 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinate Matrix Machine: A Human-level Concept Learning to Classify Very Similar Documents
Dec 26, 2025Human-level concept learning argues that humans typically learn new concepts from a single example, whereas machine learning algorithms typically require hundreds of samples to learn a single concept. Our brain subconsciously identifies important features and learns more effectively. \vspace*{6pt} Contribution: In this paper, we present the Coordinate Matrix Machine (CM$^2$). This purpose-built small model augments human intelligence by learning document structures and using this information to classify documents. While modern "Red AI" trends rely on massive pre-training and energy-intensive GPU infrastructure, CM$^2$ is designed as a Green AI solution. It achieves human-level concept learning by identifying only the structural "important features" a human would consider, allowing it to classify very similar documents using only one sample per class. Advantage: Our algorithm outperforms traditional vectorizers and complex deep learning models that require larger datasets and significant compute. By focusing on structural coordinates rather than exhaustive semantic vectors, CM$^2$ offers: 1. High accuracy with minimal data (one-shot learning) 2. Geometric and structural intelligence 3. Green AI and environmental sustainability 4. Optimized for CPU-only environments 5. Inherent explainability (glass-box model) 6. Faster computation and low latency 7. Robustness against unbalanced classes 8. Economic viability 9. Generic, expandable, and extendable
ESPRESSO: Entropy and ShaPe awaRe timE-Series SegmentatiOn for processing heterogeneous sensor data
Jul 24, 2020

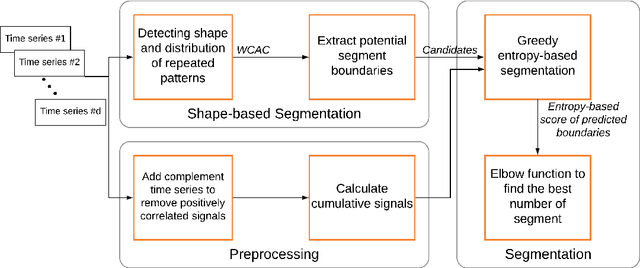
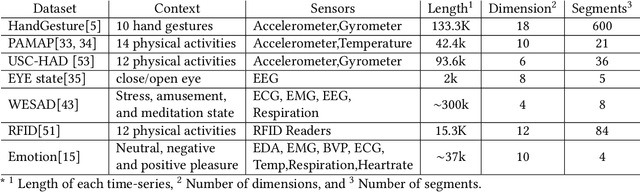
Extracting informative and meaningful temporal segments from high-dimensional wearable sensor data, smart devices, or IoT data is a vital preprocessing step in applications such as Human Activity Recognition (HAR), trajectory prediction, gesture recognition, and lifelogging. In this paper, we propose ESPRESSO (Entropy and ShaPe awaRe timE-Series SegmentatiOn), a hybrid segmentation model for multi-dimensional time-series that is formulated to exploit the entropy and temporal shape properties of time-series. ESPRESSO differs from existing methods that focus upon particular statistical or temporal properties of time-series exclusively. As part of model development, a novel temporal representation of time-series $WCAC$ was introduced along with a greedy search approach that estimate segments based upon the entropy metric. ESPRESSO was shown to offer superior performance to four state-of-the-art methods across seven public datasets of wearable and wear-free sensing. In addition, we undertake a deeper investigation of these datasets to understand how ESPRESSO and its constituent methods perform with respect to different dataset characteristics. Finally, we provide two interesting case-studies to show how applying ESPRESSO can assist in inferring daily activity routines and the emotional state of humans.