 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEMA: a Scalable and Efficient Mamba like Attention via Token Localization and Averaging
Jun 10, 2025Attention is the critical component of a transformer. Yet the quadratic computational complexity of vanilla full attention in the input size and the inability of its linear attention variant to focus have been challenges for computer vision tasks. We provide a mathematical definition of generalized attention and formulate both vanilla softmax attention and linear attention within the general framework. We prove that generalized attention disperses, that is, as the number of keys tends to infinity, the query assigns equal weights to all keys. Motivated by the dispersion property and recent development of Mamba form of attention, we design Scalable and Efficient Mamba like Attention (SEMA) which utilizes token localization to avoid dispersion and maintain focusing, complemented by theoretically consistent arithmetic averaging to capture global aspect of attention. We support our approach on Imagenet-1k where classification results show that SEMA is a scalable and effective alternative beyond linear attention, outperforming recent vision Mamba models on increasingly larger scales of images at similar model parameter sizes.
AFIDAF: Alternating Fourier and Image Domain Adaptive Filters as an Efficient Alternative to Attention in ViTs
Jul 16, 2024We propose and demonstrate an alternating Fourier and image domain filtering approach for feature extraction as an efficient alternative to build a vision backbone without using the computationally intensive attention. The performance among the lightweight models reaches the state-of-the-art level on ImageNet-1K classification, and improves downstream tasks on object detection and segmentation consistently as well. Our approach also serves as a new tool to compress vision transformers (ViTs).
A Proximal Algorithm for Network Slimming
Jul 02, 2023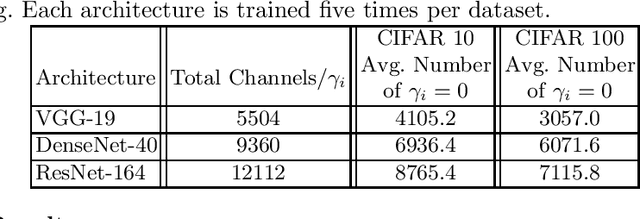

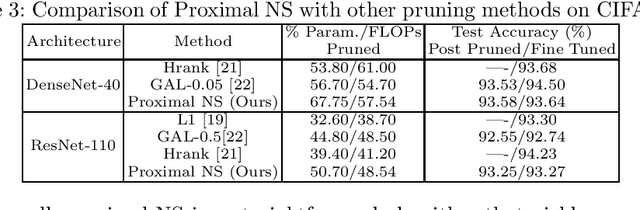
As a popular channel pruning method for convolutional neural networks (CNNs), network slimming (NS) has a three-stage process: (1) it trains a CNN with $\ell_1$ regularization applied to the scaling factors of the batch normalization layers; (2) it removes channels whose scaling factors are below a chosen threshold; and (3) it retrains the pruned model to recover the original accuracy. This time-consuming, three-step process is a result of using subgradient descent to train CNNs. Because subgradient descent does not exactly train CNNs towards sparse, accurate structures, the latter two steps are necessary. Moreover, subgradient descent does not have any convergence guarantee. Therefore, we develop an alternative algorithm called proximal NS. Our proposed algorithm trains CNNs towards sparse, accurate structures, so identifying a scaling factor threshold is unnecessary and fine tuning the pruned CNNs is optional. Using Kurdyka-{\L}ojasiewicz assumptions, we establish global convergence of proximal NS. Lastly, we validate the efficacy of the proposed algorithm on VGGNet, DenseNet and ResNet on CIFAR 10/100. Our experiments demonstrate that after one round of training, proximal NS yields a CNN with competitive accuracy and compression.
Searching Intrinsic Dimensions of Vision Transformers
Apr 16, 2022

It has been shown by many researchers that transformers perform as well as convolutional neural networks in many computer vision tasks. Meanwhile, the large computational costs of its attention module hinder further studies and applications on edge devices. Some pruning methods have been developed to construct efficient vision transformers, but most of them have considered image classification tasks only. Inspired by these results, we propose SiDT, a method for pruning vision transformer backbones on more complicated vision tasks like object detection, based on the search of transformer dimensions. Experiments on CIFAR-100 and COCO datasets show that the backbones with 20\% or 40\% dimensions/parameters pruned can have similar or even better performance than the unpruned models. Moreover, we have also provided the complexity analysis and comparisons with the previous pruning methods.
RARTS: a Relaxed Architecture Search Method
Aug 10, 2020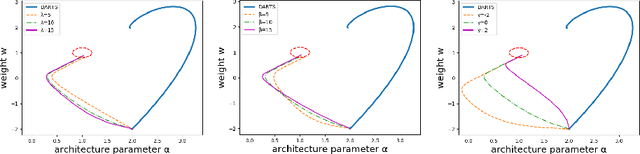
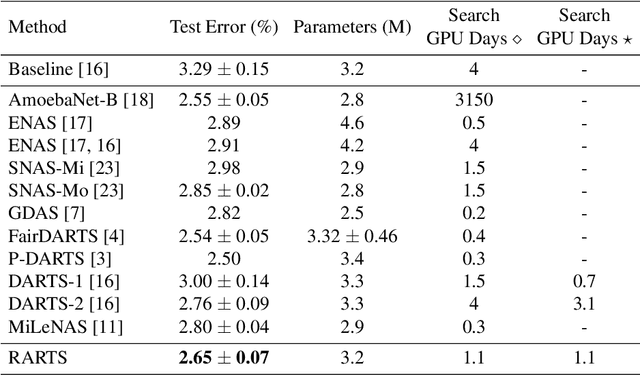


Differentiable architecture search (DARTS) is an effective method for data-driven neural network design based on solving a bilevel optimization problem. In this paper, we formulate a single level alternative and a relaxed architecture search (RARTS) method that utilizes training and validation datasets in architecture learning without involving mixed second derivatives of the corresponding loss functions. Through weight/architecture variable splitting and Gauss-Seidel iterations, the core algorithm outperforms DARTS significantly in accuracy and search efficiency, as shown in both a solvable model and CIFAR-10 based architecture search. Our model continues to out-perform DARTS upon transfer to ImageNet and is on par with recent variants of DARTS even though our innovation is purely on the training algorithm.
Learning Sparse Neural Networks via $\ell_0$ and T$\ell_1$ by a Relaxed Variable Splitting Method with Application to Multi-scale Curve Classification
Feb 20, 2019


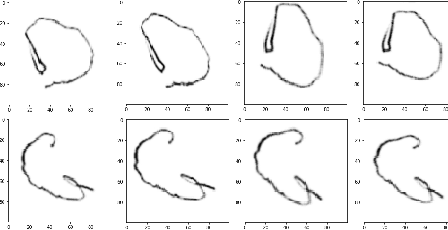
We study sparsification of convolutional neural networks (CNN) by a relaxed variable splitting method of $\ell_0$ and transformed-$\ell_1$ (T$\ell_1$) penalties, with application to complex curves such as texts written in different fonts, and words written with trembling hands simulating those of Parkinson's disease patients. The CNN contains 3 convolutional layers, each followed by a maximum pooling, and finally a fully connected layer which contains the largest number of network weights. With $\ell_0$ penalty, we achieved over 99 \% test accuracy in distinguishing shaky vs. regular fonts or hand writings with above 86 \% of the weights in the fully connected layer being zero. Comparable sparsity and test accuracy are also reached with a proper choice of T$\ell_1$ penalty.