host temperature creates hotspots which significantly increases cooling cost and affects reliability. Accurate prediction of host temperature is crucial for managing the resources effectively. Temperature estimation is a non-trivial problem due to thermal variations in the data center. Existing solutions for temperature estimation are inefficient due to their computational complexity and lack of accurate prediction. However, data-driven machine learning methods for temperature prediction is a promising approach. In this regard, we collect and study data from a private cloud and show the presence of thermal variations. We investigate several machine learning models to accurately predict the host temperature. Specifically, we propose a gradient boosting machine learning model for temperature prediction. The experiment results show that our model accurately predicts the temperature with the average RMSE value of 0.05 or an average prediction error of 2.38 degree Celsius, which is 6 degree Celsius less as compared to an existing theoretical model. In addition, we propose a dynamic scheduling algorithm to minimize the peak temperature of hosts. The results show that our algorithm reduces the peak temperature by 6.5 degree Celsius and consumes 34.5% less energy as compared to the baseline algorithm.
Learning Non-Unique Segmentation with Reward-Penalty Dice Loss
Sep 23, 2020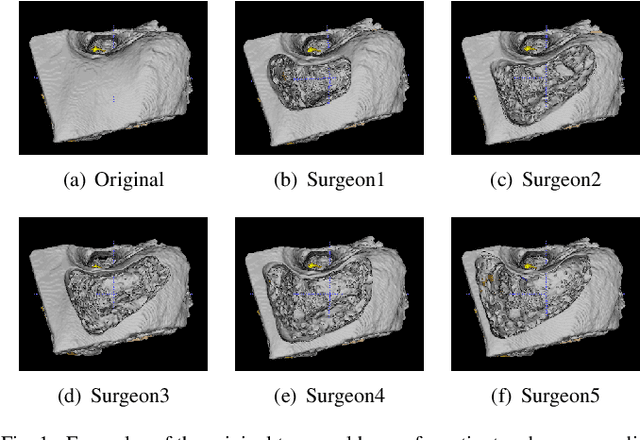
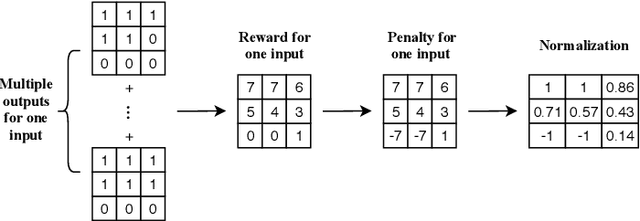

Semantic segmentation is one of the key problems in the field of computer vision, as it enables computer image understanding. However, most research and applications of semantic segmentation focus on addressing unique segmentation problems, where there is only one gold standard segmentation result for every input image. This may not be true in some problems, e.g., medical applications. We may have non-unique segmentation annotations as different surgeons may perform successful surgeries for the same patient in slightly different ways. To comprehensively learn non-unique segmentation tasks, we propose the reward-penalty Dice loss (RPDL) function as the optimization objective for deep convolutional neural networks (DCNN). RPDL is capable of helping DCNN learn non-unique segmentation by enhancing common regions and penalizing outside ones. Experimental results show that RPDL improves the performance of DCNN models by up to 18.4% compared with other loss functions on our collected surgical dataset.
Dynamic Scheduling for Stochastic Edge-Cloud Computing Environments using A3C learning and Residual Recurrent Neural Networks
Sep 01, 2020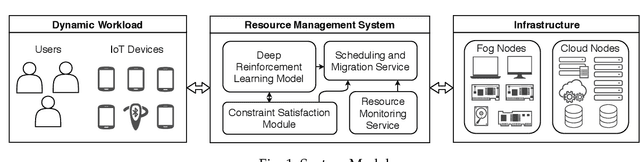

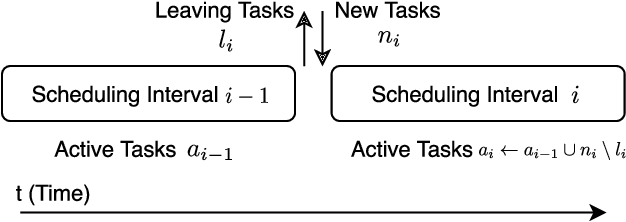

The ubiquitous adoption of Internet-of-Things (IoT) based applications has resulted in the emergence of the Fog computing paradigm, which allows seamlessly harnessing both mobile-edge and cloud resources. Efficient scheduling of application tasks in such environments is challenging due to constrained resource capabilities, mobility factors in IoT, resource heterogeneity, network hierarchy, and stochastic behaviors. xisting heuristics and Reinforcement Learning based approaches lack generalizability and quick adaptability, thus failing to tackle this problem optimally. They are also unable to utilize the temporal workload patterns and are suitable only for centralized setups. However, Asynchronous-Advantage-Actor-Critic (A3C) learning is known to quickly adapt to dynamic scenarios with less data and Residual Recurrent Neural Network (R2N2) to quickly update model parameters. Thus, we propose an A3C based real-time scheduler for stochastic Edge-Cloud environments allowing decentralized learning, concurrently across multiple agents. We use the R2N2 architecture to capture a large number of host and task parameters together with temporal patterns to provide efficient scheduling decisions. The proposed model is adaptive and able to tune different hyper-parameters based on the application requirements. We explicate our choice of hyper-parameters through sensitivity analysis. The experiments conducted on real-world data set show a significant improvement in terms of energy consumption, response time, Service-Level-Agreement and running cost by 14.4%, 7.74%, 31.9%, and 4.64%, respectively when compared to the state-of-the-art algorithms.
MurTree: Optimal Classification Trees via Dynamic Programming and Search
Jul 24, 2020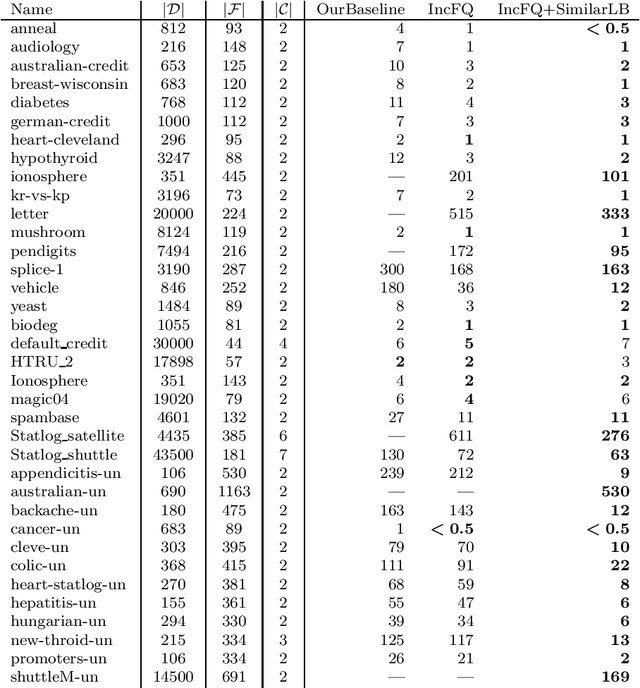
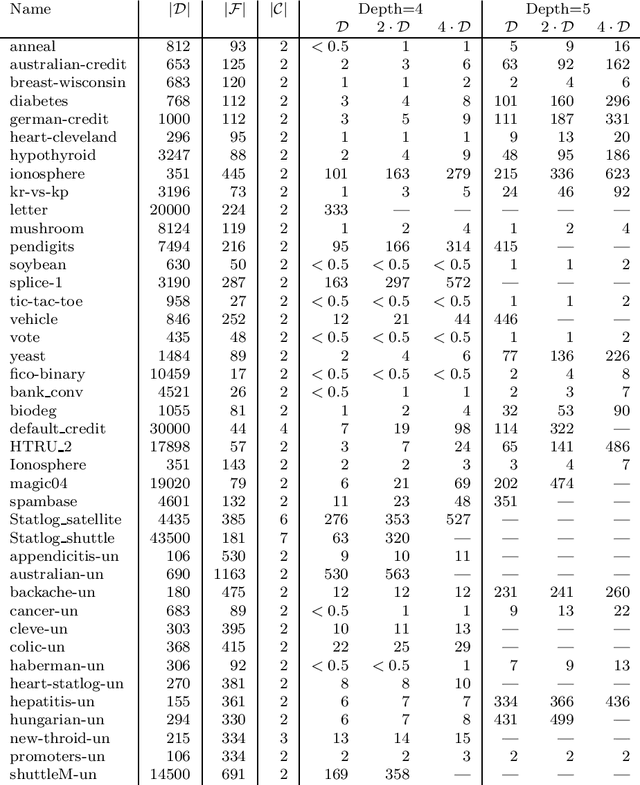
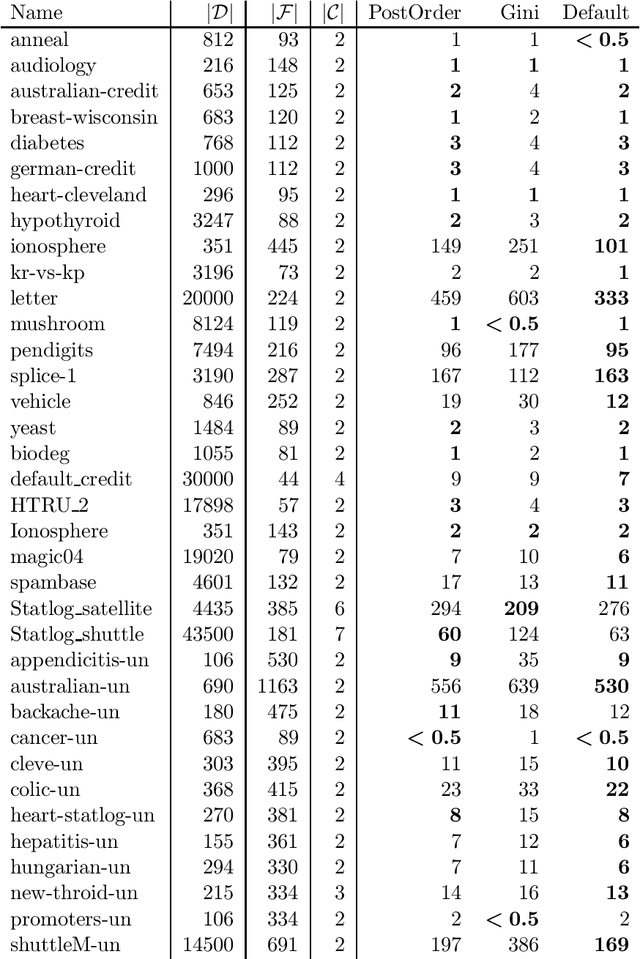
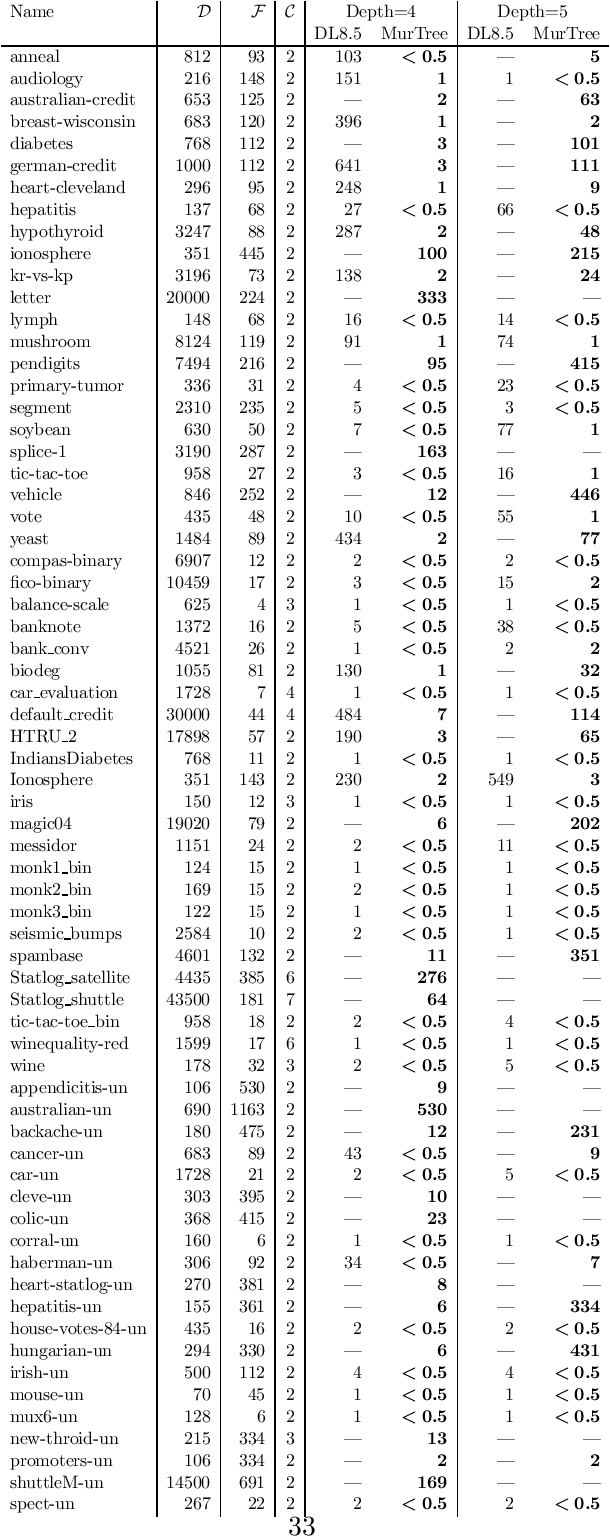
Decision tree learning is a widely used approach in machine learning, favoured in applications that require concise and interpretable models. Heuristic methods are traditionally used to quickly produce models with reasonably high accuracy. A commonly criticised point, however, is that the resulting trees may not necessarily be the best representation of the data in terms of accuracy, size, and other considerations such as fairness. In recent years, this motivated the development of optimal classification tree algorithms that globally optimise the decision tree in contrast to heuristic methods that perform a sequence of locally optimal decisions. We follow this line of work and provide a novel algorithm for learning optimal classification trees based on dynamic programming and search. Our algorithm supports constraints on the depth of the tree and number of nodes and we argue it can be extended with other requirements. The success of our approach is attributed to a series of specialised techniques that exploit properties unique to classification trees. Whereas algorithms for optimal classification trees have traditionally been plagued by high runtimes and limited scalability, we show in a detailed experimental study that our approach uses only a fraction of the time required by the state-of-the-art and can handle datasets with tens of thousands of instances, providing several orders of magnitude improvements and notably contributing towards the practical realisation of optimal decision trees.
Generative Image Inpainting with Submanifold Alignment
Aug 01, 2019
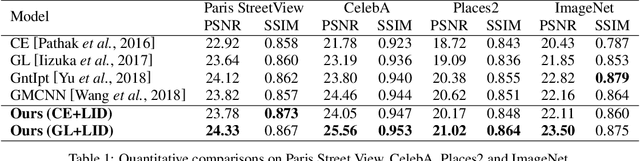
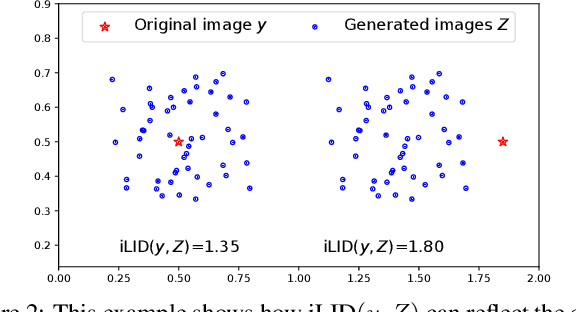

Image inpainting aims at restoring missing regions of corrupted images, which has many applications such as image restoration and object removal. However, current GAN-based generative inpainting models do not explicitly exploit the structural or textural consistency between restored contents and their surrounding contexts.To address this limitation, we propose to enforce the alignment (or closeness) between the local data submanifolds (or subspaces) around restored images and those around the original (uncorrupted) images during the learning process of GAN-based inpainting models. We exploit Local Intrinsic Dimensionality (LID) to measure, in deep feature space, the alignment between data submanifolds learned by a GAN model and those of the original data, from a perspective of both images (denoted as iLID) and local patches (denoted as pLID) of images. We then apply iLID and pLID as regularizations for GAN-based inpainting models to encourage two levels of submanifold alignment: 1) an image-level alignment for improving structural consistency, and 2) a patch-level alignment for improving textural details. Experimental results on four benchmark datasets show that our proposed model can generate more accurate results than state-of-the-art models.
A Jointly Learned Context-Aware Place of Interest Embedding for Trip Recommendations
Aug 24, 2018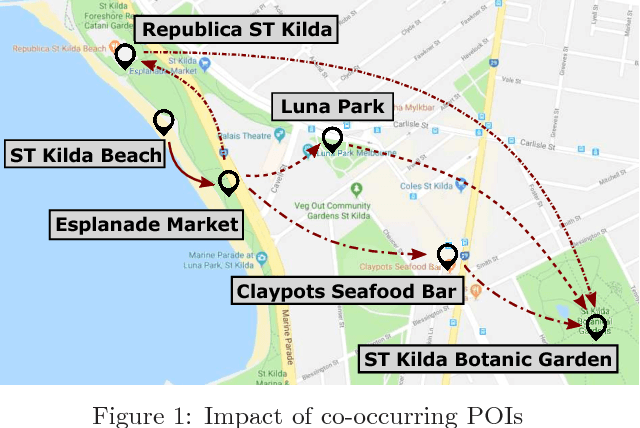

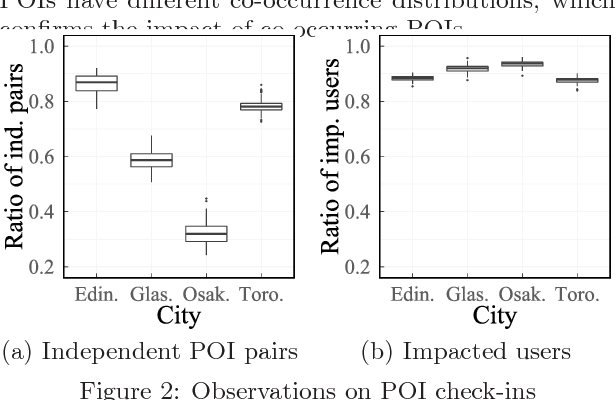

Trip recommendation is an important location-based service that helps relieve users from the time and efforts for trip planning. It aims to recommend a sequence of places of interest (POIs) for a user to visit that maximizes the user's satisfaction. When adding a POI to a recommended trip, it is essential to understand the context of the recommendation, including the POI popularity, other POIs co-occurring in the trip, and the preferences of the user. These contextual factors are learned separately in existing studies, while in reality, they impact jointly on a user's choice of a POI to visit. In this study, we propose a POI embedding model to jointly learn the impact of these contextual factors. We call the learned POI embedding a context-aware POI embedding. To showcase the effectiveness of this embedding, we apply it to generate trip recommendations given a user and a time budget. We propose two trip recommendation algorithms based on our context-aware POI embedding. The first algorithm finds the exact optimal trip by transforming and solving the trip recommendation problem as an integer linear programming problem. To achieve a high computation efficiency, the second algorithm finds a heuristically optimal trip based on adaptive large neighborhood search. We perform extensive experiments on real datasets. The results show that our proposed algorithms consistently outperform state-of-the-art algorithms in trip recommendation quality, with an advantage of up to 43% in F1-score.
Learning with Bounded Instance- and Label-dependent Label Noise
Sep 12, 2017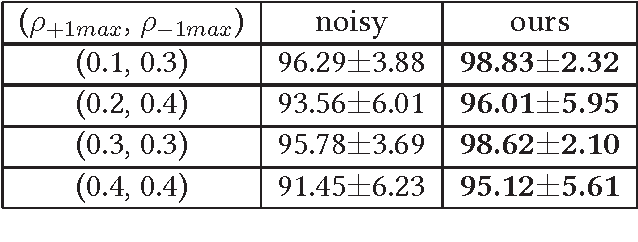
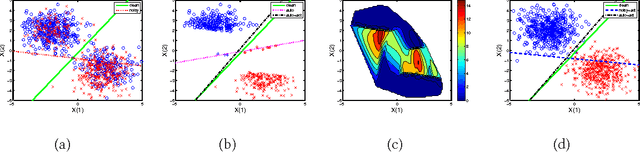
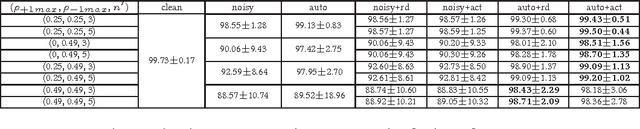
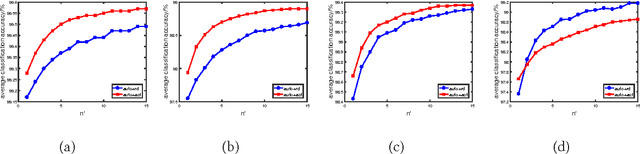
Instance- and label-dependent label noise (ILN) is widely existed in real-world datasets but has been rarely studied. In this paper, we focus on a particular case of ILN where the label noise rates, representing the probabilities that the true labels of examples flip into the corrupted labels, have upper bounds. We propose to handle this bounded instance- and label-dependent label noise under two different conditions. First, theoretically, we prove that when the marginal distributions $P(X|Y=+1)$ and $P(X|Y=-1)$ have non-overlapping supports, we can recover every noisy example's true label and perform supervised learning directly on the cleansed examples. Second, for the overlapping situation, we propose a novel approach to learn a well-performing classifier which needs only a few noisy examples to be labeled manually. Experimental results demonstrate that our method works well on both synthetic and real-world datasets.
Tensor Canonical Correlation Analysis for Multi-view Dimension Reduction
Feb 09, 2015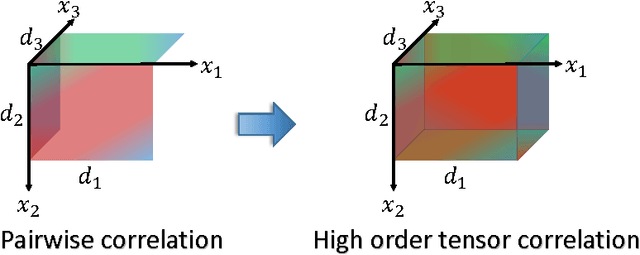
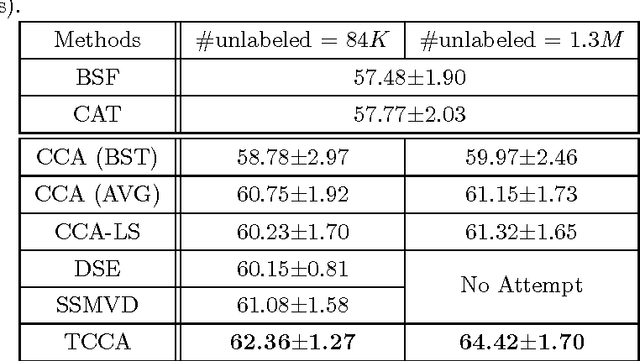
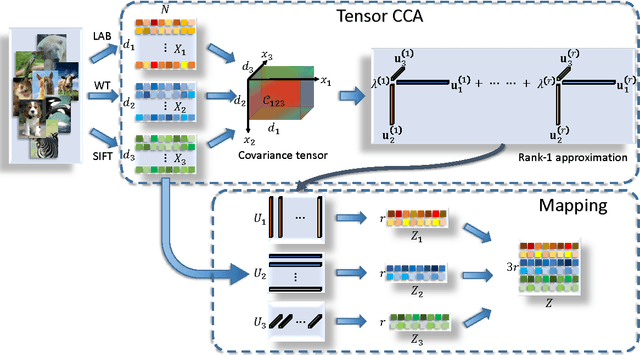
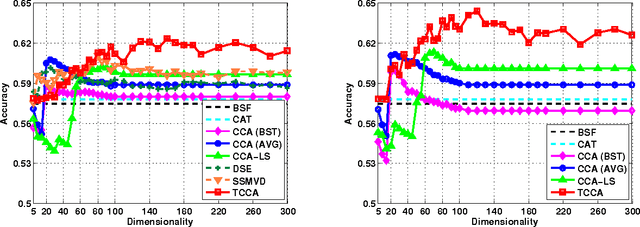
Canonical correlation analysis (CCA) has proven an effective tool for two-view dimension reduction due to its profound theoretical foundation and success in practical applications. In respect of multi-view learning, however, it is limited by its capability of only handling data represented by two-view features, while in many real-world applications, the number of views is frequently many more. Although the ad hoc way of simultaneously exploring all possible pairs of features can numerically deal with multi-view data, it ignores the high order statistics (correlation information) which can only be discovered by simultaneously exploring all features. Therefore, in this work, we develop tensor CCA (TCCA) which straightforwardly yet naturally generalizes CCA to handle the data of an arbitrary number of views by analyzing the covariance tensor of the different views. TCCA aims to directly maximize the canonical correlation of multiple (more than two) views. Crucially, we prove that the multi-view canonical correlation maximization problem is equivalent to finding the best rank-1 approximation of the data covariance tensor, which can be solved efficiently using the well-known alternating least squares (ALS) algorithm. As a consequence, the high order correlation information contained in the different views is explored and thus a more reliable common subspace shared by all features can be obtained. In addition, a non-linear extension of TCCA is presented. Experiments on various challenge tasks, including large scale biometric structure prediction, internet advertisement classification and web image annotation, demonstrate the effectiveness of the proposed method.