 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOCOA: Cross Modality Contrastive Learning for Sensor Data
Aug 03, 2022
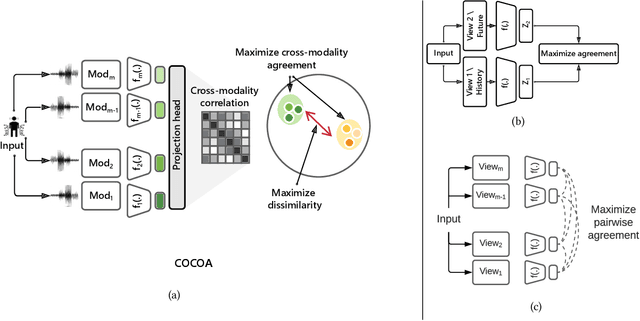

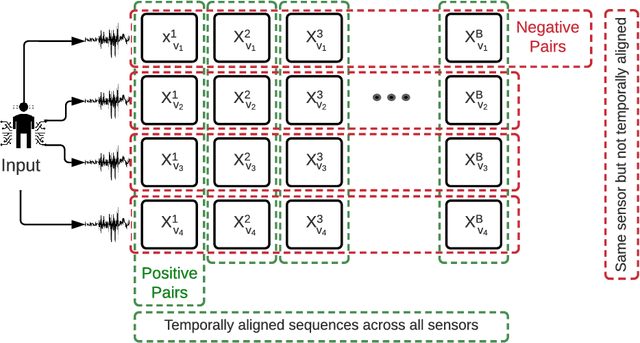
Self-Supervised Learning (SSL) is a new paradigm for learning discriminative representations without labelled data and has reached comparable or even state-of-the-art results in comparison to supervised counterparts. Contrastive Learning (CL) is one of the most well-known approaches in SSL that attempts to learn general, informative representations of data. CL methods have been mostly developed for applications in computer vision and natural language processing where only a single sensor modality is used. A majority of pervasive computing applications, however, exploit data from a range of different sensor modalities. While existing CL methods are limited to learning from one or two data sources, we propose COCOA (Cross mOdality COntrastive leArning), a self-supervised model that employs a novel objective function to learn quality representations from multisensor data by computing the cross-correlation between different data modalities and minimizing the similarity between irrelevant instances. We evaluate the effectiveness of COCOA against eight recently introduced state-of-the-art self-supervised models, and two supervised baselines across five public datasets. We show that COCOA achieves superior classification performance to all other approaches. Also, COCOA is far more label-efficient than the other baselines including the fully supervised model using only one-tenth of available labelled data.
Beyond Just Vision: A Review on Self-Supervised Representation Learning on Multimodal and Temporal Data
Jun 08, 2022
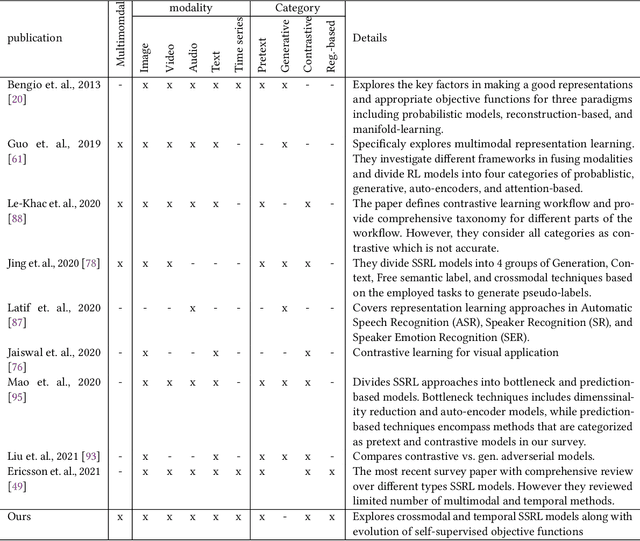

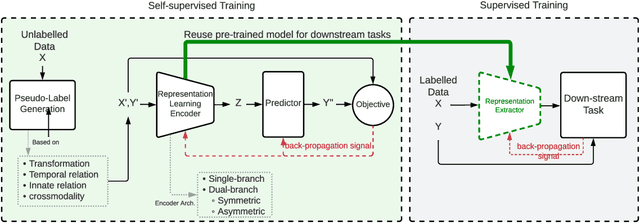
Recently, Self-Supervised Representation Learning (SSRL) has attracted much attention in the field of computer vision, speech, natural language processing (NLP), and recently, with other types of modalities, including time series from sensors. The popularity of self-supervised learning is driven by the fact that traditional models typically require a huge amount of well-annotated data for training. Acquiring annotated data can be a difficult and costly process. Self-supervised methods have been introduced to improve the efficiency of training data through discriminative pre-training of models using supervisory signals that have been freely obtained from the raw data. Unlike existing reviews of SSRL that have pre-dominately focused upon methods in the fields of CV or NLP for a single modality, we aim to provide the first comprehensive review of multimodal self-supervised learning methods for temporal data. To this end, we 1) provide a comprehensive categorization of existing SSRL methods, 2) introduce a generic pipeline by defining the key components of a SSRL framework, 3) compare existing models in terms of their objective function, network architecture and potential applications, and 4) review existing multimodal techniques in each category and various modalities. Finally, we present existing weaknesses and future opportunities. We believe our work develops a perspective on the requirements of SSRL in domains that utilise multimodal and/or temporal data
Time-series Change Point Detection with Self-Supervised Contrastive Predictive Coding
Dec 01, 2020
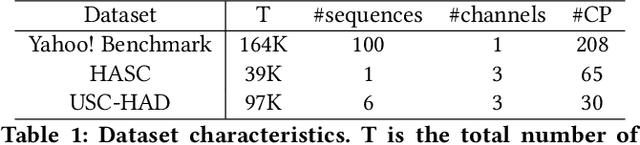
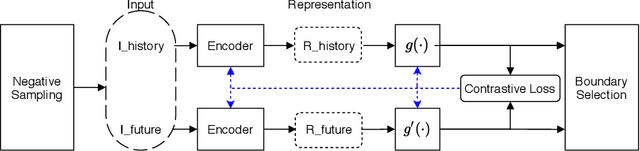

Change Point Detection techniques aim to capture changes in trends and sequences in time-series data to describe the underlying behaviour of the system. Detecting changes and anomalies in the web services, the trend of applications usage can provide valuable insight towards the system, however, many existing approaches are done in a supervised manner, requiring well-labelled data. As the amount of data produced and captured by sensors are growing rapidly, it is getting harder and even impossible to annotate the data. Therefore, coming up with a self-supervised solution is a necessity these days. In this work, we propose TSCP2 a novel self-supervised technique for temporal change point detection, based on representation learning with Temporal Convolutional Network (TCN). To the best of our knowledge, our proposed method is the first method which employs Contrastive Learning for prediction with the aim change point detection. Through extensive evaluations, we demonstrate that our method outperforms multiple state-of-the-art change point detection and anomaly detection baselines, including those adopting either unsupervised or semi-supervised approach. TSCP2 is shown to improve both non-Deep learning- and Deep learning-based methods by 0.28 and 0.12 in terms of average F1-score across three datasets.
ESPRESSO: Entropy and ShaPe awaRe timE-Series SegmentatiOn for processing heterogeneous sensor data
Jul 24, 2020

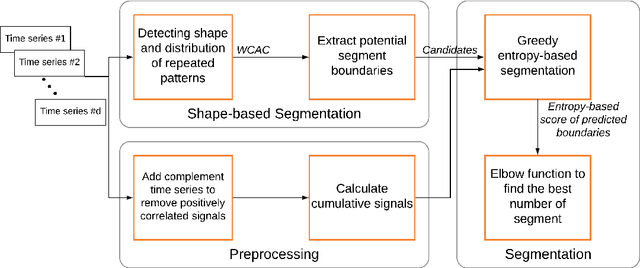
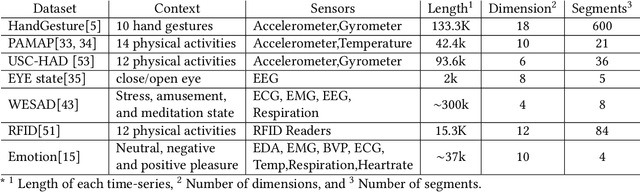
Extracting informative and meaningful temporal segments from high-dimensional wearable sensor data, smart devices, or IoT data is a vital preprocessing step in applications such as Human Activity Recognition (HAR), trajectory prediction, gesture recognition, and lifelogging. In this paper, we propose ESPRESSO (Entropy and ShaPe awaRe timE-Series SegmentatiOn), a hybrid segmentation model for multi-dimensional time-series that is formulated to exploit the entropy and temporal shape properties of time-series. ESPRESSO differs from existing methods that focus upon particular statistical or temporal properties of time-series exclusively. As part of model development, a novel temporal representation of time-series $WCAC$ was introduced along with a greedy search approach that estimate segments based upon the entropy metric. ESPRESSO was shown to offer superior performance to four state-of-the-art methods across seven public datasets of wearable and wear-free sensing. In addition, we undertake a deeper investigation of these datasets to understand how ESPRESSO and its constituent methods perform with respect to different dataset characteristics. Finally, we provide two interesting case-studies to show how applying ESPRESSO can assist in inferring daily activity routines and the emotional state of humans.