 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHABD: a houma alliance book ancient handwritten character recognition database
Aug 26, 2024



The Houma Alliance Book, one of history's earliest calligraphic examples, was unearthed in the 1970s. These artifacts were meticulously organized, reproduced, and copied by the Shanxi Provincial Institute of Cultural Relics. However, because of their ancient origins and severe ink erosion, identifying characters in the Houma Alliance Book is challenging, necessitating the use of digital technology. In this paper, we propose a new ancient handwritten character recognition database for the Houma alliance book, along with a novel benchmark based on deep learning architectures. More specifically, a collection of 26,732 characters samples from the Houma Alliance Book were gathered, encompassing 327 different types of ancient characters through iterative annotation. Furthermore, benchmark algorithms were proposed by combining four deep neural network classifiers with two data augmentation methods. This research provides valuable resources and technical support for further studies on the Houma Alliance Book and other ancient characters. This contributes to our understanding of ancient culture and history, as well as the preservation and inheritance of humanity's cultural heritage.
Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models
Nov 24, 2023



Large Multimodal Models (LMMs) have shown promise in vision-language tasks but struggle with high-resolution input and detailed scene understanding. Addressing these challenges, we introduce Monkey to enhance LMM capabilities. Firstly, Monkey processes input images by dividing them into uniform patches, each matching the size (e.g., 448x448) used in the original training of the well-trained vision encoder. Equipped with individual adapter for each patch, Monkey can handle higher resolutions up to 1344x896 pixels, enabling the detailed capture of complex visual information. Secondly, it employs a multi-level description generation method, enriching the context for scene-object associations. This two-part strategy ensures more effective learning from generated data: the higher resolution allows for a more detailed capture of visuals, which in turn enhances the effectiveness of comprehensive descriptions. Extensive ablative results validate the effectiveness of our designs. Additionally, experiments on 18 datasets further demonstrate that Monkey surpasses existing LMMs in many tasks like Image Captioning and various Visual Question Answering formats. Specially, in qualitative tests focused on dense text question answering, Monkey has exhibited encouraging results compared with GPT4V. Code is available at https://github.com/Yuliang-Liu/Monkey.
A new database of Houma Alliance Book ancient handwritten characters and its baseline algorithm
Jul 17, 2022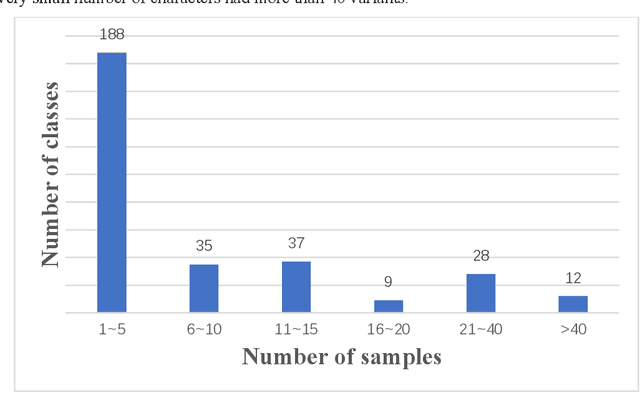

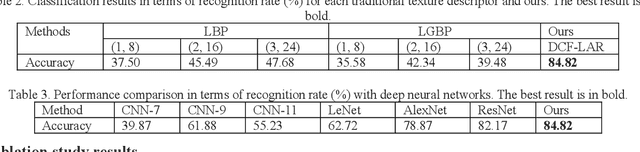

The Houma Alliance Book is one of the national treasures of the Museum in Shanxi Museum Town in China. It has great historical significance in researching ancient history. To date, the research on the Houma Alliance Book has been staying in the identification of paper documents, which is inefficient to identify and difficult to display, study and publicize. Therefore, the digitization of the recognized ancient characters of Houma League can effectively improve the efficiency of recognizing ancient characters and provide more reliable technical support and text data. This paper proposes a new database of Houma Alliance Book ancient handwritten characters and a multi-modal fusion method to recognize ancient handwritten characters. In the database, 297 classes and 3,547 samples of Houma Alliance ancient handwritten characters are collected from the original book collection and by human imitative writing. Furthermore, the decision-level classifier fusion strategy is applied to fuse three well-known deep neural network architectures for ancient handwritten character recognition. Experiments are performed on our new database. The experimental results first provide the baseline result of the new database to the research community and then demonstrate the efficiency of our proposed method.