 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoPrivacy: What Your First-Person Camera Says About You?
Jun 13, 2025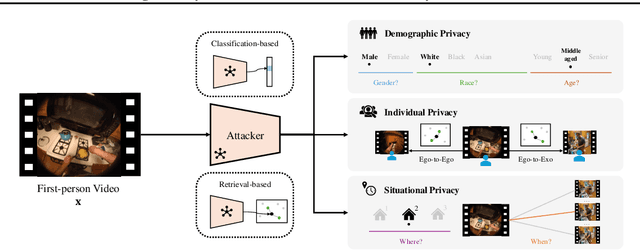
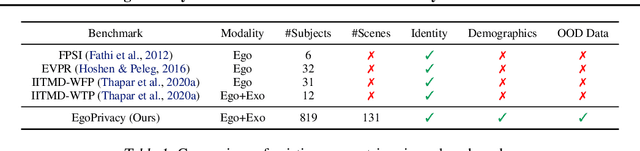
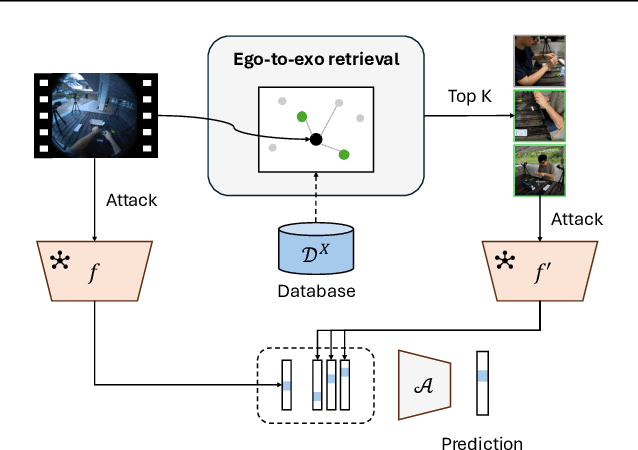
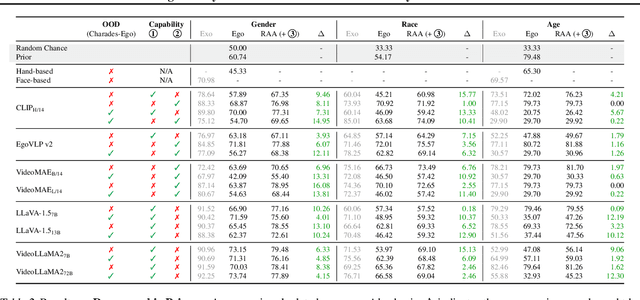
While the rapid proliferation of wearable cameras has raised significant concerns about egocentric video privacy, prior work has largely overlooked the unique privacy threats posed to the camera wearer. This work investigates the core question: How much privacy information about the camera wearer can be inferred from their first-person view videos? We introduce EgoPrivacy, the first large-scale benchmark for the comprehensive evaluation of privacy risks in egocentric vision. EgoPrivacy covers three types of privacy (demographic, individual, and situational), defining seven tasks that aim to recover private information ranging from fine-grained (e.g., wearer's identity) to coarse-grained (e.g., age group). To further emphasize the privacy threats inherent to egocentric vision, we propose Retrieval-Augmented Attack, a novel attack strategy that leverages ego-to-exo retrieval from an external pool of exocentric videos to boost the effectiveness of demographic privacy attacks. An extensive comparison of the different attacks possible under all threat models is presented, showing that private information of the wearer is highly susceptible to leakage. For instance, our findings indicate that foundation models can effectively compromise wearer privacy even in zero-shot settings by recovering attributes such as identity, scene, gender, and race with 70-80% accuracy. Our code and data are available at https://github.com/williamium3000/ego-privacy.
SEMA: a Scalable and Efficient Mamba like Attention via Token Localization and Averaging
Jun 10, 2025Attention is the critical component of a transformer. Yet the quadratic computational complexity of vanilla full attention in the input size and the inability of its linear attention variant to focus have been challenges for computer vision tasks. We provide a mathematical definition of generalized attention and formulate both vanilla softmax attention and linear attention within the general framework. We prove that generalized attention disperses, that is, as the number of keys tends to infinity, the query assigns equal weights to all keys. Motivated by the dispersion property and recent development of Mamba form of attention, we design Scalable and Efficient Mamba like Attention (SEMA) which utilizes token localization to avoid dispersion and maintain focusing, complemented by theoretically consistent arithmetic averaging to capture global aspect of attention. We support our approach on Imagenet-1k where classification results show that SEMA is a scalable and effective alternative beyond linear attention, outperforming recent vision Mamba models on increasingly larger scales of images at similar model parameter sizes.
AFIDAF: Alternating Fourier and Image Domain Adaptive Filters as an Efficient Alternative to Attention in ViTs
Jul 16, 2024We propose and demonstrate an alternating Fourier and image domain filtering approach for feature extraction as an efficient alternative to build a vision backbone without using the computationally intensive attention. The performance among the lightweight models reaches the state-of-the-art level on ImageNet-1K classification, and improves downstream tasks on object detection and segmentation consistently as well. Our approach also serves as a new tool to compress vision transformers (ViTs).
POP: Prompt Of Prompts for Continual Learning
Jun 14, 2023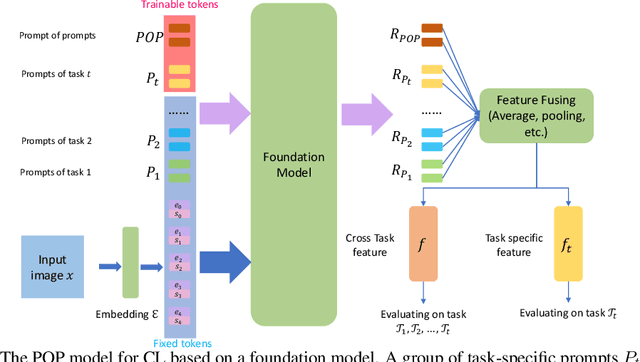
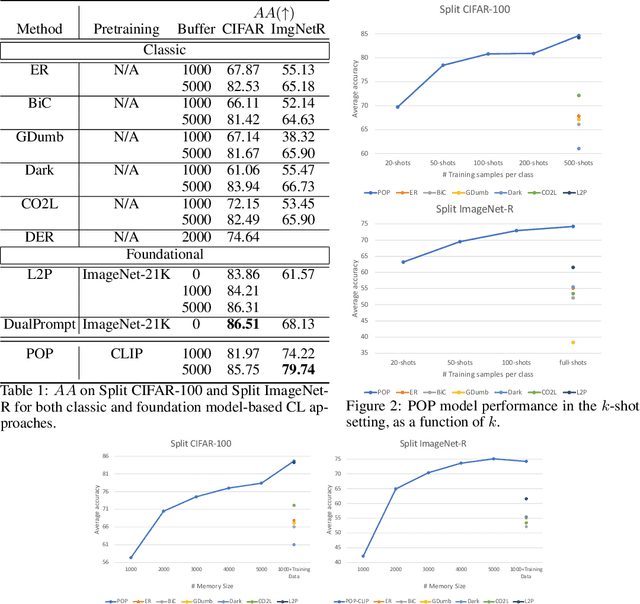
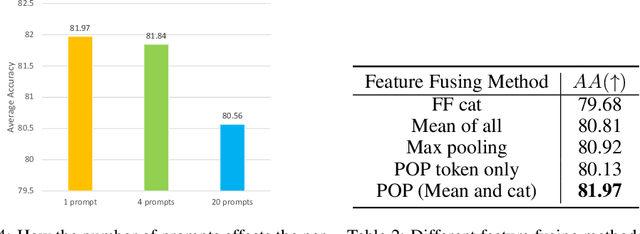
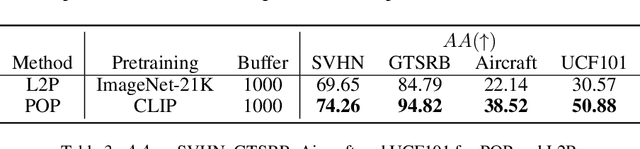
Continual learning (CL) has attracted increasing attention in the recent past. It aims to mimic the human ability to learn new concepts without catastrophic forgetting. While existing CL methods accomplish this to some extent, they are still prone to semantic drift of the learned feature space. Foundation models, which are endowed with a robust feature representation, learned from very large datasets, provide an interesting substrate for the solution of the CL problem. Recent work has also shown that they can be adapted to specific tasks by prompt tuning techniques that leave the generality of the representation mostly unscathed. An open question is, however, how to learn both prompts that are task specific and prompts that are global, i.e. capture cross-task information. In this work, we propose the Prompt Of Prompts (POP) model, which addresses this goal by progressively learning a group of task-specified prompts and a group of global prompts, denoted as POP, to integrate information from the former. We show that a foundation model equipped with POP learning is able to outperform classic CL methods by a significant margin. Moreover, as prompt tuning only requires a small set of training samples, POP is able to perform CL in the few-shot setting, while still outperforming competing methods trained on the entire dataset.
MobileInst: Video Instance Segmentation on the Mobile
Mar 30, 2023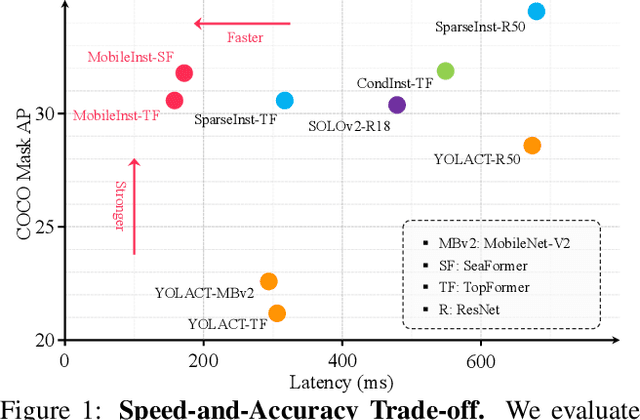
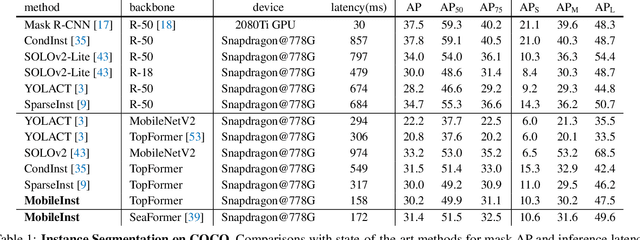

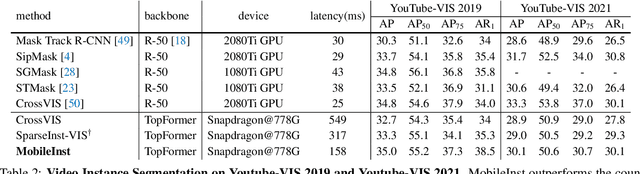
Although recent approaches aiming for video instance segmentation have achieved promising results, it is still difficult to employ those approaches for real-world applications on mobile devices, which mainly suffer from (1) heavy computation and memory cost and (2) complicated heuristics for tracking objects. To address those issues, we present MobileInst, a lightweight and mobile-friendly framework for video instance segmentation on mobile devices. Firstly, MobileInst adopts a mobile vision transformer to extract multi-level semantic features and presents an efficient query-based dual-transformer instance decoder for mask kernels and a semantic-enhanced mask decoder to generate instance segmentation per frame. Secondly, MobileInst exploits simple yet effective kernel reuse and kernel association to track objects for video instance segmentation. Further, we propose temporal query passing to enhance the tracking ability for kernels. We conduct experiments on COCO and YouTube-VIS datasets to demonstrate the superiority of MobileInst and evaluate the inference latency on a mobile CPU core of Qualcomm Snapdragon-778G, without other methods of acceleration. On the COCO dataset, MobileInst achieves 30.5 mask AP and 176 ms on the mobile CPU, which reduces the latency by 50% compared to the previous SOTA. For video instance segmentation, MobileInst achieves 35.0 AP on YouTube-VIS 2019 and 30.1 AP on YouTube-VIS 2021. Code will be available to facilitate real-world applications and future research.
Dense Network Expansion for Class Incremental Learning
Mar 22, 2023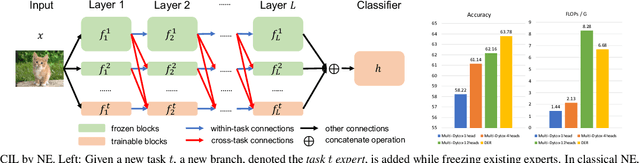
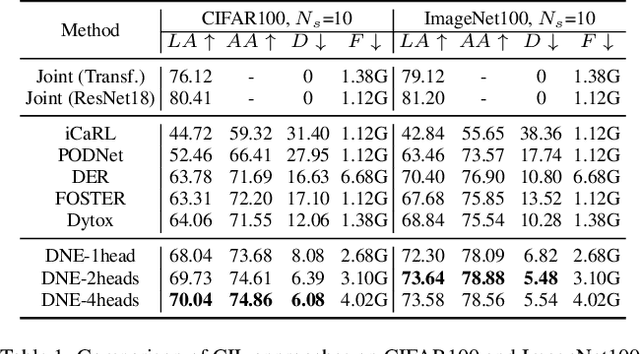
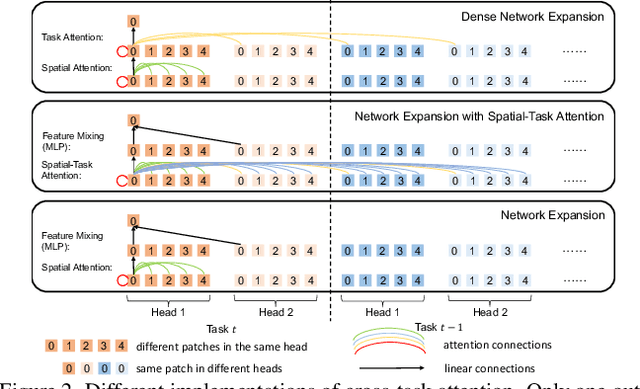
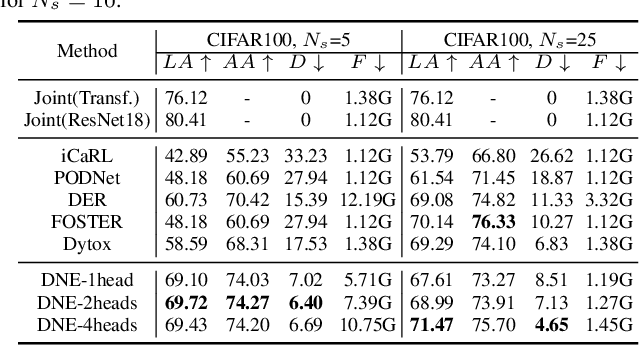
The problem of class incremental learning (CIL) is considered. State-of-the-art approaches use a dynamic architecture based on network expansion (NE), in which a task expert is added per task. While effective from a computational standpoint, these methods lead to models that grow quickly with the number of tasks. A new NE method, dense network expansion (DNE), is proposed to achieve a better trade-off between accuracy and model complexity. This is accomplished by the introduction of dense connections between the intermediate layers of the task expert networks, that enable the transfer of knowledge from old to new tasks via feature sharing and reusing. This sharing is implemented with a cross-task attention mechanism, based on a new task attention block (TAB), that fuses information across tasks. Unlike traditional attention mechanisms, TAB operates at the level of the feature mixing and is decoupled with spatial attentions. This is shown more effective than a joint spatial-and-task attention for CIL. The proposed DNE approach can strictly maintain the feature space of old classes while growing the network and feature scale at a much slower rate than previous methods. In result, it outperforms the previous SOTA methods by a margin of 4\% in terms of accuracy, with similar or even smaller model scale.
A Channel-Pruned and Weight-Binarized Convolutional Neural Network for Keyword Spotting
Sep 12, 2019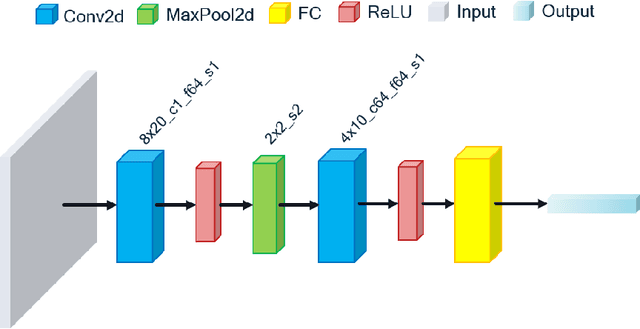
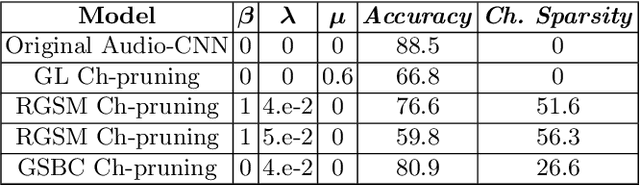
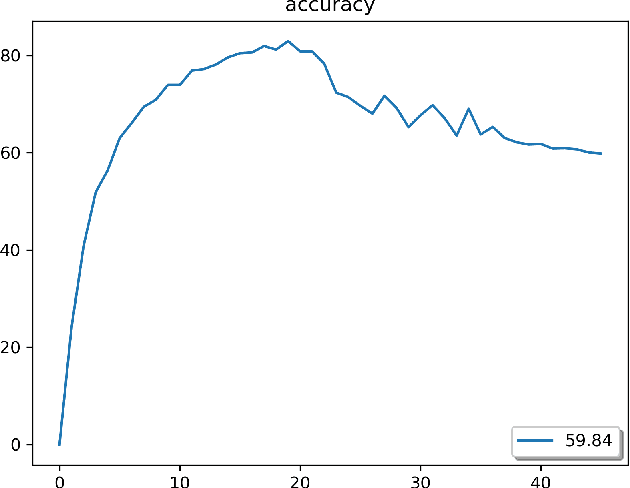

We study channel number reduction in combination with weight binarization (1-bit weight precision) to trim a convolutional neural network for a keyword spotting (classification) task. We adopt a group-wise splitting method based on the group Lasso penalty to achieve over 50% channel sparsity while maintaining the network performance within 0.25% accuracy loss. We show an effective three-stage procedure to balance accuracy and sparsity in network training.
Understanding Straight-Through Estimator in Training Activation Quantized Neural Nets
Mar 13, 2019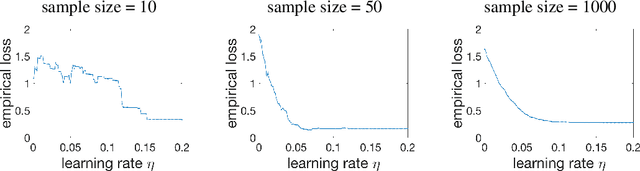


Training activation quantized neural networks involves minimizing a piecewise constant function whose gradient vanishes almost everywhere, which is undesirable for the standard back-propagation or chain rule. An empirical way around this issue is to use a straight-through estimator (STE) (Bengio et al., 2013) in the backward pass, so that the "gradient" through the modified chain rule becomes non-trivial. Since this unusual "gradient" is certainly not the gradient of loss function, the following question arises: why searching in its negative direction minimizes the training loss? In this paper, we provide the theoretical justification of the concept of STE by answering this question. We consider the problem of learning a two-linear-layer network with binarized ReLU activation and Gaussian input data. We shall refer to the unusual "gradient" given by the STE-modifed chain rule as coarse gradient. The choice of STE is not unique. We prove that if the STE is properly chosen, the expected coarse gradient correlates positively with the population gradient (not available for the training), and its negation is a descent direction for minimizing the population loss. We further show the associated coarse gradient descent algorithm converges to a critical point of the population loss minimization problem. Moreover, we show that a poor choice of STE leads to instability of the training algorithm near certain local minima, which is verified with CIFAR-10 experiments.
AutoShuffleNet: Learning Permutation Matrices via an Exact Lipschitz Continuous Penalty in Deep Convolutional Neural Networks
Jan 24, 2019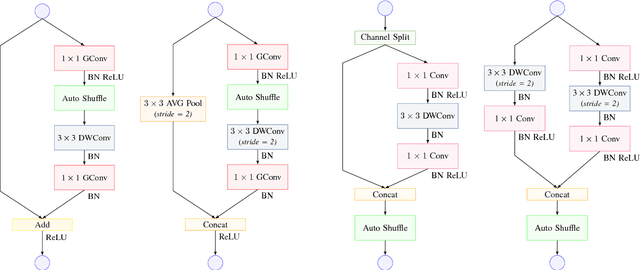
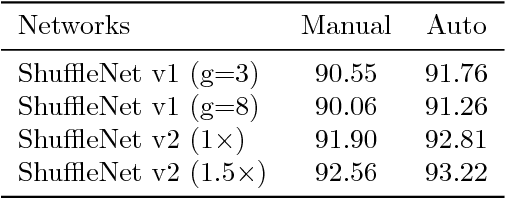

ShuffleNet is a state-of-the-art light weight convolutional neural network architecture. Its basic operations include group, channel-wise convolution and channel shuffling. However, channel shuffling is manually designed empirically. Mathematically, shuffling is a multiplication by a permutation matrix. In this paper, we propose to automate channel shuffling by learning permutation matrices in network training. We introduce an exact Lipschitz continuous non-convex penalty so that it can be incorporated in the stochastic gradient descent to approximate permutation at high precision. Exact permutations are obtained by simple rounding at the end of training and are used in inference. The resulting network, referred to as AutoShuffleNet, achieved improved classification accuracies on CIFAR-10 and ImageNet data sets. In addition, we found experimentally that the standard convex relaxation of permutation matrices into stochastic matrices leads to poor performance. We prove theoretically the exactness (error bounds) in recovering permutation matrices when our penalty function is zero (very small). We present examples of permutation optimization through graph matching and two-layer neural network models where the loss functions are calculated in closed analytical form. In the examples, convex relaxation failed to capture permutations whereas our penalty succeeded.
Median Binary-Connect Method and a Binary Convolutional Neural Nework for Word Recognition
Nov 07, 2018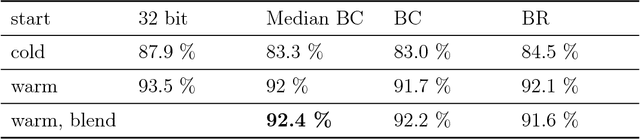
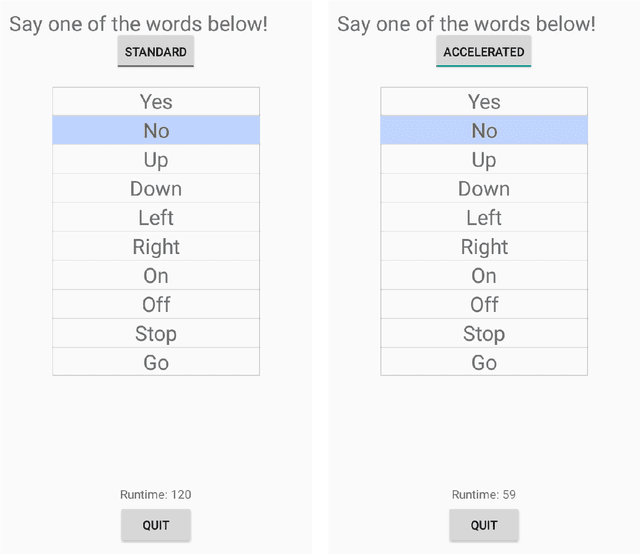
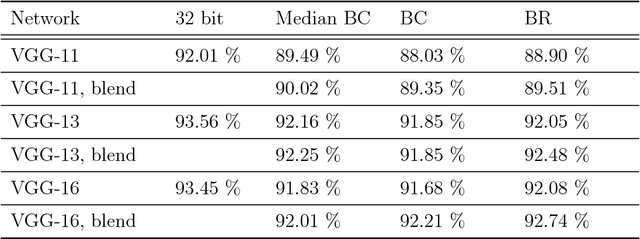
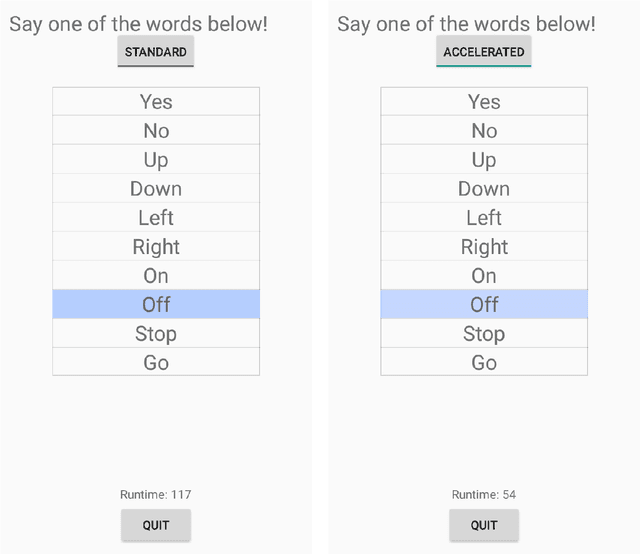
We propose and study a new projection formula for training binary weight convolutional neural networks. The projection formula measures the error in approximating a full precision (32 bit) vector by a 1-bit vector in the l_1 norm instead of the standard l_2 norm. The l_1 projector is in closed analytical form and involves a median computation instead of an arithmatic average in the l_2 projector. Experiments on 10 keywords classification show that the l_1 (median) BinaryConnect (BC) method outperforms the regular BC, regardless of cold or warm start. The binary network trained by median BC and a recent blending technique reaches test accuracy 92.4%, which is 1.1% lower than the full-precision network accuracy 93.5%. On Android phone app, the trained binary network doubles the speed of full-precision network in spoken keywords recognition.