 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneReason Technical Report
Jun 04, 2026Generative recommendation models in the OneRec family have been widely deployed in many real-world services, such as short-video, live-streaming, advertising, and e-commerce. However, these generative models can only benefit from the scaling advantage, while their reasoning ability is hard to activate, since we cannot construct meaningful Chain-of-Thought (CoT) sequences consisting of itemic tokens only. Inspired by the success of the reasoning-style ``think before answer'' paradigm in the LLM field, we conduct preliminary studies (i.e., OneRec-Think, OpenOneRec) to explore reasoning capability in generative recommendation. Nevertheless, we notice an unexpected phenomenon: the thinking mode does not show advantages over the non-thinking mode. Drawing insights from recent findings on CoT robustness in multi-modal language models, we argue that effective reasoning in recommendation rests on two factors: perception, the ability to ground itemic tokens in their underlying language semantics, and cognition, the ability to reorganize a user's behavior sequence into coherent latent interest points. We therefore propose OneReason, which includes: (1) strong itemic token perception in pre-training, (2) a three-level cognition-enhanced CoT format for recommendation tasks in SFT, and (3) a specialize-then-unify training recipe in RL to enhance the thinking ability.
CREM: Compression-Driven Representation Enhancement for Multimodal Retrieval and Comprehension
Feb 22, 2026Multimodal Large Language Models (MLLMs) have shown remarkable success in comprehension tasks such as visual description and visual question answering. However, their direct application to embedding-based tasks like retrieval remains challenging due to the discrepancy between output formats and optimization objectives. Previous approaches often employ contrastive fine-tuning to adapt MLLMs for retrieval, but at the cost of losing their generative capabilities. We argue that both generative and embedding tasks fundamentally rely on shared cognitive mechanisms, specifically cross-modal representation alignment and contextual comprehension. To this end, we propose CREM (Compression-driven Representation Enhanced Model), with a unified framework that enhances multimodal representations for retrieval while preserving generative ability. Specifically, we introduce a compression-based prompt design with learnable chorus tokens to aggregate multimodal semantics and a compression-driven training strategy that integrates contrastive and generative objectives through compression-aware attention. Extensive experiments demonstrate that CREM achieves state-of-the-art retrieval performance on MMEB while maintaining strong generative performance on multiple comprehension benchmarks. Our findings highlight that generative supervision can further improve the representational quality of MLLMs under the proposed compression-driven paradigm.
Compression then Matching: An Efficient Pre-training Paradigm for Multimodal Embedding
Nov 11, 2025Vision-language models advance multimodal representation learning by acquiring transferable semantic embeddings, thereby substantially enhancing performance across a range of vision-language tasks, including cross-modal retrieval, clustering, and classification. An effective embedding is expected to comprehensively preserve the semantic content of the input while simultaneously emphasizing features that are discriminative for downstream tasks. Recent approaches demonstrate that VLMs can be adapted into competitive embedding models via large-scale contrastive learning, enabling the simultaneous optimization of two complementary objectives. We argue that the two aforementioned objectives can be decoupled: a comprehensive understanding of the input facilitates the embedding model in achieving superior performance in downstream tasks via contrastive learning. In this paper, we propose CoMa, a compressed pre-training phase, which serves as a warm-up stage for contrastive learning. Experiments demonstrate that with only a small amount of pre-training data, we can transform a VLM into a competitive embedding model. CoMa achieves new state-of-the-art results among VLMs of comparable size on the MMEB, realizing optimization in both efficiency and effectiveness.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
AttentionDrag: Exploiting Latent Correlation Knowledge in Pre-trained Diffusion Models for Image Editing
Jun 16, 2025



Traditional point-based image editing methods rely on iterative latent optimization or geometric transformations, which are either inefficient in their processing or fail to capture the semantic relationships within the image. These methods often overlook the powerful yet underutilized image editing capabilities inherent in pre-trained diffusion models. In this work, we propose a novel one-step point-based image editing method, named AttentionDrag, which leverages the inherent latent knowledge and feature correlations within pre-trained diffusion models for image editing tasks. This framework enables semantic consistency and high-quality manipulation without the need for extensive re-optimization or retraining. Specifically, we reutilize the latent correlations knowledge learned by the self-attention mechanism in the U-Net module during the DDIM inversion process to automatically identify and adjust relevant image regions, ensuring semantic validity and consistency. Additionally, AttentionDrag adaptively generates masks to guide the editing process, enabling precise and context-aware modifications with friendly interaction. Our results demonstrate a performance that surpasses most state-of-the-art methods with significantly faster speeds, showing a more efficient and semantically coherent solution for point-based image editing tasks.
A 2D Semantic-Aware Position Encoding for Vision Transformers
May 14, 2025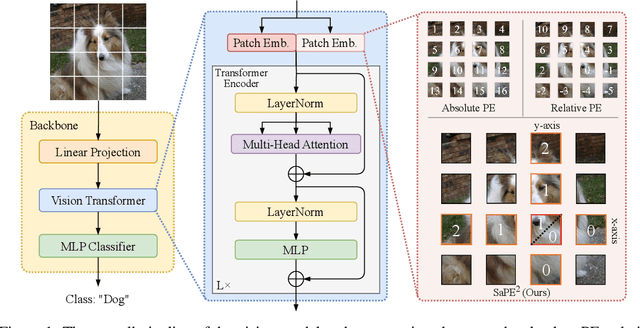
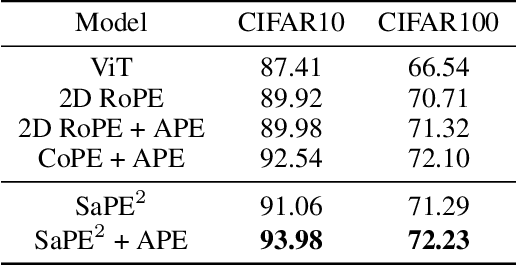
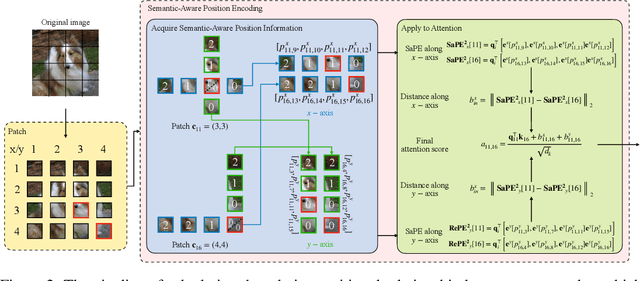
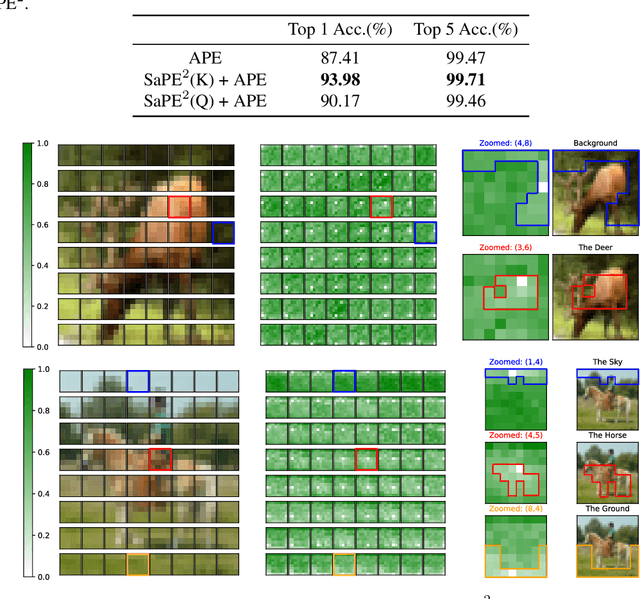
Vision transformers have demonstrated significant advantages in computer vision tasks due to their ability to capture long-range dependencies and contextual relationships through self-attention. However, existing position encoding techniques, which are largely borrowed from natural language processing, fail to effectively capture semantic-aware positional relationships between image patches. Traditional approaches like absolute position encoding and relative position encoding primarily focus on 1D linear position relationship, often neglecting the semantic similarity between distant yet contextually related patches. These limitations hinder model generalization, translation equivariance, and the ability to effectively handle repetitive or structured patterns in images. In this paper, we propose 2-Dimensional Semantic-Aware Position Encoding ($\text{SaPE}^2$), a novel position encoding method with semantic awareness that dynamically adapts position representations by leveraging local content instead of fixed linear position relationship or spatial coordinates. Our method enhances the model's ability to generalize across varying image resolutions and scales, improves translation equivariance, and better aggregates features for visually similar but spatially distant patches. By integrating $\text{SaPE}^2$ into vision transformers, we bridge the gap between position encoding and perceptual similarity, thereby improving performance on computer vision tasks.
OCRBench v2: An Improved Benchmark for Evaluating Large Multimodal Models on Visual Text Localization and Reasoning
Dec 31, 2024



Scoring the Optical Character Recognition (OCR) capabilities of Large Multimodal Models (LMMs) has witnessed growing interest recently. Existing benchmarks have highlighted the impressive performance of LMMs in text recognition; however, their abilities on certain challenging tasks, such as text localization, handwritten content extraction, and logical reasoning, remain underexplored. To bridge this gap, we introduce OCRBench v2, a large-scale bilingual text-centric benchmark with currently the most comprehensive set of tasks (4x more tasks than the previous multi-scene benchmark OCRBench), the widest coverage of scenarios (31 diverse scenarios including street scene, receipt, formula, diagram, and so on), and thorough evaluation metrics, with a total of 10,000 human-verified question-answering pairs and a high proportion of difficult samples. After carefully benchmarking state-of-the-art LMMs on OCRBench v2, we find that 20 out of 22 LMMs score below 50 (100 in total) and suffer from five-type limitations, including less frequently encountered text recognition, fine-grained perception, layout perception, complex element parsing, and logical reasoning. The benchmark and evaluation scripts are available at https://github.com/Yuliang-liu/MultimodalOCR.
AFIDAF: Alternating Fourier and Image Domain Adaptive Filters as an Efficient Alternative to Attention in ViTs
Jul 16, 2024We propose and demonstrate an alternating Fourier and image domain filtering approach for feature extraction as an efficient alternative to build a vision backbone without using the computationally intensive attention. The performance among the lightweight models reaches the state-of-the-art level on ImageNet-1K classification, and improves downstream tasks on object detection and segmentation consistently as well. Our approach also serves as a new tool to compress vision transformers (ViTs).
Exploring the Capabilities of Large Multimodal Models on Dense Text
May 09, 2024



While large multi-modal models (LMM) have shown notable progress in multi-modal tasks, their capabilities in tasks involving dense textual content remains to be fully explored. Dense text, which carries important information, is often found in documents, tables, and product descriptions. Understanding dense text enables us to obtain more accurate information, assisting in making better decisions. To further explore the capabilities of LMM in complex text tasks, we propose the DT-VQA dataset, with 170k question-answer pairs. In this paper, we conduct a comprehensive evaluation of GPT4V, Gemini, and various open-source LMMs on our dataset, revealing their strengths and weaknesses. Furthermore, we evaluate the effectiveness of two strategies for LMM: prompt engineering and downstream fine-tuning. We find that even with automatically labeled training datasets, significant improvements in model performance can be achieved. We hope that this research will promote the study of LMM in dense text tasks. Code will be released at https://github.com/Yuliang-Liu/MultimodalOCR.
TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document
Mar 15, 2024We present TextMonkey, a large multimodal model (LMM) tailored for text-centric tasks. Our approach introduces enhancement across several dimensions: By adopting Shifted Window Attention with zero-initialization, we achieve cross-window connectivity at higher input resolutions and stabilize early training; We hypothesize that images may contain redundant tokens, and by using similarity to filter out significant tokens, we can not only streamline the token length but also enhance the model's performance. Moreover, by expanding our model's capabilities to encompass text spotting and grounding, and incorporating positional information into responses, we enhance interpretability. It also learns to perform screenshot tasks through finetuning. Evaluation on 12 benchmarks shows notable improvements: 5.2% in Scene Text-Centric tasks (including STVQA, TextVQA, and OCRVQA), 6.9% in Document-Oriented tasks (such as DocVQA, InfoVQA, ChartVQA, DeepForm, Kleister Charity, and WikiTableQuestions), and 2.8% in Key Information Extraction tasks (comprising FUNSD, SROIE, and POIE). It outperforms in scene text spotting with a 10.9\% increase and sets a new standard on OCRBench, a comprehensive benchmark consisting of 29 OCR-related assessments, with a score of 561, surpassing previous open-sourced large multimodal models for document understanding. Code will be released at https://github.com/Yuliang-Liu/Monkey.