 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Distribution-assisted Evolutionary Dynamic Optimization as an Online Calibrator for Complex Social Simulations
Jan 27, 2026The calibration of simulators for complex social systems aims to identify the optimal parameter that drives the output of the simulator best matching the target data observed from the system. As many social systems may change internally over time, calibration naturally becomes an online task, requiring parameters to be updated continuously to maintain the simulator's fidelity. In this work, the online setting is first formulated as a dynamic optimization problem (DOP), requiring the search for a sequence of optimal parameters that fit the simulator to real system changes. However, in contrast to traditional DOP formulations, online calibration explicitly incorporates the observational data as the driver of environmental dynamics. Due to this fundamental difference, existing Evolutionary Dynamic Optimization (EDO) methods, despite being extensively studied for black-box DOPs, are ill-equipped to handle such a scenario. As a result, online calibration problems constitute a new set of challenging DOPs. Here, we propose to explicitly learn the posterior distributions of the parameters and the observational data, thereby facilitating both change detection and environmental adaptation of existing EDOs for this scenario. We thus present a pretrained posterior model for implementation, and fine-tune it during the optimization. Extensive tests on both economic and financial simulators verify that the posterior distribution strongly promotes EDOs in such DOPs widely existed in social science.
Integrating Knowledge Distillation Methods: A Sequential Multi-Stage Framework
Jan 22, 2026Knowledge distillation (KD) transfers knowledge from large teacher models to compact student models, enabling efficient deployment on resource constrained devices. While diverse KD methods, including response based, feature based, and relation based approaches, capture different aspects of teacher knowledge, integrating multiple methods or knowledge sources is promising but often hampered by complex implementation, inflexible combinations, and catastrophic forgetting, which limits practical effectiveness. This work proposes SMSKD (Sequential Multi Stage Knowledge Distillation), a flexible framework that sequentially integrates heterogeneous KD methods. At each stage, the student is trained with a specific distillation method, while a frozen reference model from the previous stage anchors learned knowledge to mitigate forgetting. In addition, we introduce an adaptive weighting mechanism based on the teacher true class probability (TCP) that dynamically adjusts the reference loss per sample to balance knowledge retention and integration. By design, SMSKD supports arbitrary method combinations and stage counts with negligible computational overhead. Extensive experiments show that SMSKD consistently improves student accuracy across diverse teacher student architectures and method combinations, outperforming existing baselines. Ablation studies confirm that stage wise distillation and reference model supervision are primary contributors to performance gains, with TCP based adaptive weighting providing complementary benefits. Overall, SMSKD is a practical and resource efficient solution for integrating heterogeneous KD methods.
Evolutionary Reinforcement Learning based AI tutor for Socratic Interdisciplinary Instruction
Dec 12, 2025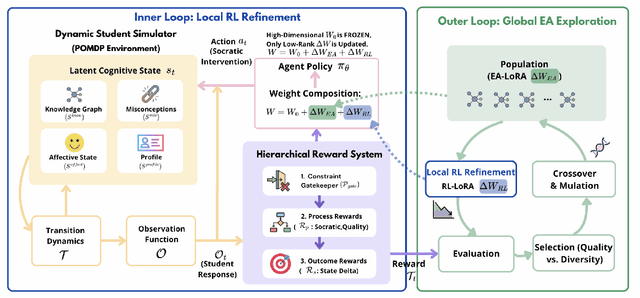


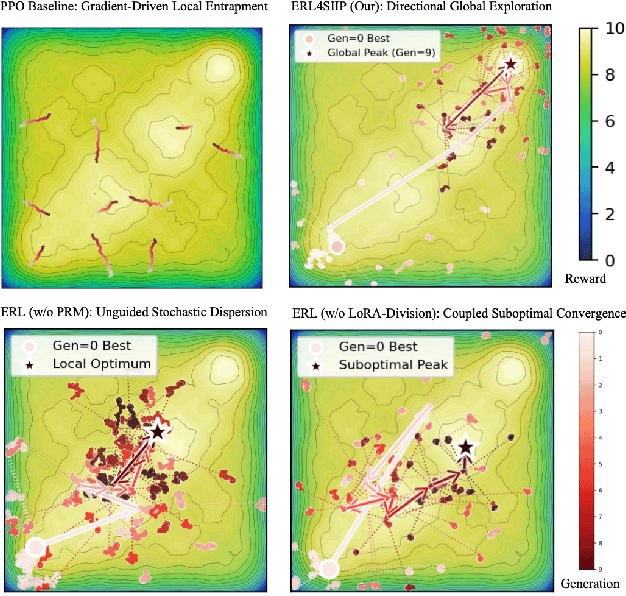
Cultivating higher-order cognitive abilities -- such as knowledge integration, critical thinking, and creativity -- in modern STEM education necessitates a pedagogical shift from passive knowledge transmission to active Socratic construction. Although Large Language Models (LLMs) hold promise for STEM Interdisciplinary education, current methodologies employing Prompt Engineering (PE), Supervised Fine-tuning (SFT), or standard Reinforcement Learning (RL) often fall short of supporting this paradigm. Existing methods are hindered by three fundamental challenges: the inability to dynamically model latent student cognitive states; severe reward sparsity and delay inherent in long-term educational goals; and a tendency toward policy collapse lacking strategic diversity due to reliance on behavioral cloning. Recognizing the unobservability and dynamic complexity of these interactions, we formalize the Socratic Interdisciplinary Instructional Problem (SIIP) as a structured Partially Observable Markov Decision Process (POMDP), demanding simultaneous global exploration and fine-grained policy refinement. To this end, we propose ERL4SIIP, a novel Evolutionary Reinforcement Learning (ERL) framework specifically tailored for this domain. ERL4SIIP integrates: (1) a dynamic student simulator grounded in a STEM knowledge graph for latent state modeling; (2) a Hierarchical Reward Mechanism that decomposes long-horizon goals into dense signals; and (3) a LoRA-Division based optimization strategy coupling evolutionary algorithms for population-level global search with PPO for local gradient ascent.
Surrogate-Assisted Evolutionary Reinforcement Learning Based on Autoencoder and Hyperbolic Neural Network
May 26, 2025Evolutionary Reinforcement Learning (ERL), training the Reinforcement Learning (RL) policies with Evolutionary Algorithms (EAs), have demonstrated enhanced exploration capabilities and greater robustness than using traditional policy gradient. However, ERL suffers from the high computational costs and low search efficiency, as EAs require evaluating numerous candidate policies with expensive simulations, many of which are ineffective and do not contribute meaningfully to the training. One intuitive way to reduce the ineffective evaluations is to adopt the surrogates. Unfortunately, existing ERL policies are often modeled as deep neural networks (DNNs) and thus naturally represented as high-dimensional vectors containing millions of weights, which makes the building of effective surrogates for ERL policies extremely challenging. This paper proposes a novel surrogate-assisted ERL that integrates Autoencoders (AE) and Hyperbolic Neural Networks (HNN). Specifically, AE compresses high-dimensional policies into low-dimensional representations while extracting key features as the inputs for the surrogate. HNN, functioning as a classification-based surrogate model, can learn complex nonlinear relationships from sampled data and enable more accurate pre-selection of the sampled policies without real evaluations. The experiments on 10 Atari and 4 Mujoco games have verified that the proposed method outperforms previous approaches significantly. The search trajectories guided by AE and HNN are also visually demonstrated to be more effective, in terms of both exploration and convergence. This paper not only presents the first learnable policy embedding and surrogate-modeling modules for high-dimensional ERL policies, but also empirically reveals when and why they can be successful.
Safe Delta: Consistently Preserving Safety when Fine-Tuning LLMs on Diverse Datasets
May 17, 2025Large language models (LLMs) have shown great potential as general-purpose AI assistants across various domains. To fully leverage this potential in specific applications, many companies provide fine-tuning API services, enabling users to upload their own data for LLM customization. However, fine-tuning services introduce a new safety threat: user-uploaded data, whether harmful or benign, can break the model's alignment, leading to unsafe outputs. Moreover, existing defense methods struggle to address the diversity of fine-tuning datasets (e.g., varying sizes, tasks), often sacrificing utility for safety or vice versa. To address this issue, we propose Safe Delta, a safety-aware post-training defense method that adjusts the delta parameters (i.e., the parameter change before and after fine-tuning). Specifically, Safe Delta estimates the safety degradation, selects delta parameters to maximize utility while limiting overall safety loss, and applies a safety compensation vector to mitigate residual safety loss. Through extensive experiments on four diverse datasets with varying settings, our approach consistently preserves safety while ensuring that the utility gain from benign datasets remains unaffected.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
SemDiff: Generating Natural Unrestricted Adversarial Examples via Semantic Attributes Optimization in Diffusion Models
Apr 16, 2025Unrestricted adversarial examples (UAEs), allow the attacker to create non-constrained adversarial examples without given clean samples, posing a severe threat to the safety of deep learning models. Recent works utilize diffusion models to generate UAEs. However, these UAEs often lack naturalness and imperceptibility due to simply optimizing in intermediate latent noises. In light of this, we propose SemDiff, a novel unrestricted adversarial attack that explores the semantic latent space of diffusion models for meaningful attributes, and devises a multi-attributes optimization approach to ensure attack success while maintaining the naturalness and imperceptibility of generated UAEs. We perform extensive experiments on four tasks on three high-resolution datasets, including CelebA-HQ, AFHQ and ImageNet. The results demonstrate that SemDiff outperforms state-of-the-art methods in terms of attack success rate and imperceptibility. The generated UAEs are natural and exhibit semantically meaningful changes, in accord with the attributes' weights. In addition, SemDiff is found capable of evading different defenses, which further validates its effectiveness and threatening.
Memetic Search for Green Vehicle Routing Problem with Private Capacitated Refueling Stations
Apr 06, 2025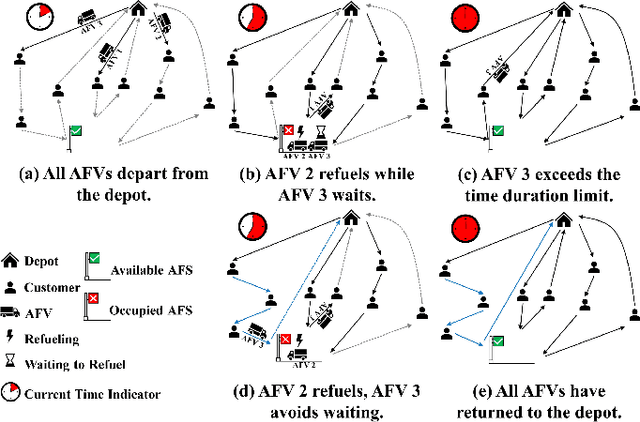
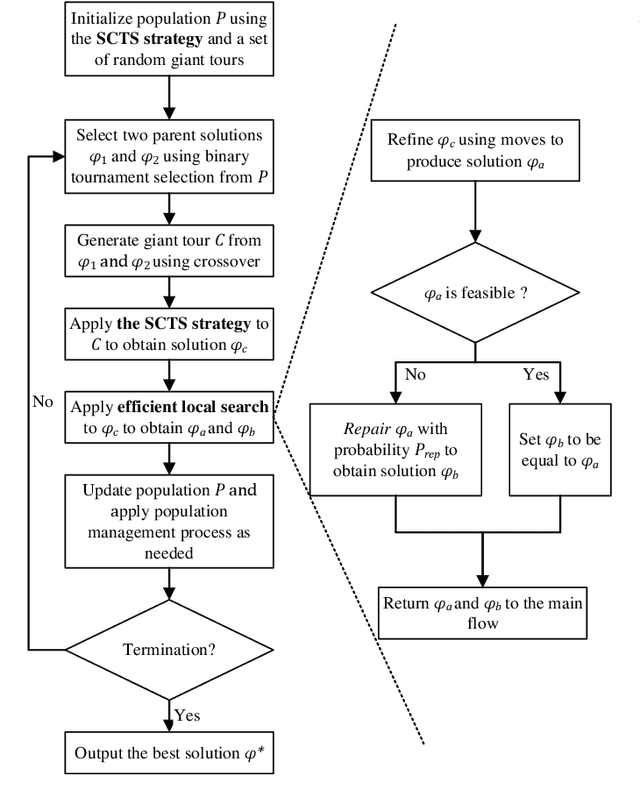
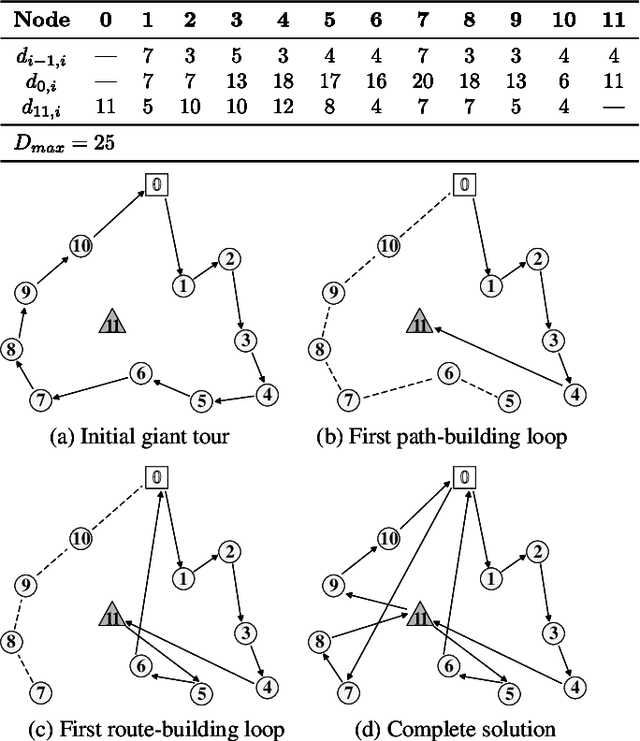
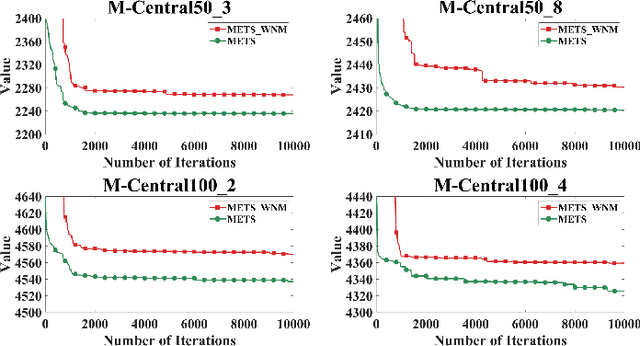
The green vehicle routing problem with private capacitated alternative fuel stations (GVRP-PCAFS) extends the traditional green vehicle routing problem by considering refueling stations limited capacity, where a limited number of vehicles can refuel simultaneously with additional vehicles must wait. This feature presents new challenges for route planning, as waiting times at stations must be managed while keeping route durations within limits and reducing total travel distance. This article presents METS, a novel memetic algorithm (MA) with separate constraint-based tour segmentation (SCTS) and efficient local search (ELS) for solving GVRP-PCAFS. METS combines global and local search effectively through three novelties. For global search, the SCTS strategy splits giant tours to generate diverse solutions, and the search process is guided by a comprehensive fitness evaluation function to dynamically control feasibility and diversity to produce solutions that are both diverse and near-feasible. For local search, ELS incorporates tailored move operators with constant-time move evaluation mechanisms, enabling efficient exploration of large solution neighborhoods. Experimental results demonstrate that METS discovers 31 new best-known solutions out of 40 instances in existing benchmark sets, achieving substantial improvements over current state-of-the-art methods. Additionally, a new large-scale benchmark set based on real-world logistics data is introduced to facilitate future research.
SchemaAgent: A Multi-Agents Framework for Generating Relational Database Schema
Mar 31, 2025The relational database design would output a schema based on user's requirements, which defines table structures and their interrelated relations. Translating requirements into accurate schema involves several non-trivial subtasks demanding both database expertise and domain-specific knowledge. This poses unique challenges for automated design of relational databases. Existing efforts are mostly based on customized rules or conventional deep learning models, often producing suboptimal schema. Recently, large language models (LLMs) have significantly advanced intelligent application development across various domains. In this paper, we propose SchemaAgent, a unified LLM-based multi-agent framework for the automated generation of high-quality database schema. SchemaAgent is the first to apply LLMs for schema generation, which emulates the workflow of manual schema design by assigning specialized roles to agents and enabling effective collaboration to refine their respective subtasks. Schema generation is a streamlined workflow, where directly applying the multi-agent framework may cause compounding impact of errors. To address this, we incorporate dedicated roles for reflection and inspection, alongside an innovative error detection and correction mechanism to identify and rectify issues across various phases. For evaluation, we present a benchmark named \textit{RSchema}, which contains more than 500 pairs of requirement description and schema. Experimental results on this benchmark demonstrate the superiority of our approach over mainstream LLMs for relational database schema generation.
Binarized Mamba-Transformer for Lightweight Quad Bayer HybridEVS Demosaicing
Mar 20, 2025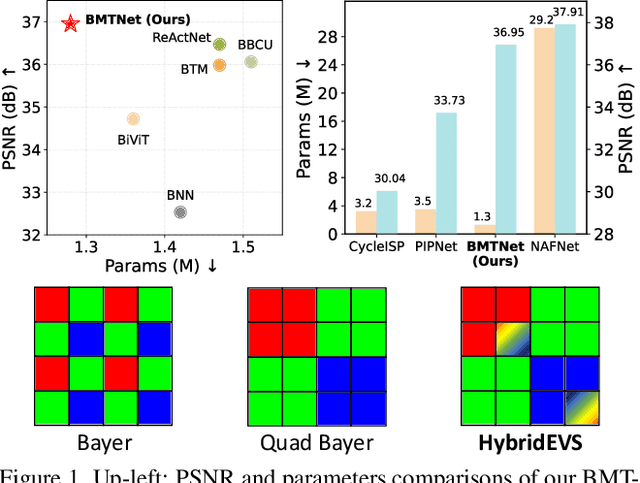
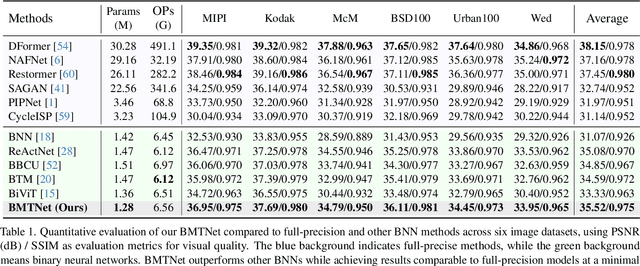
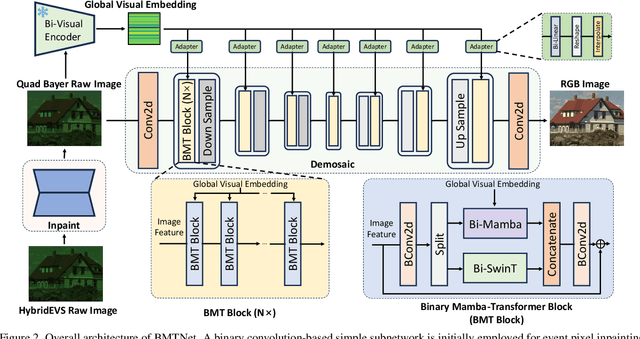
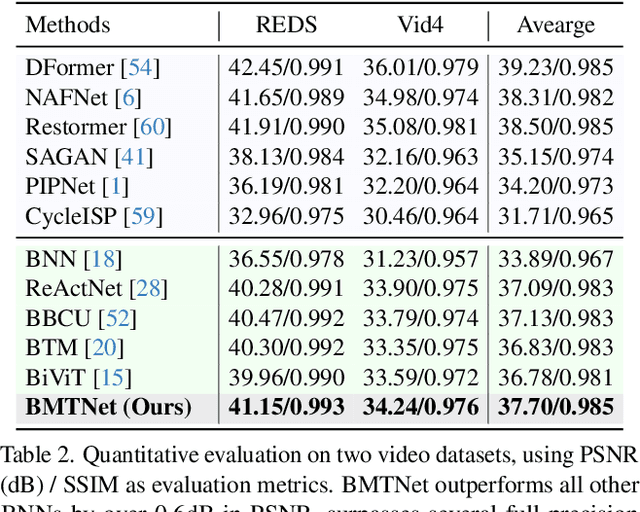
Quad Bayer demosaicing is the central challenge for enabling the widespread application of Hybrid Event-based Vision Sensors (HybridEVS). Although existing learning-based methods that leverage long-range dependency modeling have achieved promising results, their complexity severely limits deployment on mobile devices for real-world applications. To address these limitations, we propose a lightweight Mamba-based binary neural network designed for efficient and high-performing demosaicing of HybridEVS RAW images. First, to effectively capture both global and local dependencies, we introduce a hybrid Binarized Mamba-Transformer architecture that combines the strengths of the Mamba and Swin Transformer architectures. Next, to significantly reduce computational complexity, we propose a binarized Mamba (Bi-Mamba), which binarizes all projections while retaining the core Selective Scan in full precision. Bi-Mamba also incorporates additional global visual information to enhance global context and mitigate precision loss. We conduct quantitative and qualitative experiments to demonstrate the effectiveness of BMTNet in both performance and computational efficiency, providing a lightweight demosaicing solution suited for real-world edge devices. Our codes and models are available at https://github.com/Clausy9/BMTNet.