 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Class Imbalance in Federated Learning
Paper and Code
Mar 21, 2023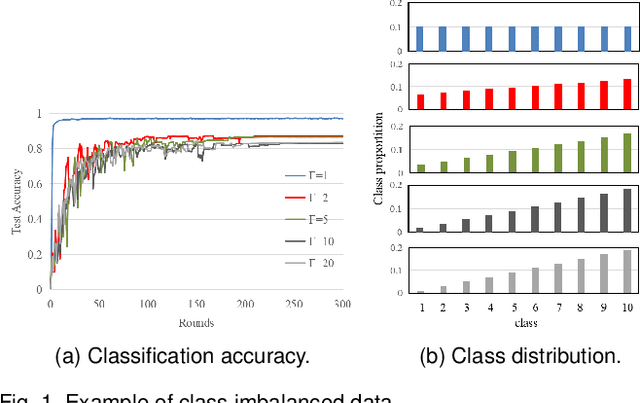
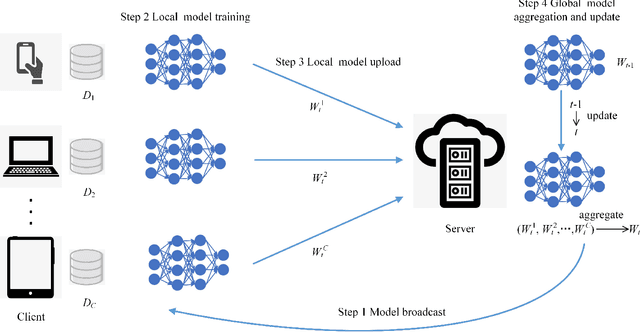
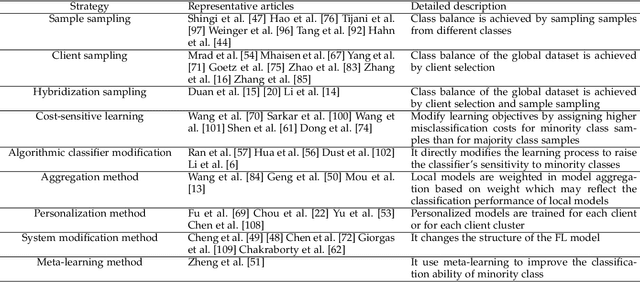
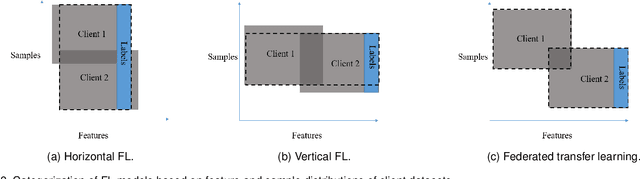
Federated learning, which allows multiple client devices in a network to jointly train a machine learning model without direct exposure of clients' data, is an emerging distributed learning technique due to its nature of privacy preservation. However, it has been found that models trained with federated learning usually have worse performance than their counterparts trained in the standard centralized learning mode, especially when the training data is imbalanced. In the context of federated learning, data imbalance may occur either locally one one client device, or globally across many devices. The complexity of different types of data imbalance has posed challenges to the development of federated learning technique, especially considering the need of relieving data imbalance issue and preserving data privacy at the same time. Therefore, in the literature, many attempts have been made to handle class imbalance in federated learning. In this paper, we present a detailed review of recent advancements along this line. We first introduce various types of class imbalance in federated learning, after which we review existing methods for estimating the extent of class imbalance without the need of knowing the actual data to preserve data privacy. After that, we discuss existing methods for handling class imbalance in FL, where the advantages and disadvantages of the these approaches are discussed. We also summarize common evaluation metrics for class imbalanced tasks, and point out potential future directions.