 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Data to Say No: Memory Augmented Plug-and-Play Selective Prediction
Jan 30, 2026Selective prediction aims to endow predictors with a reject option, to avoid low confidence predictions. However, existing literature has primarily focused on closed-set tasks, such as visual question answering with predefined options or fixed-category classification. This paper considers selective prediction for visual language foundation models, addressing a taxonomy of tasks ranging from closed to open set and from finite to unbounded vocabularies, as in image captioning. We seek training-free approaches of low-complexity, applicable to any foundation model and consider methods based on external vision-language model embeddings, like CLIP. This is denoted as Plug-and-Play Selective Prediction (PaPSP). We identify two key challenges: (1) instability of the visual-language representations, leading to high variance in image-text embeddings, and (2) poor calibration of similarity scores. To address these issues, we propose a memory augmented PaPSP (MA-PaPSP) model, which augments PaPSP with a retrieval dataset of image-text pairs. This is leveraged to reduce embedding variance by averaging retrieved nearest-neighbor pairs and is complemented by the use of contrastive normalization to improve score calibration. Through extensive experiments on multiple datasets, we show that MA-PaPSP outperforms PaPSP and other selective prediction baselines for selective captioning, image-text matching, and fine-grained classification. Code is publicly available at https://github.com/kingston-aditya/MA-PaPSP.
EgoPrivacy: What Your First-Person Camera Says About You?
Jun 13, 2025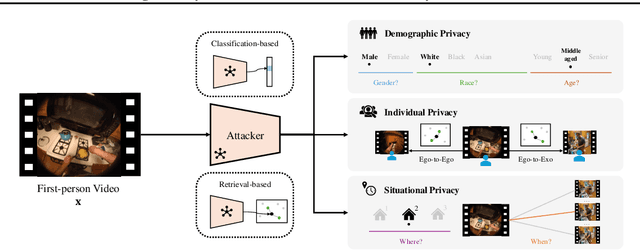
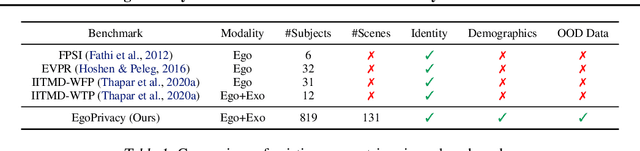
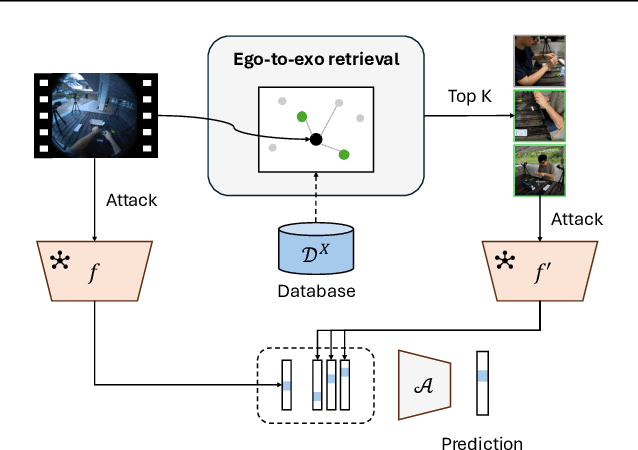
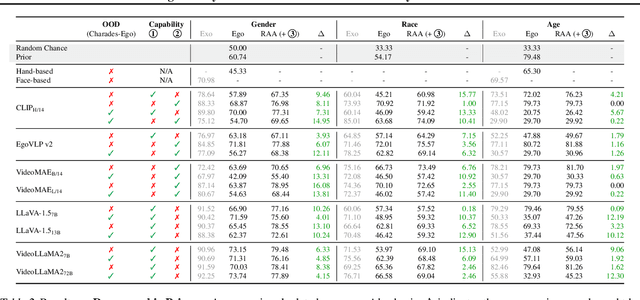
While the rapid proliferation of wearable cameras has raised significant concerns about egocentric video privacy, prior work has largely overlooked the unique privacy threats posed to the camera wearer. This work investigates the core question: How much privacy information about the camera wearer can be inferred from their first-person view videos? We introduce EgoPrivacy, the first large-scale benchmark for the comprehensive evaluation of privacy risks in egocentric vision. EgoPrivacy covers three types of privacy (demographic, individual, and situational), defining seven tasks that aim to recover private information ranging from fine-grained (e.g., wearer's identity) to coarse-grained (e.g., age group). To further emphasize the privacy threats inherent to egocentric vision, we propose Retrieval-Augmented Attack, a novel attack strategy that leverages ego-to-exo retrieval from an external pool of exocentric videos to boost the effectiveness of demographic privacy attacks. An extensive comparison of the different attacks possible under all threat models is presented, showing that private information of the wearer is highly susceptible to leakage. For instance, our findings indicate that foundation models can effectively compromise wearer privacy even in zero-shot settings by recovering attributes such as identity, scene, gender, and race with 70-80% accuracy. Our code and data are available at https://github.com/williamium3000/ego-privacy.
Adapting Dual-encoder Vision-language Models for Paraphrased Retrieval
May 06, 2024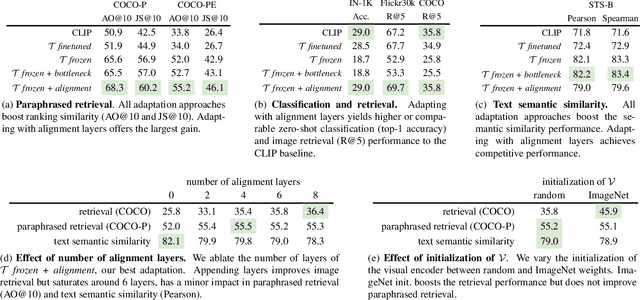
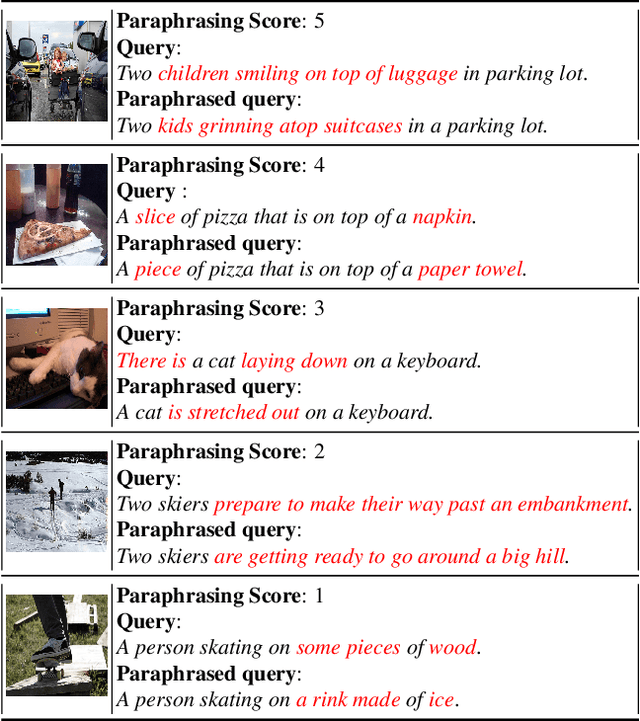
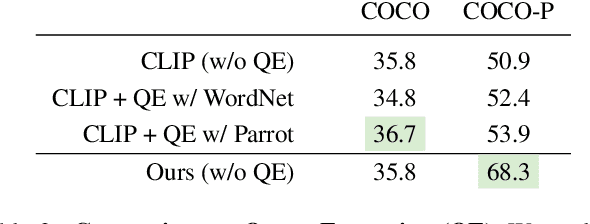
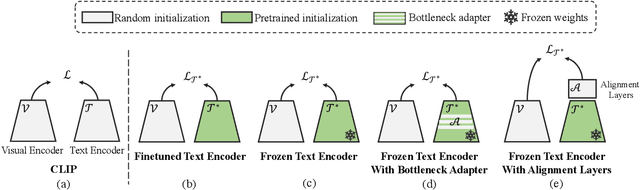
In the recent years, the dual-encoder vision-language models (\eg CLIP) have achieved remarkable text-to-image retrieval performance. However, we discover that these models usually results in very different retrievals for a pair of paraphrased queries. Such behavior might render the retrieval system less predictable and lead to user frustration. In this work, we consider the task of paraphrased text-to-image retrieval where a model aims to return similar results given a pair of paraphrased queries. To start with, we collect a dataset of paraphrased image descriptions to facilitate quantitative evaluation for this task. We then hypothesize that the undesired behavior of existing dual-encoder model is due to their text towers which are trained on image-sentence pairs and lack the ability to capture the semantic similarity between paraphrased queries. To improve on this, we investigate multiple strategies for training a dual-encoder model starting from a language model pretrained on a large text corpus. Compared to public dual-encoder models such as CLIP and OpenCLIP, the model trained with our best adaptation strategy achieves a significantly higher ranking similarity for paraphrased queries while maintaining similar zero-shot classification and retrieval accuracy.
Learning with Bounded Instance- and Label-dependent Label Noise
Sep 12, 2017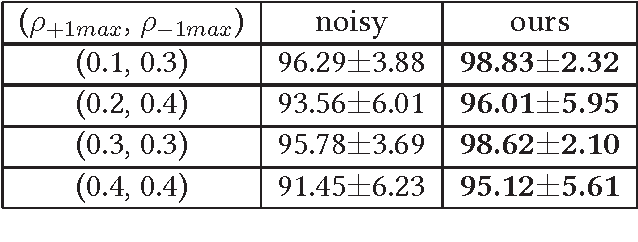
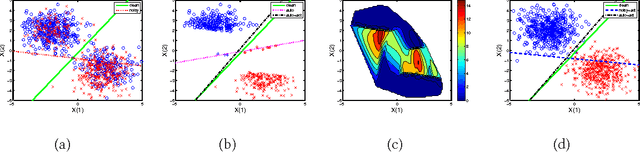
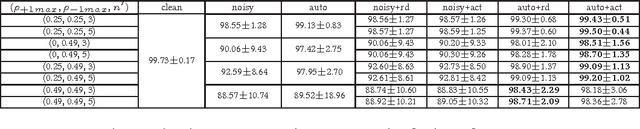
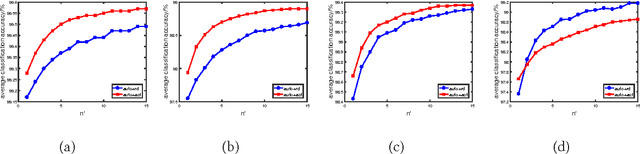
Instance- and label-dependent label noise (ILN) is widely existed in real-world datasets but has been rarely studied. In this paper, we focus on a particular case of ILN where the label noise rates, representing the probabilities that the true labels of examples flip into the corrupted labels, have upper bounds. We propose to handle this bounded instance- and label-dependent label noise under two different conditions. First, theoretically, we prove that when the marginal distributions $P(X|Y=+1)$ and $P(X|Y=-1)$ have non-overlapping supports, we can recover every noisy example's true label and perform supervised learning directly on the cleansed examples. Second, for the overlapping situation, we propose a novel approach to learn a well-performing classifier which needs only a few noisy examples to be labeled manually. Experimental results demonstrate that our method works well on both synthetic and real-world datasets.