 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentionDrag: Exploiting Latent Correlation Knowledge in Pre-trained Diffusion Models for Image Editing
Jun 16, 2025



Traditional point-based image editing methods rely on iterative latent optimization or geometric transformations, which are either inefficient in their processing or fail to capture the semantic relationships within the image. These methods often overlook the powerful yet underutilized image editing capabilities inherent in pre-trained diffusion models. In this work, we propose a novel one-step point-based image editing method, named AttentionDrag, which leverages the inherent latent knowledge and feature correlations within pre-trained diffusion models for image editing tasks. This framework enables semantic consistency and high-quality manipulation without the need for extensive re-optimization or retraining. Specifically, we reutilize the latent correlations knowledge learned by the self-attention mechanism in the U-Net module during the DDIM inversion process to automatically identify and adjust relevant image regions, ensuring semantic validity and consistency. Additionally, AttentionDrag adaptively generates masks to guide the editing process, enabling precise and context-aware modifications with friendly interaction. Our results demonstrate a performance that surpasses most state-of-the-art methods with significantly faster speeds, showing a more efficient and semantically coherent solution for point-based image editing tasks.
A 2D Semantic-Aware Position Encoding for Vision Transformers
May 14, 2025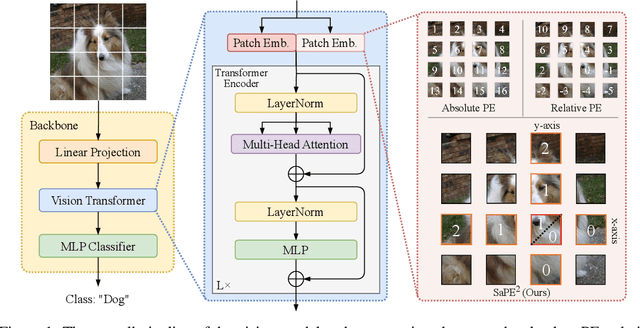
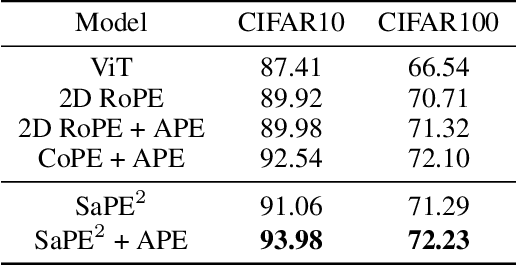
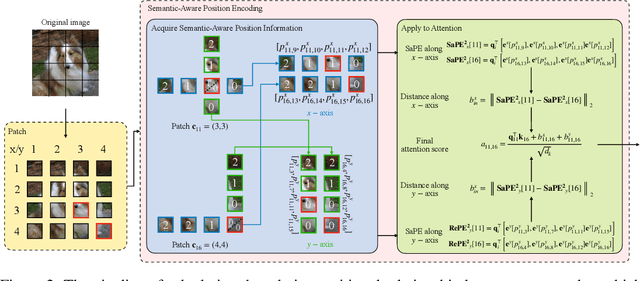
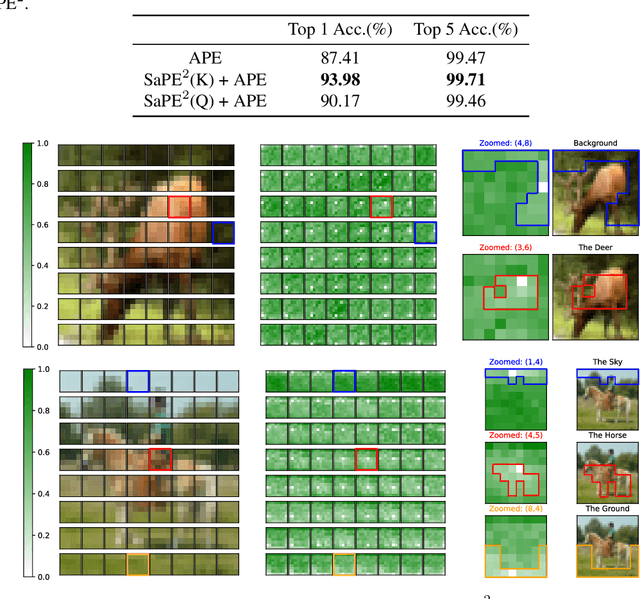
Vision transformers have demonstrated significant advantages in computer vision tasks due to their ability to capture long-range dependencies and contextual relationships through self-attention. However, existing position encoding techniques, which are largely borrowed from natural language processing, fail to effectively capture semantic-aware positional relationships between image patches. Traditional approaches like absolute position encoding and relative position encoding primarily focus on 1D linear position relationship, often neglecting the semantic similarity between distant yet contextually related patches. These limitations hinder model generalization, translation equivariance, and the ability to effectively handle repetitive or structured patterns in images. In this paper, we propose 2-Dimensional Semantic-Aware Position Encoding ($\text{SaPE}^2$), a novel position encoding method with semantic awareness that dynamically adapts position representations by leveraging local content instead of fixed linear position relationship or spatial coordinates. Our method enhances the model's ability to generalize across varying image resolutions and scales, improves translation equivariance, and better aggregates features for visually similar but spatially distant patches. By integrating $\text{SaPE}^2$ into vision transformers, we bridge the gap between position encoding and perceptual similarity, thereby improving performance on computer vision tasks.
Binarized Mamba-Transformer for Lightweight Quad Bayer HybridEVS Demosaicing
Mar 20, 2025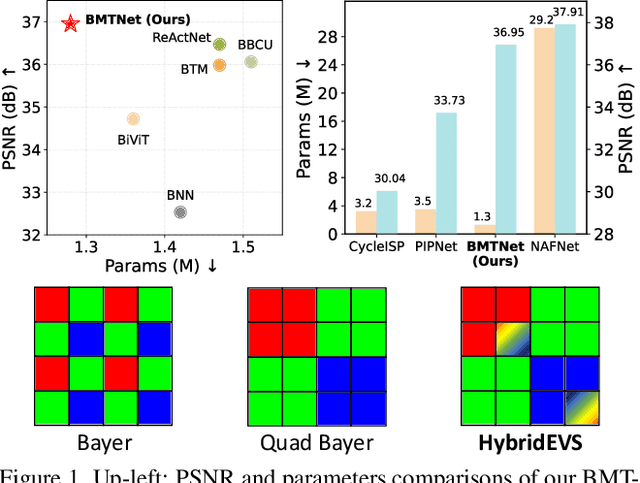
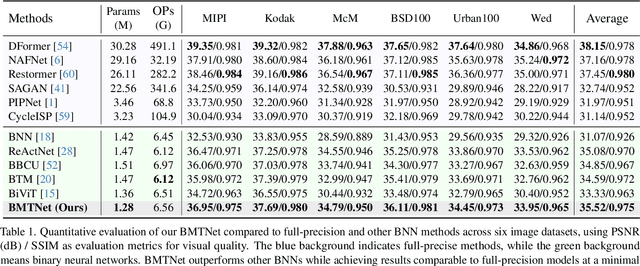
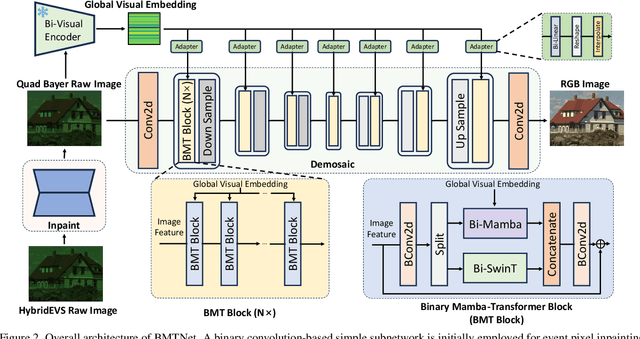
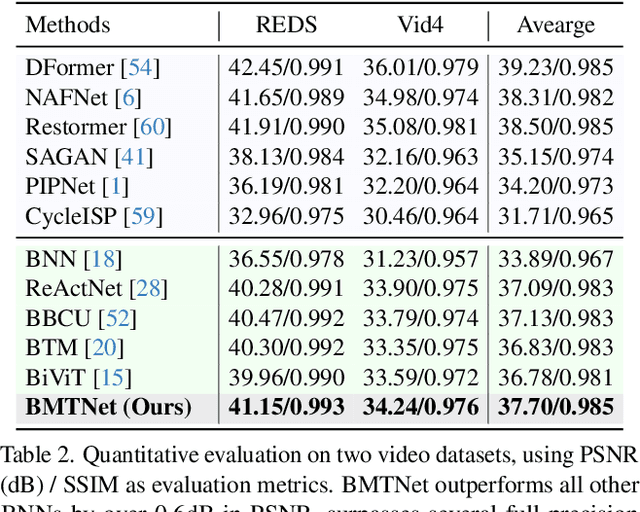
Quad Bayer demosaicing is the central challenge for enabling the widespread application of Hybrid Event-based Vision Sensors (HybridEVS). Although existing learning-based methods that leverage long-range dependency modeling have achieved promising results, their complexity severely limits deployment on mobile devices for real-world applications. To address these limitations, we propose a lightweight Mamba-based binary neural network designed for efficient and high-performing demosaicing of HybridEVS RAW images. First, to effectively capture both global and local dependencies, we introduce a hybrid Binarized Mamba-Transformer architecture that combines the strengths of the Mamba and Swin Transformer architectures. Next, to significantly reduce computational complexity, we propose a binarized Mamba (Bi-Mamba), which binarizes all projections while retaining the core Selective Scan in full precision. Bi-Mamba also incorporates additional global visual information to enhance global context and mitigate precision loss. We conduct quantitative and qualitative experiments to demonstrate the effectiveness of BMTNet in both performance and computational efficiency, providing a lightweight demosaicing solution suited for real-world edge devices. Our codes and models are available at https://github.com/Clausy9/BMTNet.
DTFormer: A Transformer-Based Method for Discrete-Time Dynamic Graph Representation Learning
Jul 26, 2024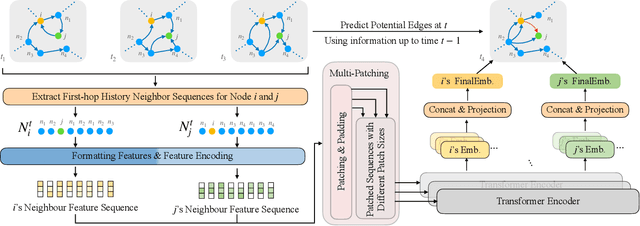
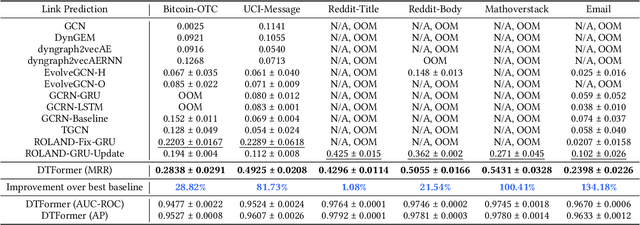
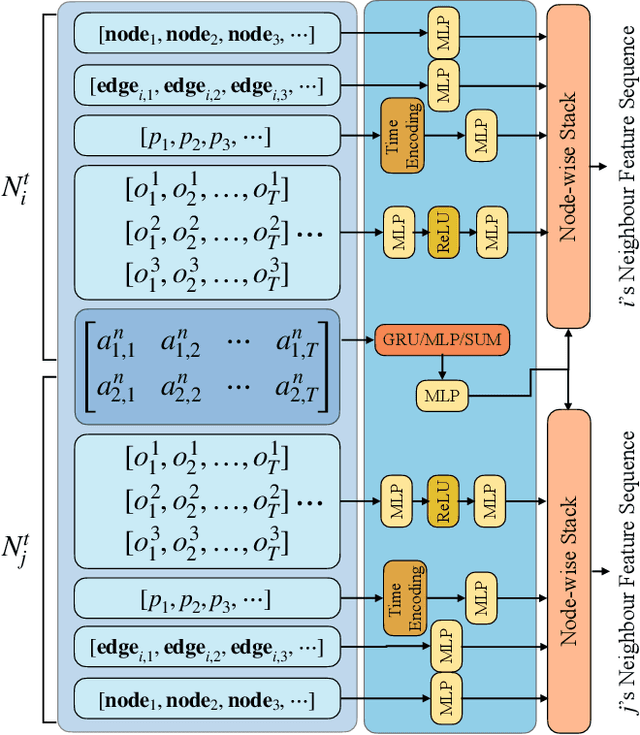
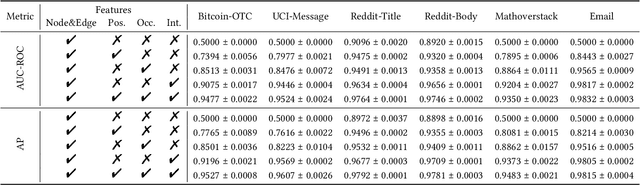
Discrete-Time Dynamic Graphs (DTDGs), which are prevalent in real-world implementations and notable for their ease of data acquisition, have garnered considerable attention from both academic researchers and industry practitioners. The representation learning of DTDGs has been extensively applied to model the dynamics of temporally changing entities and their evolving connections. Currently, DTDG representation learning predominantly relies on GNN+RNN architectures, which manifest the inherent limitations of both Graph Neural Networks (GNNs) and Recurrent Neural Networks (RNNs). GNNs suffer from the over-smoothing issue as the models architecture goes deeper, while RNNs struggle to capture long-term dependencies effectively. GNN+RNN architectures also grapple with scaling to large graph sizes and long sequences. Additionally, these methods often compute node representations separately and focus solely on individual node characteristics, thereby overlooking the behavior intersections between the two nodes whose link is being predicted, such as instances where the two nodes appear together in the same context or share common neighbors. This paper introduces a novel representation learning method DTFormer for DTDGs, pivoting from the traditional GNN+RNN framework to a Transformer-based architecture. Our approach exploits the attention mechanism to concurrently process topological information within the graph at each timestamp and temporal dynamics of graphs along the timestamps, circumventing the aforementioned fundamental weakness of both GNNs and RNNs. Moreover, we enhance the model's expressive capability by incorporating the intersection relationships among nodes and integrating a multi-patching module. Extensive experiments conducted on six public dynamic graph benchmark datasets confirm our model's efficacy, achieving the SOTA performance.
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024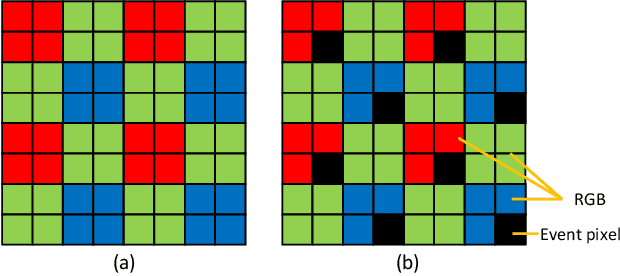
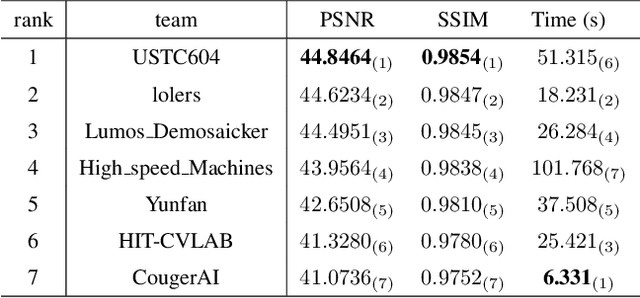
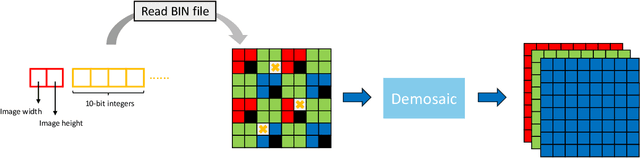

The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.