 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAADNet: Exploring EEG Spatiotemporal Information for Fast and Accurate Orientation and Timbre Detection of Auditory Attention Based on A Cue-Masked Paradigm
Jan 07, 2025Auditory attention decoding from electroencephalogram (EEG) could infer to which source the user is attending in noisy environments. Decoding algorithms and experimental paradigm designs are crucial for the development of technology in practical applications. To simulate real-world scenarios, this study proposed a cue-masked auditory attention paradigm to avoid information leakage before the experiment. To obtain high decoding accuracy with low latency, an end-to-end deep learning model, AADNet, was proposed to exploit the spatiotemporal information from the short time window of EEG signals. The results showed that with a 0.5-second EEG window, AADNet achieved an average accuracy of 93.46% and 91.09% in decoding auditory orientation attention (OA) and timbre attention (TA), respectively. It significantly outperformed five previous methods and did not need the knowledge of the original audio source. This work demonstrated that it was possible to detect the orientation and timbre of auditory attention from EEG signals fast and accurately. The results are promising for the real-time multi-property auditory attention decoding, facilitating the application of the neuro-steered hearing aids and other assistive listening devices.
Learning on Multimodal Graphs: A Survey
Feb 07, 2024

Multimodal data pervades various domains, including healthcare, social media, and transportation, where multimodal graphs play a pivotal role. Machine learning on multimodal graphs, referred to as multimodal graph learning (MGL), is essential for successful artificial intelligence (AI) applications. The burgeoning research in this field encompasses diverse graph data types and modalities, learning techniques, and application scenarios. This survey paper conducts a comparative analysis of existing works in multimodal graph learning, elucidating how multimodal learning is achieved across different graph types and exploring the characteristics of prevalent learning techniques. Additionally, we delineate significant applications of multimodal graph learning and offer insights into future directions in this domain. Consequently, this paper serves as a foundational resource for researchers seeking to comprehend existing MGL techniques and their applicability across diverse scenarios.
Principles from Clinical Research for NLP Model Generalization
Nov 09, 2023The NLP community typically relies on performance of a model on a held-out test set to assess generalization. Performance drops observed in datasets outside of official test sets are generally attributed to "out-of-distribution'' effects. Here, we explore the foundations of generalizability and study the various factors that affect it, articulating generalizability lessons from clinical studies. In clinical research generalizability depends on (a) internal validity of experiments to ensure controlled measurement of cause and effect, and (b) external validity or transportability of the results to the wider population. We present the need to ensure internal validity when building machine learning models in natural language processing, especially where results may be impacted by spurious correlations in the data. We demonstrate how spurious factors, such as the distance between entities in relation extraction tasks, can affect model internal validity and in turn adversely impact generalization. We also offer guidance on how to analyze generalization failures.
Effects of Human Adversarial and Affable Samples on BERT Generalizability
Oct 17, 2023



BERT-based models have had strong performance on leaderboards, yet have been demonstrably worse in real-world settings requiring generalization. Limited quantities of training data is considered a key impediment to achieving generalizability in machine learning. In this paper, we examine the impact of training data quality, not quantity, on a model's generalizability. We consider two characteristics of training data: the portion of human-adversarial (h-adversarial), i.e., sample pairs with seemingly minor differences but different ground-truth labels, and human-affable (h-affable) training samples, i.e., sample pairs with minor differences but the same ground-truth label. We find that for a fixed size of training samples, as a rule of thumb, having 10-30% h-adversarial instances improves the precision, and therefore F1, by up to 20 points in the tasks of text classification and relation extraction. Increasing h-adversarials beyond this range can result in performance plateaus or even degradation. In contrast, h-affables may not contribute to a model's generalizability and may even degrade generalization performance.
A Survey on Class Imbalance in Federated Learning
Mar 21, 2023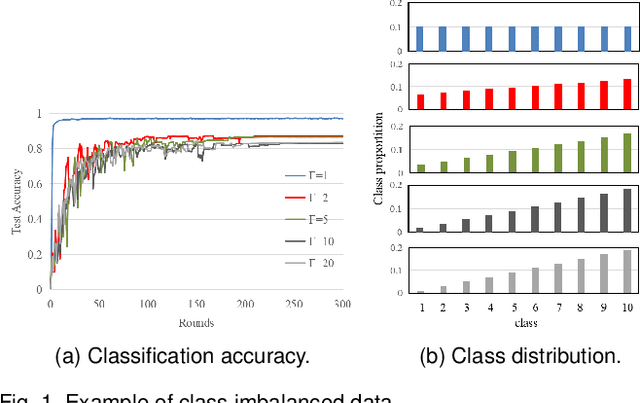
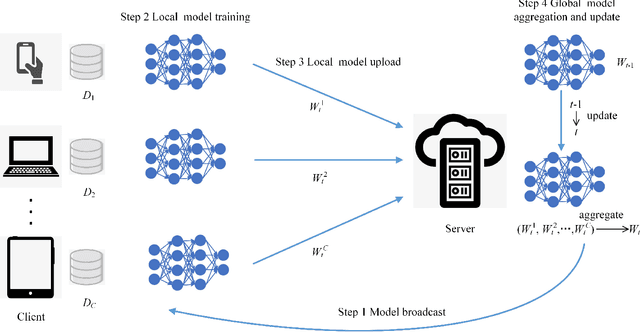
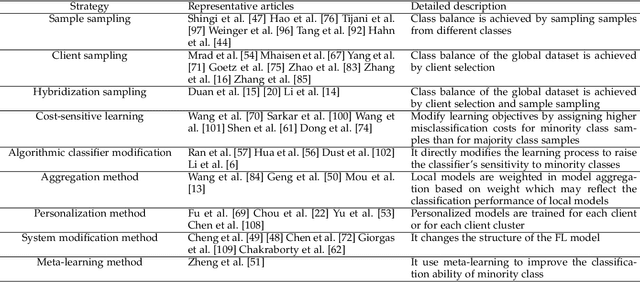
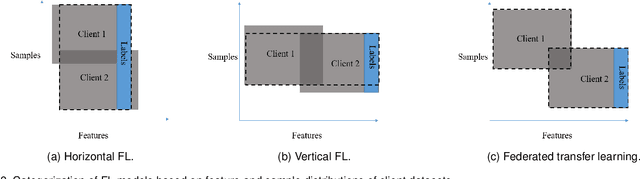
Federated learning, which allows multiple client devices in a network to jointly train a machine learning model without direct exposure of clients' data, is an emerging distributed learning technique due to its nature of privacy preservation. However, it has been found that models trained with federated learning usually have worse performance than their counterparts trained in the standard centralized learning mode, especially when the training data is imbalanced. In the context of federated learning, data imbalance may occur either locally one one client device, or globally across many devices. The complexity of different types of data imbalance has posed challenges to the development of federated learning technique, especially considering the need of relieving data imbalance issue and preserving data privacy at the same time. Therefore, in the literature, many attempts have been made to handle class imbalance in federated learning. In this paper, we present a detailed review of recent advancements along this line. We first introduce various types of class imbalance in federated learning, after which we review existing methods for estimating the extent of class imbalance without the need of knowing the actual data to preserve data privacy. After that, we discuss existing methods for handling class imbalance in FL, where the advantages and disadvantages of the these approaches are discussed. We also summarize common evaluation metrics for class imbalanced tasks, and point out potential future directions.
Beyond Just Vision: A Review on Self-Supervised Representation Learning on Multimodal and Temporal Data
Jun 08, 2022
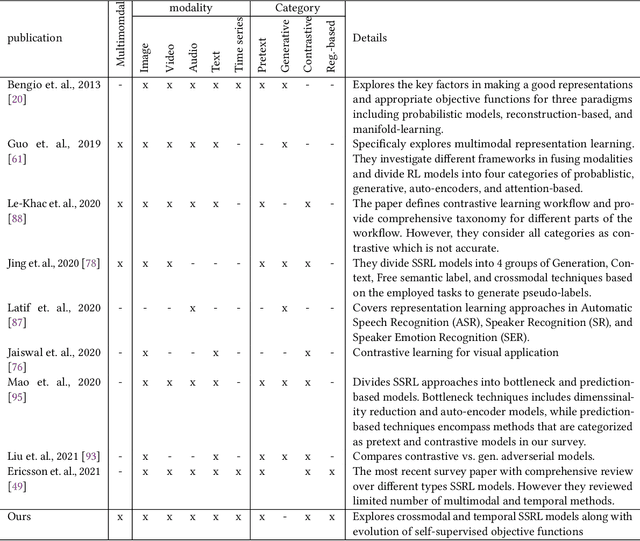

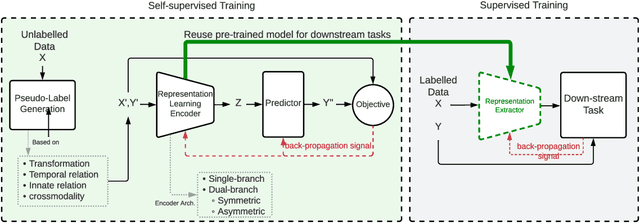
Recently, Self-Supervised Representation Learning (SSRL) has attracted much attention in the field of computer vision, speech, natural language processing (NLP), and recently, with other types of modalities, including time series from sensors. The popularity of self-supervised learning is driven by the fact that traditional models typically require a huge amount of well-annotated data for training. Acquiring annotated data can be a difficult and costly process. Self-supervised methods have been introduced to improve the efficiency of training data through discriminative pre-training of models using supervisory signals that have been freely obtained from the raw data. Unlike existing reviews of SSRL that have pre-dominately focused upon methods in the fields of CV or NLP for a single modality, we aim to provide the first comprehensive review of multimodal self-supervised learning methods for temporal data. To this end, we 1) provide a comprehensive categorization of existing SSRL methods, 2) introduce a generic pipeline by defining the key components of a SSRL framework, 3) compare existing models in terms of their objective function, network architecture and potential applications, and 4) review existing multimodal techniques in each category and various modalities. Finally, we present existing weaknesses and future opportunities. We believe our work develops a perspective on the requirements of SSRL in domains that utilise multimodal and/or temporal data
Open Access Dataset for Electromyography based Multi-code Biometric Authentication
Jan 05, 2022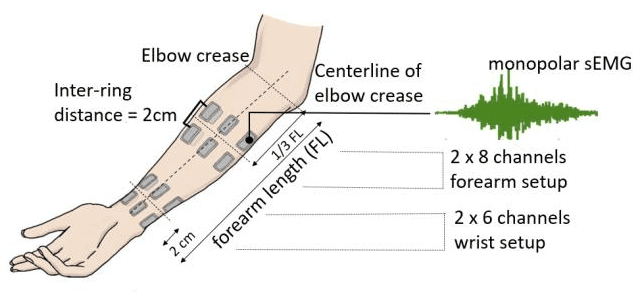
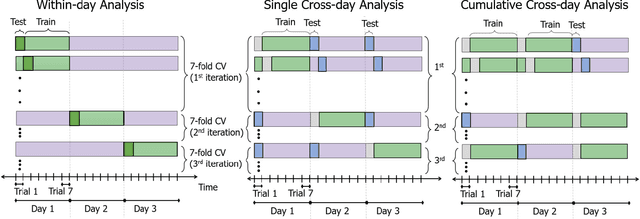
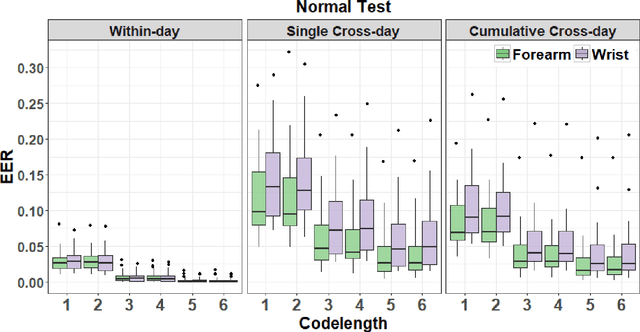
Recently, surface electromyogram (EMG) has been proposed as a novel biometric trait for addressing some key limitations of current biometrics, such as spoofing and liveness. The EMG signals possess a unique characteristic: they are inherently different for individuals (biometrics), and they can be customized to realize multi-length codes or passwords (for example, by performing different gestures). However, current EMG-based biometric research has two critical limitations: 1) a small subject pool, compared to other more established biometric traits, and 2) limited to single-session or single-day data sets. In this study, forearm and wrist EMG data were collected from 43 participants over three different days with long separation while they performed static hand and wrist gestures. The multi-day biometric authentication resulted in a median EER of 0.017 for the forearm setup and 0.025 for the wrist setup, comparable to well-established biometric traits suggesting consistent performance over multiple days. The presented large-sample multi-day data set and findings could facilitate further research on EMG-based biometrics and other gesture recognition-based applications.
Performance Optimization of Surface Electromyography (sEMG) based Biometric Sensing System for both Verification and Identification
Mar 10, 2021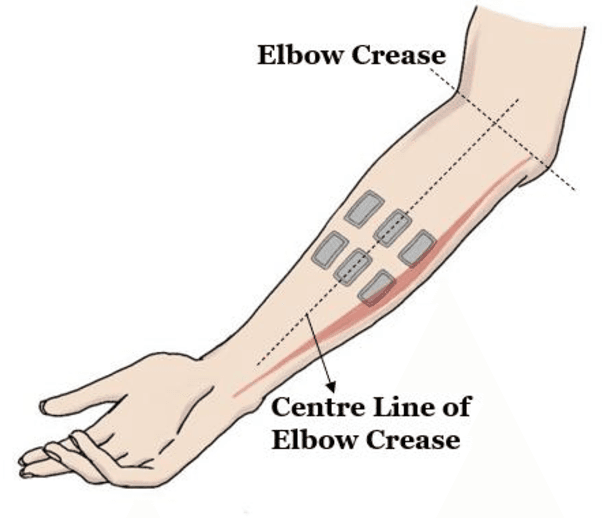
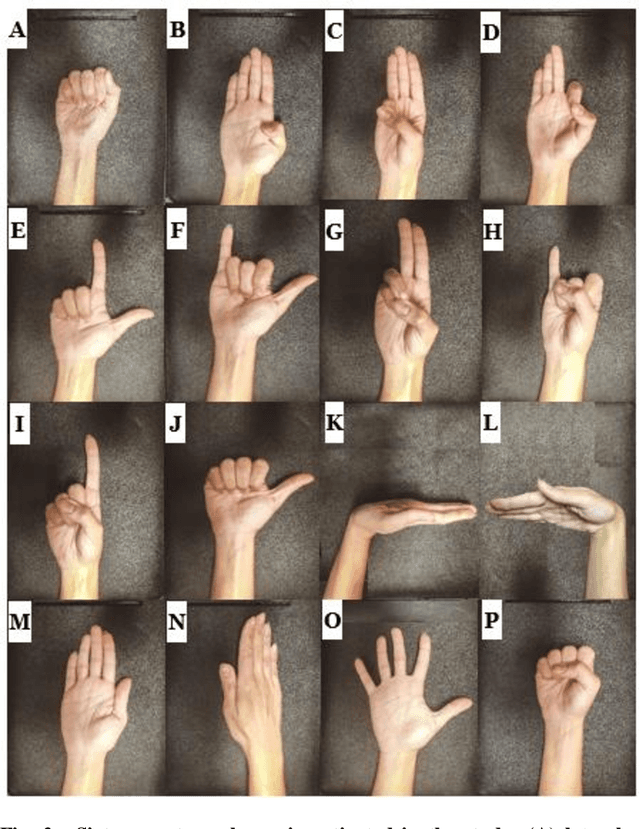
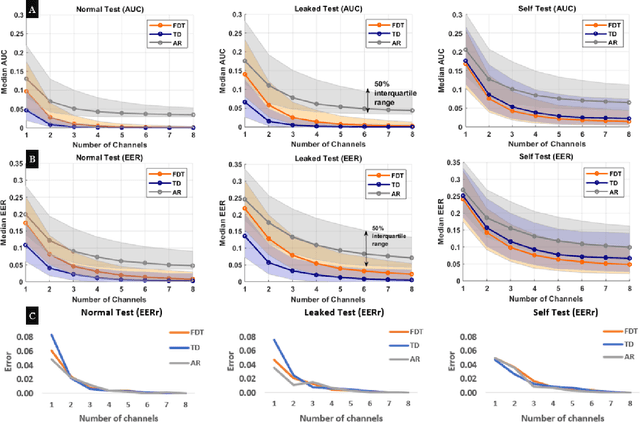
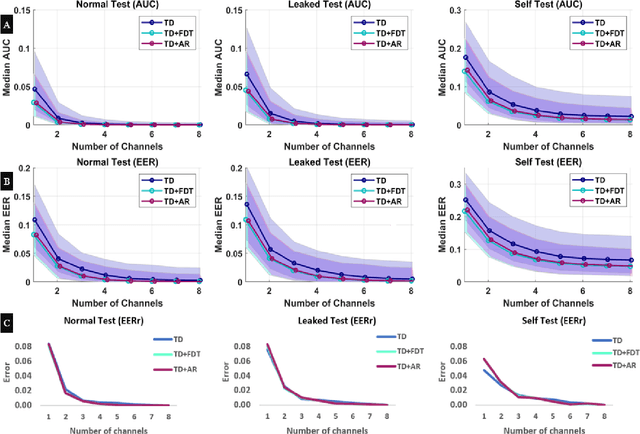
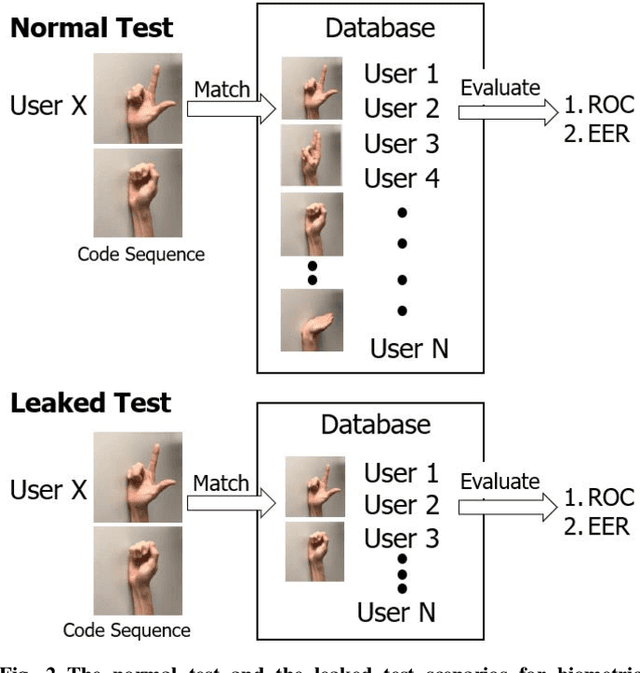
Recently, surface electromyography (sEMG) emerged as a novel biometric authentication method. Since EMG system parameters, such as the feature extraction methods and the number of channels, have been known to affect system performances, it is important to investigate these effects on the performance of the sEMG-based biometric system to determine optimal system parameters. In this study, three robust feature extraction methods, Time-domain (TD) feature, Frequency Division Technique (FDT), and Autoregressive (AR) feature, and their combinations were investigated while the number of channels varying from one to eight. For these system parameters, the performance of sixteen static wrist and hand gestures was systematically investigated in two authentication modes: verification and identification. The results from 24 participants showed that the TD features significantly (p<0.05) and consistently outperformed FDT and AR features for all channel numbers. The results also showed that the performance of a four-channel setup was not significantly different from those with higher number of channels. The average equal error rate (EER) for a four-channel sEMG verification system was 4% for TD features, 5.3% for FDT features, and 10% for AR features. For an identification system, the average Rank-1 error (R1E) for a four-channel configuration was 3% for TD features, 12.4% for FDT features, and 36.3% for AR features. The electrode position on the flexor carpi ulnaris (FCU) muscle had a critical contribution to the authentication performance. Thus, the combination of the TD feature set and a four-channel sEMG system with one of the electrodes positioned on the FCU are recommended for optimal authentication performance.
Memorization vs. Generalization: Quantifying Data Leakage in NLP Performance Evaluation
Feb 03, 2021


Public datasets are often used to evaluate the efficacy and generalizability of state-of-the-art methods for many tasks in natural language processing (NLP). However, the presence of overlap between the train and test datasets can lead to inflated results, inadvertently evaluating the model's ability to memorize and interpreting it as the ability to generalize. In addition, such data sets may not provide an effective indicator of the performance of these methods in real world scenarios. We identify leakage of training data into test data on several publicly available datasets used to evaluate NLP tasks, including named entity recognition and relation extraction, and study them to assess the impact of that leakage on the model's ability to memorize versus generalize.
A Jointly Learned Context-Aware Place of Interest Embedding for Trip Recommendations
Aug 24, 2018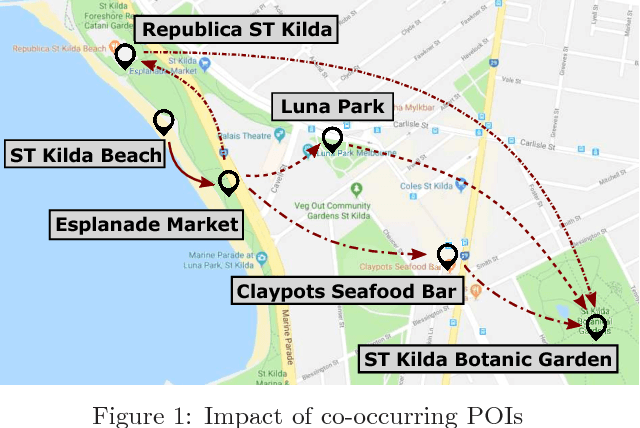

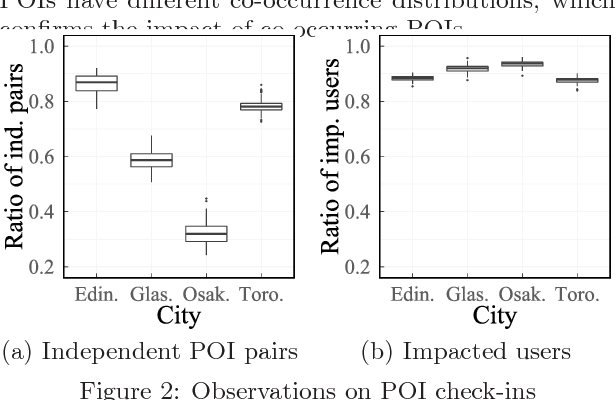

Trip recommendation is an important location-based service that helps relieve users from the time and efforts for trip planning. It aims to recommend a sequence of places of interest (POIs) for a user to visit that maximizes the user's satisfaction. When adding a POI to a recommended trip, it is essential to understand the context of the recommendation, including the POI popularity, other POIs co-occurring in the trip, and the preferences of the user. These contextual factors are learned separately in existing studies, while in reality, they impact jointly on a user's choice of a POI to visit. In this study, we propose a POI embedding model to jointly learn the impact of these contextual factors. We call the learned POI embedding a context-aware POI embedding. To showcase the effectiveness of this embedding, we apply it to generate trip recommendations given a user and a time budget. We propose two trip recommendation algorithms based on our context-aware POI embedding. The first algorithm finds the exact optimal trip by transforming and solving the trip recommendation problem as an integer linear programming problem. To achieve a high computation efficiency, the second algorithm finds a heuristically optimal trip based on adaptive large neighborhood search. We perform extensive experiments on real datasets. The results show that our proposed algorithms consistently outperform state-of-the-art algorithms in trip recommendation quality, with an advantage of up to 43% in F1-score.